Oversigt
- Precision og recall er to afgørende er endnu misforståede emner i machine learning
- Vi vil diskutere, hvad præcision og recall er, hvordan de fungerer, og deres rolle i vurderingen af en machine learning model
- Vi vil også få en forståelse af Arealet Under Kurven (AUC) og Nøjagtighed form
Indledning
Spørg enhver machine learning professionel eller data scientist om de mest forvirrende begreber i deres læring rejse., Og uvægerligt, svaret veers mod præcision og tilbagekaldelse.forskellen mellem præcision og tilbagekaldelse er faktisk let at huske – men kun når du virkelig har forstået, hvad hvert udtryk står for. Men ganske ofte, og jeg kan attestere dette, har eksperter en tendens til at tilbyde halvbagte forklaringer, der forvirrer nyankomne endnu mere.
så lad os indstille posten lige i denne artikel.

for enhver maskinlæringsmodel ved vi, at det er ekstremt vigtigt at opnå en ‘god pasform’ på modellen., Dette indebærer at opnå balance mellem underfitting og overfitting, eller med andre ord, en afvejning mellem bias og varians.
men når det kommer til klassificering – er der en anden afvejning, der ofte overses til fordel for bias-varians tradeoff. Det er præcisions-tilbagekaldelsen. Ubalancerede klasser forekommer ofte i datasæt, og når det kommer til specifikke brugssager, vil vi faktisk gerne lægge større vægt på præcisions-og tilbagekaldelsesmetrikkerne, og også hvordan man opnår balancen mellem dem.
men hvordan gør man det?, Vi vil undersøge klassificeringsevalueringsmålingerne ved at fokusere på præcision og tilbagekaldelse i denne artikel. Vi vil også lære at beregne disse målinger i Python ved at tage et datasæt og en simpel klassifikationsalgoritme. Så lad os komme i gang!
Du kan lære om evalueringsmålinger dybtgående her-evalueringsmålinger til maskinlæringsmodeller.
Indholdsfortegnelse
- forståelse af problemformuleringen
- hvad er præcision?
- hvad er tilbagekaldelse?,
- Den Nemmeste Evaluering Metrisk – Nøjagtighed
- Rollen for F1-Score
- Den Berømte Præcision-Husker Afvejning
- Forståelse Arealet Under Kurven (AUC)
Forstå Problemet
jeg tror på at lære ved at gøre. Så i hele denne artikel snakker vi praktisk – ved at bruge et datasæt.
lad os tage det populære Hjertesygdomsdatasæt op, der er tilgængeligt på UCI-depotet. Her skal vi forudsige, om patienten lider af en hjertesygdom eller ikke bruger det givne sæt funktioner., Du kan do .nloade det rene datasæt herfra.da denne artikel udelukkende fokuserer på modelevalueringsmålinger, bruger vi den enkleste klassifikator – kNN-klassificeringsmodellen til at foretage forudsigelser.
Som altid, vi skal starte med at importere den nødvendige biblioteker og pakker:
Så lad os få et kig på data og mål variabler, vi beskæftiger os med:
Lad os se, om vi har manglende værdier:
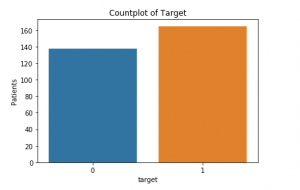
Der er ingen manglende værdier., Nu kan vi tage et kig på, hvor mange patienter, der rent faktisk lider af hjertesygdomme (1), og hvor mange er ikke (0):
Dette er det tæller plot nedenfor:
Lad os gå videre ved at opdele vores træning og test af data og vores input og målvariabler. Da vi bruger KNN, det er obligatorisk at skalere vores datasæt for:
intuitionen bag at vælge den bedste værdi af k, ligger uden for rammerne af denne artikel, men vi skal vide, at vi kan bestemme den optimale værdi af k, når vi får den højeste test resultat for den pågældende værdi., For at vi kan vurdere, uddannelse og test scores for op til 20 nærmeste naboer:
for At vurdere max test score, og de k-værdier, der er forbundet med det, skal du køre følgende kommando:

vi har Således opnået den optimale værdi af k 3, 11, eller 20 med en score på 83,5. Vi afslutter en af disse værdier og passer modellen i overensstemmelse hermed:

hvordan vurderer vi nu, om denne model er en ‘god’ model eller ej?, For at vi bruger noget, der hedder en Forvirring Matrix:
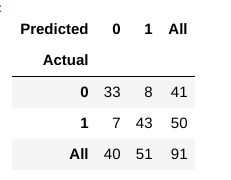
En forvirring matrix hjælper os med at få et indblik i, hvordan korrekte vores forudsigelser var, og hvordan de holder op mod den faktiske værdier.
