nulová hypotéza je přesné tvrzení o populaci, které se snažíme odmítnout s ukázkovými daty.Obvykle nevěříme, že naše nulová hypotéza (nebo H0) je pravdivá. Potřebujeme však nějaké přesné prohlášení jako výchozí bod pro testování statistické významnosti.
Nulovou Hypotézu Příklady
Často -ale ne vždy – nulovou hypotézu státy neexistuje žádná souvislost nebo rozdíl mezi proměnnými nebo subpopulací., Jako tak, některé typické nulové hypotézy jsou:
- vztah mezi frustrací a agresí je nulová (korelační analýza);
- průměrný příjem pro muže je podobný pro ženy (independent samples t-test);
- státní Příslušnost je (dokonale) nesouvisí s hudební preference (chí-kvadrát test nezávislosti);
- průměr populace příjmů byl ve výši více než 2012 až 2016 (opakovaná měření ANOVA).
“ Null „neznamená“nula „
běžným nedorozuměním je, že“ null „znamená“nula“. To je často, ale ne vždy případ., Například, nulová hypotéza se také může stát, že korelace mezi frustrace a agrese je 0,5.Žádné zde jedná, a -i když poněkud neobvyklé – dokonale platný.
„null“ v „nulové hypotézy“ je odvozen od „zrušit“5: nulová hypotéza je tvrzení, které se snažíme vyvrátit, bez ohledu na to, zda to (ne) určete nulový efekt.
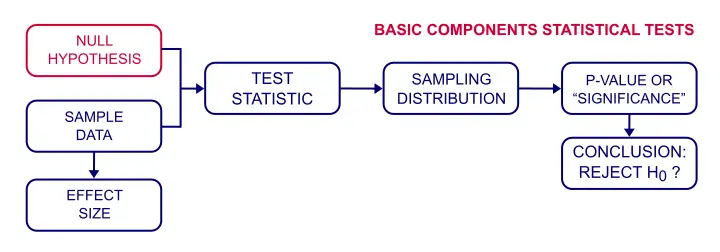
nulové testování hypotéz – jak to funguje?
chci vědět, zda štěstí souvisí s bohatstvím mezi Nizozemci. Jedním z přístupů, jak to zjistit, je formulovat nulovou hypotézu., Vzhledem k tomu, že „příbuzný“ není přesný, volíme opačné tvrzení jako naši nulovou hypotézu:korelace mezi bohatstvím a štěstím je nulová u všech Nizozemců.Nyní se pokusíme tuto hypotézu vyvrátit, abychom prokázali, že štěstí a bohatství jsou v pořádku.
nyní se nemůžeme rozumně zeptat všech 17 142 066 Nizozemců, jak šťastní se obecně cítí.

takže se zeptáme vzorku (řekněme 100 lidí) o jejich bohatství a jejich štěstí. Korelace mezi štěstím a bohatstvím je v našem vzorku 0, 25., Nyní máme jeden problém: výsledky vzorků se poněkud liší od výsledků populace. Takže pokud je korelace v naší populaci skutečně nulová, můžeme v našem vzorku najít nenulovou korelaci. Pro ilustraci tohoto důležitého bodu se podívejte na scatterplot níže. Vizualizuje nulovou korelaci mezi štěstím a bohatstvím pro celou populaci N = 200.

nyní z této populace nakreslíme náhodný vzorek N = 20 (červené tečky v našem předchozím scatterplotu). I když je naše populační korelace nulová, našli jsme ohromující 0.,82 korelace v našem vzorku. Níže uvedený obrázek to ilustruje vynecháním všech jednotek bez vzorku z našeho předchozího scatterplotu.

