Přehled
- Precision a recall jsou dva zásadní dosud nepochopených témat v strojového učení
- Budeme diskutovat o tom, co precision a recall jsou, jak fungují, a jejich roli při hodnocení model strojového učení
- Budeme také získat pochopení Plochy Pod Křivkou (AUC) a Přesnost pojmů
Úvod
Zeptejte se jakéhokoliv strojového učení profesionální nebo datový vědec asi nejvíce matoucí pojmy v jejich učení cesty., A Odpověď vždy směřuje k přesnosti a odvolání.
rozdíl mezi přesností a vyvoláním je ve skutečnosti snadno zapamatovatelný – ale pouze jednou jste skutečně pochopili, co znamená Každý termín. Ale poměrně často, a to mohu potvrdit, odborníci mají tendenci nabízet polopečené vysvětlení, která zaměňují nováčky ještě více.
takže pojďme nastavit záznam přímo v tomto článku.

pro jakýkoli model strojového učení víme, že dosažení „dobrého přizpůsobení“ modelu je nesmírně důležité., To zahrnuje dosažení rovnováhy mezi underfitting a overfitting, nebo jinými slovy, kompromis mezi bias a rozptyl.
Nicméně, pokud jde o klasifikaci – existuje další kompromis, který je často přehlížen ve prospěch zkreslení-rozptylu tradeoff. Jedná se o tradeoff precision-recall. Nevyvážené třídy se vyskytují běžně v datových souborech, a když přijde na konkrétní případy užití, bychom ve skutečnosti chtěli dát větší důraz na přesnost a připomeňme si, metriky, a také jak dosáhnout rovnováhy mezi nimi.
ale jak to udělat?, Budeme zkoumat metriky hodnocení klasifikace zaměřením na přesnost a odvolání v tomto článku. Naučíme se také, Jak vypočítat tyto metriky v Pythonu tím, že vezmeme datový soubor a jednoduchý klasifikační algoritmus. Tak, pojďme začít!
podrobné informace o metrikách hodnocení naleznete zde-metriky hodnocení pro modely strojového učení.
obsah
- pochopení problému
- co je přesnost?
- co je to odvolání?,
- Nejjednodušší Hodnocení Metrické – Přesnost
- Role F1-Skóre
- Slavné Precision-Recall Kompromis
- Pochopení Plochy Pod Křivkou (AUC)
Pochopení Problému Prohlášení
pevně věřím v učení tím, že dělá. Takže v tomto článku budeme hovořit prakticky-pomocí datové sady.
pojďme se podívat na populární datový soubor srdečních chorob, který je k dispozici v úložišti UCI. Zde musíme předpovědět, zda pacient trpí srdečním onemocněním nebo nepoužívá danou sadu funkcí., Čistý datový soubor si můžete stáhnout zde.
vzhledem k tomu, že se tento článek zaměřuje výhradně na metriky hodnocení modelů, použijeme pro předpovědi nejjednodušší klasifikátor – klasifikační model kNN.
Jako vždy, musíme začít tím, že import potřebných knihoven a balíčků:
Pak se pojďme podívat na data a cílové proměnné zabýváme se:
Nechte nás zkontrolovat, jestli máme chybějící hodnoty:
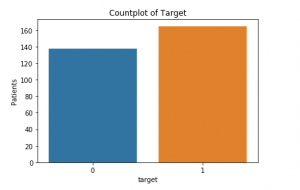
nejsou žádné chybějící hodnoty., Nyní se můžeme podívat na to, jak mnoho pacientů ve skutečnosti trpí onemocnění srdce (1) a kolik ne (0):
Toto je počet pozemku níže:
Pojďme pokračovat rozdělením naše školení a testovací data a naše vstupních a cílových proměnných. Od té doby jsme pomocí KNN, to je povinné, aby rozsah našich datových souborů:
intuice za výběr nejlepší hodnota k je nad rámec tohoto článku, ale měli bychom vědět, že můžeme určit optimální hodnotu k, kdy jsme se získat nejvyšší skóre testu pro tuto hodnotu., Za to, že můžeme vyhodnotit školení a testování skóre až pro 20 nejbližších sousedů:
vyhodnotit max test skóre a k hodnoty s ním spojené, spusťte následující příkaz:

Tak jsme získali optimální hodnota k 3, 11, nebo 20 se skóre 83.5. Budeme dokončit jednu z těchto hodnot a fit modelu, tedy:

Nyní, jak můžeme posoudit, zda tento model je „dobrý“ model, nebo ne?, Za to, že budeme používat něco, co nazývá Matice záměn:
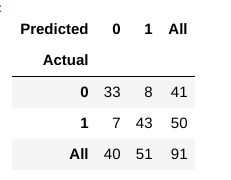
zmatek matice nám pomáhá získat vhled do toho, jak naše předpovědi byly správné a jak se mají proti skutečné hodnoty.