fra vores tog-og testdata ved vi allerede, at vores testdata bestod af 91 datapunkter. Det er den 3. række og 3. kolonne værdi i slutningen. Vi bemærker også, at der er nogle faktiske og forudsagte værdier. De faktiske værdier er antallet af datapunkter, der oprindeligt blev kategoriseret i 0 eller 1., De forudsagte værdier er antallet af datapunkter, som vores KNN-model forudsagde som 0 eller 1.
Den faktiske værdier er:
- De patienter, der rent faktisk ikke har en hjertesygdom = 41
- De patienter, der rent faktisk har en hjertesygdom = 50
De forudsagte værdier er:
- Antallet af patienter, der blev forudsagt for ikke at have en hjertesygdom = 40
- Antallet af patienter, der var forudsagt til at have en hjertesygdom = 51
Alle de værdier, vi får ovenfor, har en valgperiode., Lad os gå over dem en efter en:
- de tilfælde, hvor patienterne faktisk ikke havde hjertesygdomme, og vores model forudsagde også, at de ikke havde det, kaldes de sande negativer. For vores Matri., sande negativer = 33.
- de tilfælde, hvor patienterne faktisk har hjertesygdomme, og vores model også forudsagt at have det, kaldes de sande positive. For vores Matri.er sande positive = 43
- Der er dog nogle tilfælde, hvor patienten faktisk ikke har nogen hjertesygdom, men vores model har forudsagt, at de gør det., Denne form for fejl er type I-fejlen, og vi kalder værdierne som falske positiver. For vores matrix, Falske Positiver = 8
- Tilsvarende er der er nogle tilfælde, hvor patienten faktisk har en hjertesygdom, men vores model har forudsagt, at han/hun ikke. Denne slags fejl er den Type II Fejl, og vi kalder de værdier, som Falsk Negative resultater. For vores Matri=, falske negativer = 7
hvad er præcision?
højre – så nu kommer vi til kernen i denne artikel. Hvad i verden er præcision? Og hvad har al ovennævnte læring at gøre med det?,
på de enkleste vilkår er præcision forholdet mellem de sande positive og alle positive. For vores problemerklæring ville det være målet for patienter, som vi korrekt identificerer at have en hjertesygdom ud af alle de patienter, der faktisk har det. Matematisk:

Hvad er Præcisionen for vores model? Ja, det er 0.843, eller når det forudsiger, at en patient har hjertesygdom, er det korrekt omkring 84% af tiden.
præcision giver os også et mål for de relevante datapunkter., Det er vigtigt, at vi ikke begynder at behandle en patient, der faktisk ikke har en hjertesygdom, men vores model forudsagde at have det.
Hvad er tilbagekaldelse?
tilbagekaldelsen er målet for vores model, der korrekt identificerer sande positive. For alle de patienter, der faktisk har hjertesygdomme, fortæller recall os, hvor mange vi korrekt identificerede som at have en hjertesygdom. Matematisk:

for vores model, Recall = 0.86. Recall giver også et mål for, hvor præcist vores model er i stand til at identificere de relevante data., Vi henviser til det som følsomhed eller ægte positiv sats. Hvad hvis en patient har hjertesygdom, men der ikke gives nogen behandling til ham / hende, fordi vores model forudsagde det? Det er en situation, vi gerne vil undgå!
den nemmeste måling at forstå – nøjagtighed
nu kommer vi til en af de enkleste målinger af alle, nøjagtighed. Nøjagtighed er forholdet mellem det samlede antal korrekte forudsigelser og det samlede antal forudsigelser. Kan du gætte, hvad formlen for nøjagtighed vil være?