To vyvolává otázku, jak můžeme někdy něco o naší populace, pokud máme jen malý vzorek. Základní odpověď: s jistotou 100% můžeme jen zřídka říci cokoli. Můžeme však říci hodně s 99%, 95% nebo 90% jistotou.
Pravděpodobnost
tak jak to funguje? No, v podstatě, některé výsledky vzorku jsou velmi nepravděpodobné vzhledem k naší nulové hypotéze., Jako tak, níže uvedený obrázek ukazuje pravděpodobnosti pro různé korelace vzorků (N = 100), pokud je populační korelace skutečně nulová.

počítač tyto pravděpodobnosti snadno vypočítá. To však vyžaduje velikost vzorku (v našem případě 100) a předpokládanou populační korelaci ρ (0 v našem případě). Proto potřebujeme nulovou hypotézu.
Pokud se podíváme na tento odběr vzorků distribuce pozorně, vidíme, že vzorek korelace kolem 0 jsou s největší pravděpodobností: 0.68 pravděpodobnost nalezení korelace mezi -0.1 a 0.1. Co to znamená?, Nezapomeňte, že pravděpodobnosti lze považovat za relativní frekvence. Představte si, že bychom nakreslili 1000 vzorků místo těch, které máme. Výsledkem by bylo 1000 korelačních koeficientů a přibližně 680 z nich-relativní frekvence 0,68-by bylo v rozmezí -0,1 až 0,1. Stejně tak existuje 0,95 (nebo 95%) pravděpodobnost nalezení korelace vzorku mezi -0,2 a 0,2.
hodnoty P
našli jsme korelaci vzorku 0,25. Jak je pravděpodobné, že pokud je korelace populace nulová?, Odpověď je známá jako hodnota p (zkratka pro hodnotu pravděpodobnosti): hodnota p je pravděpodobnost nalezení nějakého výsledku vzorku nebo extrémnějšího, pokud je pravdivá nulová hypotéza.Vzhledem k naší korelaci 0.25 znamená „extrémnější“ obvykle větší než 0.25 nebo menší než -0.25. Z našeho grafu to nepoznáme, ale základní tabulka nám říká, že p ≈ 0.012. Pokud je nulová hypotéza pravdivá, je 1,2% pravděpodobnost nalezení naší korelace vzorků.
závěr?
Pokud je naše populační korelace skutečně nulová, můžeme najít vzorkovou korelaci 0, 25 ve vzorku N = 100., Pravděpodobnost, že se to stane, je pouze 0,012, takže je to velmi nepravděpodobné. Rozumným závěrem je, že naše populační korelace nakonec nebyla nulová.
závěr: odmítáme nulovou hypotézu. Vzhledem k našemu vzorovému výsledku již nevěříme, že štěstí a bohatství nesouvisí. Stále to však nemůžeme s jistotou říci.
nulová hypotéza-omezení
zatím jsme pouze dospěli k závěru, že populační korelace pravděpodobně není nulová. To je jediný závěr z našeho přístupu nulové hypotézy a není to tak zajímavé.,
to, co opravdu chceme vědět, je korelace populace. Naše vzorová korelace 0.25 se zdá být rozumným odhadem. Takové jediné číslo nazýváme bodovým odhadem.
nyní může nový vzorek přijít s jinou korelací. Zajímavou otázkou je, kolik by naše korelace vzorků kolísala nad vzorky, kdybychom jich nakreslili mnoho. Níže uvedený obrázek přesně ukazuje, že za předpokladu naší velikosti vzorku N = 100 a našeho (bodového) odhadu 0, 25 pro populační korelaci.,

Intervaly Spolehlivosti
Náš ukázkový výsledek naznačuje, že přibližně 95% mnoho vzorků by měla přijít s korelace mezi 0.06 a 0,43. Tento rozsah je známý jako interval spolehlivosti. Ačkoli to není přesně správné, je to nejsnadnější, i když jako šířka pásma, která pravděpodobně uzavře populační korelaci.
jedna věc, kterou je třeba poznamenat, je, že interval spolehlivosti je poměrně široký. Téměř obsahuje nulovou korelaci, přesně nulovou hypotézu, kterou jsme dříve odmítli.,
Další věc, kterou je třeba poznamenat, je, že naše rozdělení vzorků a interval spolehlivosti jsou mírně asymetrické. Jsou symetrické pro většinu ostatních statistik (jako jsou prostředky nebo beta koeficienty), ale ne korelace.