z našich vlakových a testovacích dat již víme, že naše testovací data sestávala z 91 datových bodů. To je hodnota 3.řádku a 3. sloupce na konci. Také si všimneme, že existují některé skutečné a předpokládané hodnoty. Skutečné hodnoty jsou počet datových bodů, které byly původně rozděleny do 0 nebo 1., Předpokládané hodnoty jsou počet datových bodů, které náš model KNN předpověděl jako 0 nebo 1.
aktuální hodnoty jsou:
- pacientů, kteří ve skutečnosti nemají onemocnění srdce = 41
- u pacientů, kteří mají onemocnění srdce = 50
předpokládané hodnoty jsou:
- Počet pacientů, kteří byli předpověděl, jak nemají onemocnění srdce = 40
- Počet pacientů, kteří byli předpověděl, jak s onemocněním srdce = 51
Všechny hodnoty, které jsme získali výše uvedené období., Projděme je jeden po druhém:
- případy, kdy pacienti skutečně neměli srdeční onemocnění, a náš model také předpovídal, že jej nemají, se nazývají skutečné negativy. Pro náš matrix, True Negatives = 33.
- případy, kdy pacienti skutečně trpí srdečními chorobami, a náš model také předpovídal, že je mají, se nazývají skutečné pozitiva. Pro naši matrici True Positives = 43
- existují však některé případy, kdy pacient skutečně nemá srdeční onemocnění, ale náš model předpověděl, že ano., Tento druh chyby je chyba typu I a nazýváme hodnoty jako falešně pozitivní. Pro naše matice, Falešných Poplachů = 8
- Podobně, tam jsou některé případy, kdy pacient skutečně má onemocnění srdce, ale náš model předpovídá, že on/ona ne. Tento druh chyby je Typ Chyby II a říkáme hodnoty jako Falešně negativní. Pro naši matici, falešné negativy = 7
co je přesnost?
vpravo-takže teď se dostáváme k jádru tohoto článku. Co je na světě přesnost? A co s tím souvisí všechny výše uvedené učení?,
v nejjednodušších termínech je přesnost poměr mezi skutečnými pozitivy a všemi pozitivy. Pro naše problémové prohlášení by to bylo měřítkem pacientů, které správně identifikujeme s onemocněním srdce ze všech pacientů, kteří ji skutečně mají. Matematicky:

jaká je přesnost našeho modelu? Ano, je to 0, 843 nebo, když předpovídá, že pacient má srdeční onemocnění, je to správné kolem 84% času.
přesnost nám také dává míru příslušných datových bodů., Je důležité, abychom nezačali léčit pacienta, který ve skutečnosti nemá srdeční onemocnění, ale náš model předpovídal, že ho má.
co je to odvolání?
odvolání je měřítkem našeho modelu, který správně identifikuje skutečné pozitiva. Takže pro všechny pacienty, kteří skutečně mají srdeční onemocnění, recall nám říká, kolik jsme správně identifikovali jako srdeční onemocnění. Matematicky:

pro náš model, Recall = 0.86. Připomeňme také dává míru, jak přesně náš model je schopen identifikovat příslušné údaje., Označujeme to jako citlivost nebo skutečnou pozitivní míru. Co když má pacient srdeční onemocnění, ale není mu poskytnuta žádná léčba, protože náš model to předpověděl? To je situace, které bychom se chtěli vyhnout!
nejjednodušší metrika k pochopení-přesnost
nyní se dostáváme k jedné z nejjednodušších metrik všech, přesnosti. Přesnost je poměr celkového počtu správných předpovědí a celkového počtu předpovědí. Dokážete odhadnout, jaký bude vzorec přesnosti?