![]()
for vores model vil nøjagtigheden være = 0.835.,
brug af nøjagtighed som en definerende metrisk for vores model giver mening intuitivt, men oftere end ikke anbefales det altid at bruge præcision og tilbagekaldelse også. Der kan være andre situationer, hvor vores nøjagtighed er meget høj, men vores præcision eller tilbagekaldelse er lav. Ideelt set vil vi for vores model helt undgå situationer, hvor patienten har hjertesygdom, men vores model klassificerer som ham, der ikke har det, dvs.sigter mod høj tilbagekaldelse.,
På den anden side, i de tilfælde, hvor patienten ikke lider af hjertesygdomme og vores model forudsiger det modsatte, vi vil også gerne undgå at behandle en patient uden hjerte sygdomme(afgørende, når input parametre, der kunne angive en anden lidelse, men vi ender med at behandle ham/hende for en hjerte lidelse).
selvom vi sigter mod høj præcision og høj tilbagekaldelsesværdi, er det ikke muligt at opnå begge på samme tid., For eksempel, hvis vi ændrer modellen til en, der giver os en høj tilbagekaldelse, kan vi opdage alle de patienter, der faktisk har hjertesygdomme, men vi kan ende med at give behandlinger til mange patienter, der ikke lider af det.
tilsvarende, hvis vi sigter mod høj præcision for at undgå at give forkert og ubesvaret behandling, ender vi med at få mange patienter, der faktisk har en hjertesygdom, uden nogen behandling.
F1-scores rolle
forståelse af nøjagtighed fik os til at indse, vi har brug for en afvejning mellem præcision og tilbagekaldelse., Vi skal først beslutte, hvad der er vigtigere for vores klassificeringsproblem.for eksempel for vores datasæt kan vi overveje, at det er vigtigere at opnå en høj tilbagekaldelse end at få en høj præcision – vi vil gerne opdage så mange hjertepatienter som muligt. For nogle andre modeller, som klassificering, om en bank kunde misligholder et lån eller ej, er det ønskeligt at have en høj præcision, da banken ikke ønsker at miste kunder, der blev nægtet et lån baseret på modellens forudsigelse om, at de ville være synderne.,
Der er også mange situationer, hvor både præcision og tilbagekaldelse er lige så vigtige. For eksempel, for vores model, hvis lægen informerer os om, at de patienter, der forkert blev klassificeret som lider af hjertesygdomme, er lige så vigtige, da de kunne være tegn på en anden lidelse, så ville vi sigte mod ikke kun en høj tilbagekaldelse, men også en høj præcision.
i sådanne tilfælde bruger vi noget, der hedder F1-score., F1-score er det harmoniske gennemsnit af præcisionen og tilbagekaldelsen:

Dette er lettere at arbejde med siden nu, i stedet for at afbalancere præcision og tilbagekaldelse, kan vi bare sigte mod en god F1-score, og det ville også være tegn på en god præcision og en god Tilbagekaldelsesværdi.,
Vi kan generere ovenstående målinger for vores datasæt ved hjælp af sklearn for:
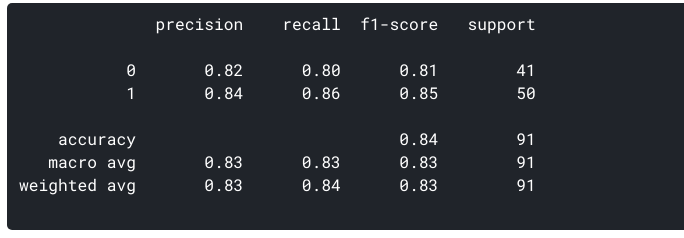
ROC Kurve
Sammen med de ovennævnte vilkår, der er mere værdier, vi kan beregne fra den forvirring matrix:
- Falsk Positiv Rate (FPR): Det er forholdet mellem den Falske Positiver for at det Faktiske antal af Negativer. I forbindelse med vores model er det et mål for, hvor mange tilfælde modellen forudsiger, at patienten har en hjertesygdom fra alle de patienter, der faktisk ikke havde hjertesygdommen. For vores data er FPR = 0.,195
- True Negative Rate (TNR) eller specificiteten: det er forholdet mellem de sande negativer og det faktiske antal negativer. For vores model er det målet for, hvor mange tilfælde modellen korrekt forudsagde, at patienten ikke har hjertesygdomme fra alle de patienter, der faktisk ikke havde hjertesygdomme. TNR for ovennævnte data = 0,804. Fra disse 2 Definitioner kan vi også konkludere, at specificitet eller TNR = 1 – FPR
Vi kan også visualisere præcision og tilbagekaldelse ved hjælp af ROC-kurver og PRC-kurver.,
ROC kurver(modtager opererer karakteristisk kurve):
det er plottet mellem TPR(y-akse) og FPR(axis-akse). Da vores model klassificerer patienten som hjertesygdom eller ikke baseret på de sandsynligheder, der genereres for hver klasse, kan vi også bestemme tærsklen for sandsynlighederne.
for eksempel ønsker vi at indstille en tærskelværdi på 0, 4. Dette betyder, at modellen vil klassificere datapunktet / patienten som hjertesygdom, hvis sandsynligheden for, at patienten har en hjertesygdom, er større end 0,4., Dette vil naturligvis give en høj tilbagekaldelsesværdi og reducere antallet af falske positiver. På samme måde kan vi visualisere, hvordan vores model fungerer for forskellige tærskelværdier ved hjælp af ROC-kurven.
lad os generere en ROC-kurve for vores model med k = 3.
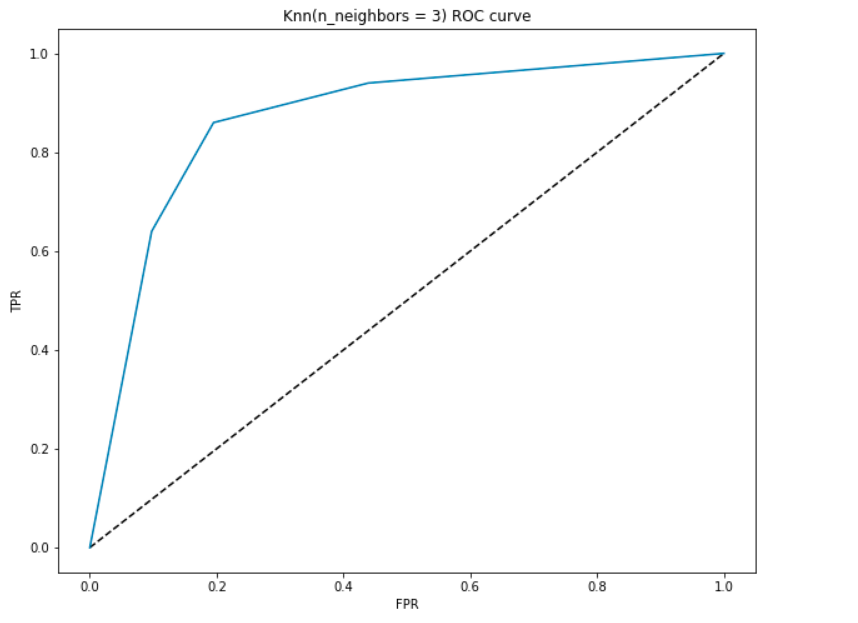
AUC Fortolkning-
- På den laveste punkt, nemlig i (0, 0)- grænseværdien er sat til 1.0. Dette betyder, at vores model klassificerer alle patienter som ikke at have en hjertesygdom.
- på det højeste punkt, dvs. ved (1, 1), er tærsklen sat til 0,0., Dette betyder, at vores model klassificerer alle patienter som at have en hjertesygdom.
- resten af kurven er værdierne for FPR og TPR for tærskelværdierne mellem 0 og 1. Ved en vis tærskelværdi observerer vi, at for FPR tæt på 0 opnår vi en TPR på tæt på 1. Dette er, når modellen vil forudsige patienter, der har hjertesygdomme næsten perfekt.
- området med kurven og akserne som grænserne kaldes området under kurven (AUC). Det er dette område, der betragtes som en måling af en god model., Med denne metriske spænder fra 0 til 1, bør vi sigte mod en høj værdi af AUC. Modeller med et højt AUC kaldes som modeller med god dygtighed. Lad os beregne den AUC score på vores model og ovenstående plot:

- får Vi en værdi af 0.868 som AUC, hvilket er en rigtig god score! På enkleste vilkår betyder det, at modellen vil kunne skelne patienter med hjertesygdomme og dem, der ikke 87% af tiden. Vi kan forbedre denne score, og jeg opfordrer dig til at prøve forskellige hyperparameterværdier.,
- den diagonale linje er en tilfældig model med et AUC på 0,5, en model uden dygtighed, hvilket bare er det samme som at lave en tilfældig forudsigelse. Kan du gætte hvorfor?