![]()
pro náš model bude přesnost = 0.835.,
použití přesnosti jako definující metriky pro náš model má smysl intuitivně, ale častěji než ne, je vždy vhodné používat přesnost a vyvolat také. Mohou existovat i jiné situace, kdy je naše přesnost velmi vysoká, ale naše přesnost nebo odvolání je nízká. V ideálním případě bychom se pro náš model chtěli zcela vyhnout situacím, kdy má pacient srdeční onemocnění,ale náš model klasifikuje, že ho nemá, tj.,
Na druhou stranu, pro případy, kdy není pacient trpí onemocněním srdce, a náš model předpovídá, naopak, rádi bychom také, aby se zabránilo léčení pacienta bez srdečního onemocnění(rozhodující při vstupních parametrů může indikovat různé nemoci, ale nakonec léčíme ho/ji na onemocnění srdce).
přestože se zaměřujeme na vysokou přesnost a vysokou hodnotu vyvolání, dosažení obou současně není možné., Například, pokud změníme model, což nám dává vysokou připomeňme, můžeme zjistit, že všichni pacienti, kteří mají onemocnění srdce, ale možná nakonec budeme dávat léčby pro mnoho pacientů, kteří netrpí.
podobně, pokud se snažíme o vysokou přesnost, abychom se vyhnuli nesprávné a nevyžádané léčbě, nakonec získáme spoustu pacientů, kteří skutečně mají srdeční onemocnění bez jakékoli léčby.
Role F1-Score
porozumění přesnosti nás přimělo uvědomit si, že potřebujeme kompromis mezi přesností a vyvoláním., Nejprve se musíme rozhodnout, co je pro náš klasifikační problém důležitější.
například pro náš datový soubor můžeme vzít v úvahu, že dosažení vysokého odvolání je důležitější než získání vysoké přesnosti – chtěli bychom zjistit co nejvíce srdečních pacientů. Pro některé další modely, jako klasifikace, zda zákazník banky je úvěr protistrany, nebo ne, je žádoucí, aby se vysoká přesnost, protože banky nechtějí přijít o zákazníky, kteří byli popíral úvěr založený na modelu je predikce, že by neplatiče.,
existuje také mnoho situací, kdy přesnost i odvolání jsou stejně důležité. Například, pro náš model, pokud lékař informuje nás, že pacienti, kteří byly nesprávně klasifikovány jako utrpení z onemocnění srdce jsou stejně důležité, neboť by mohly být svědčící o nějaké jiné onemocnění, pak bychom se zaměřit na nejen vysokou připomeňme si, ale vysoká přesnost stejně.
v takových případech používáme něco, co se nazývá F1-score., F1-skóre je Harmonický průměr Přesnosti a Připomeňme si:

Toto je jednodušší pracovat s, protože teď, místo vyvažování přesnost a připomeňme, můžeme jen zaměřit se na dobré F1-skóre, a to by být svědčící o dobrou Přesnost a dobré Připomenout hodnotu stejně.,
můžeme vytvářet výše uvedené metriky pro náš dataset pomocí sklearn:
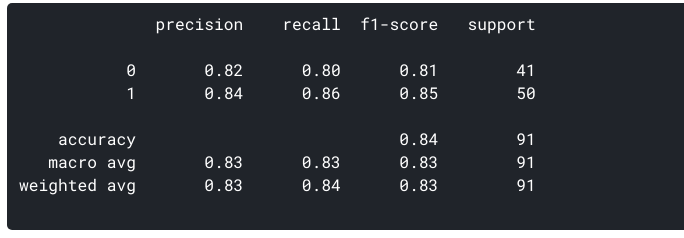
ROC Křivka
Spolu s výše uvedenými podmínkami, existuje více hodnot můžeme vypočítat z confusion matrix:
- False Positive Rate (FPR): To je poměr Falešných Poplachů na Skutečný počet Negativů. V kontextu našeho modelu je to opatření pro to, kolik případů model předpovídá, že pacient má srdeční onemocnění od všech pacientů, kteří ve skutečnosti neměli srdeční onemocnění. Pro naše údaje je FPR = 0.,195
- True Negative Rate (TNR) nebo specificita: je to poměr skutečných negativů a skutečného počtu negativů. Pro náš model je měřítkem toho, kolik případů model správně předpověděl, že pacient nemá srdeční onemocnění od všech pacientů, kteří ve skutečnosti neměli srdeční onemocnění. TNR pro výše uvedená data = 0,804. Z těchto 2 definic můžeme také usoudit, že specificita nebo TNR = 1 – FPR
můžeme také vizualizovat přesnost a vyvolání pomocí křivek ROC a křivek ČLR.,
křivky ROC (křivka provozní charakteristiky přijímače):
jedná se o graf mezi TPR(osa y) a FPR(osa x). Jelikož náš model klasifikuje pacienta s onemocněním srdce nebo nejsou založeny na pravděpodobnosti generovány pro každou třídu, můžeme se rozhodnout, práh pravděpodobnosti stejně.
například chceme nastavit prahovou hodnotu 0,4. To znamená, že model klasifikuje datapoint / pacienta jako onemocnění srdce, pokud je pravděpodobnost, že pacient má srdeční onemocnění, větší než 0,4., To samozřejmě poskytne vysokou hodnotu odvolání a sníží počet falešných pozitiv. Podobně můžeme vizualizovat, jak náš model funguje pro různé prahové hodnoty pomocí křivky ROC.
vytvořme křivku ROC pro náš model s K = 3.
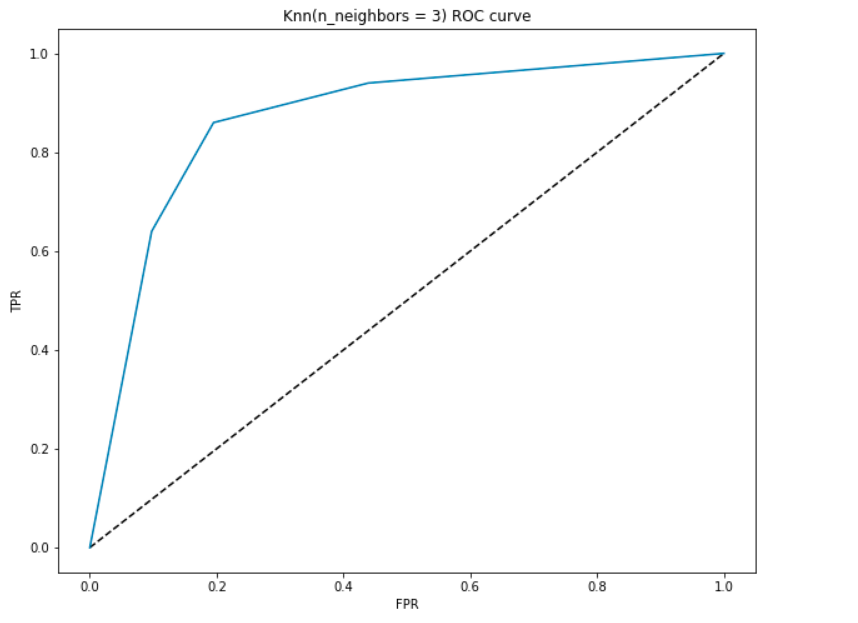
AUC Výklad-
- V nejnižším bodě, tj. v (0, 0)- práh je nastaven na 1.0. To znamená, že náš model klasifikuje všechny pacienty jako nemající srdeční onemocnění.
- v nejvyšším bodě, tj. v (1, 1), je prahová hodnota nastavena na 0,0., To znamená, že náš model klasifikuje všechny pacienty jako srdeční onemocnění.
- zbytek křivky jsou hodnoty FPR a TPR pro prahové hodnoty mezi 0 a 1. Při určité prahové hodnotě pozorujeme, že u FPR téměř 0 dosahujeme TPR téměř 1. To je, když model bude předpovídat pacienty s onemocněním srdce téměř dokonale.
- oblast s křivkou a osami jako hranice se nazývá oblast pod křivkou (AUC). Právě tato oblast je považována za metriku dobrého modelu., S touto metrikou v rozmezí od 0 do 1 bychom měli usilovat o vysokou hodnotu AUC. Modely s vysokou AUC se nazývají jako modely s dobrou dovedností. Dejte nám vypočítat AUC skóre našeho modelu a výše uvedených pozemku:

- dostaneme hodnotu 0.868 jako AUC, což je docela dobré skóre! Jednoduše řečeno, to znamená, že model bude schopen rozlišit pacienty s onemocněním srdce a ti, kteří ne 87% času. Můžeme zlepšit toto skóre a vyzývám vás vyzkoušet různé hodnoty hyperparametru.,
- diagonální čára je náhodný model s AUC 0.5, model bez dovedností, který stejně jako náhodná predikce. Můžete hádat proč?
Precision-Recall Curve(PRC)
jak název napovídá, tato křivka je přímou reprezentací přesnosti(osa y) a vyvolání (osa x). Pokud budete dodržovat naše definice a vzorce pro Přesnost a Připomeňme výše, všimnete si, že v žádném bodě používáme Pravda, Negativy(skutečný počet lidí, kteří nemají onemocnění srdce).,
Toto je zvláště užitečné pro situace, kdy máme nevyvážený datový soubor a počet negativů je mnohem větší, než pozitiva(nebo když je počet pacientů bez onemocnění srdce je mnohem větší než u pacientů s). V takových případech by naším vyšším zájmem bylo zjistit pacienty se srdečním onemocněním co nejpřesněji a nepotřebovali by TNR.
Jako ROC, jsme plot precision a recall pro různé prahové hodnoty:
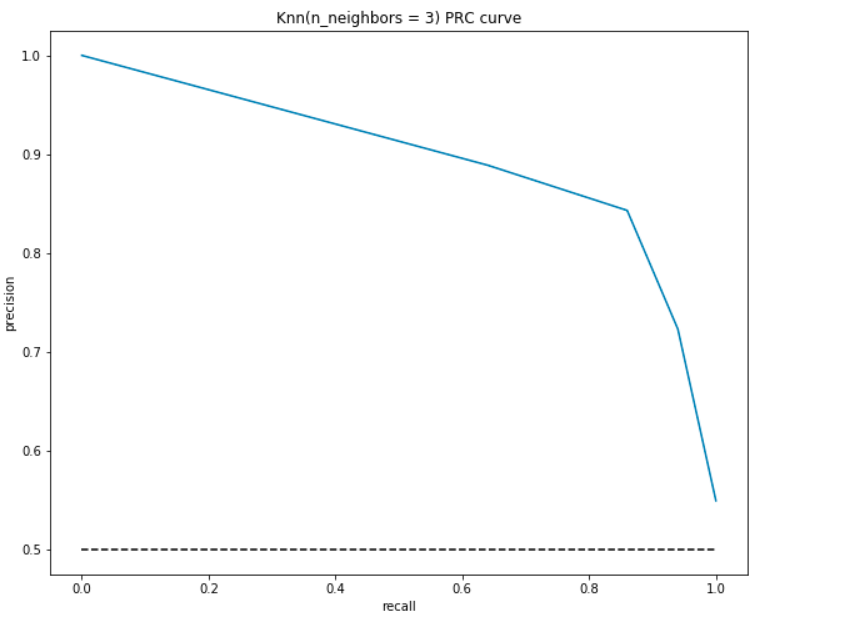
ČLR Výklad:
- V nejnižším bodě, tj., na (0, 0) – práh je nastaven na 1.0. To znamená, že náš model nedělá žádné rozdíly mezi pacienty, kteří mají onemocnění srdce a u pacientů, kteří ne.
- Na nejvyšším místě, tj. u (1, 1), prahová hodnota je nastavena na 0.0. To znamená, že jak naše přesnost, tak odvolání jsou vysoké a model dokonale rozlišuje.
- zbytek křivky jsou hodnoty přesnosti a vyvolání pro prahové hodnoty mezi 0 a 1. Naším cílem je, aby křivka co nejblíže (1, 1), Jak je to možné-což znamená dobrou přesnost a odvolání.,
- podobně jako ROC, oblast s křivkou a osy jako hranice je oblast pod křivkou (AUC). Zvažte tuto oblast jako metriku dobrého modelu. AUC se pohybuje od 0 do 1. Proto bychom měli usilovat o vysokou hodnotu AUC. Dejte nám vypočítat AUC pro našeho modelu a výše uvedených pozemku:

stejně Jako dříve, budeme mít dobrý AUC o přibližně 90%. Také model může dosáhnout vysoké přesnosti s recall as 0 a dosáhne vysokého odvolání tím, že ohrozí přesnost 50%.,
end Notes
Na závěr jsme v tomto článku viděli, jak vyhodnotit klasifikační model, zejména se zaměřením na přesnost a vyvolání, a najít rovnováhu mezi nimi. Vysvětlíme také, jak reprezentovat výkon našeho modelu pomocí různých metrik a matrice zmatku.
zde je další článek pro pochopení metrik hodnocení – 11 důležitých metrik hodnocení modelu pro strojové učení každý by měl vědět