Precision-Recall Curve (PRC)
Som navnet antyder, er denne kurve en direkte repræsentation af præcisionen(y-aksen) og tilbagekaldelsen (.-aksen). Hvis du overholder vores definitioner og formler for præcisionen og tilbagekaldelsen ovenfor, vil du bemærke, at vi på intet tidspunkt bruger de sande negativer(det faktiske antal mennesker, der ikke har hjertesygdomme).,
Dette er især nyttigt for de situationer, hvor vi har en ubalanceret datasæt, og antallet af negativer er meget større end de positive(eller når antallet af patienter, der ikke har nogen hjertesygdom er meget større end de patienter, der har det). I sådanne tilfælde ville vores større bekymring være at opdage patienter med hjertesygdomme så korrekt som muligt og ville ikke have brug for TNR.
ligesom ROC tegner vi præcisionen og husker for forskellige tærskelværdier:
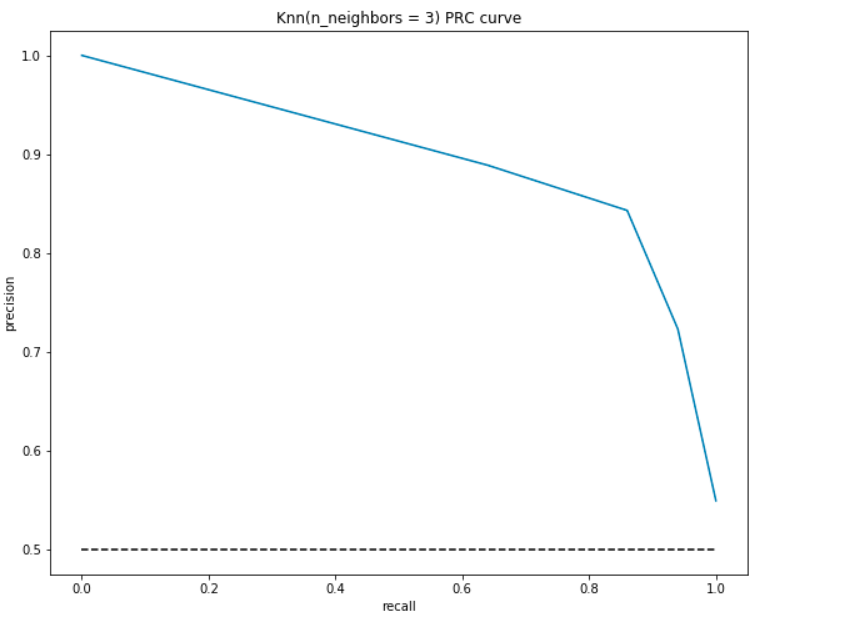
PRC-fortolkning:
- på det laveste punkt, dvs., ved (0, 0) – tærsklen er sat til 1.0. Dette betyder, at vores model ikke skelner mellem de patienter, der har hjertesygdomme, og de patienter, der ikke gør det.
- på det højeste punkt, dvs.ved (1, 1), er tærsklen sat til 0,0. Det betyder, at både vores præcision og tilbagekaldelse er høj, og modellen gør sondringer perfekt.
- resten af kurven er værdierne for præcision og tilbagekaldelse for tærskelværdierne mellem 0 og 1. Vores mål er at gøre kurven så tæt på (1, 1) som muligt – hvilket betyder en god præcision og tilbagekaldelse.,
- I lighed med ROC er området med kurven og akserne som grænserne området under kurven (AUC). Overvej dette område som en måling af en god model. AUC varierer fra 0 til 1. Derfor bør vi tilstræbe en høj værdi af AUC. Lad os beregne den AUC for vores model og ovenstående plot:

Som før, vi får en god AUC på omkring 90%. Modellen kan også opnå høj præcision med tilbagekaldelse som 0 og ville opnå en høj tilbagekaldelse ved at kompromittere præcisionen på 50%.,
Slutnotater
for at konkludere, så vi i denne artikel, hvordan man evaluerer en klassifikationsmodel, især med fokus på præcision og tilbagekaldelse, og finder en balance mellem dem. Vi forklarer også, hvordan vi repræsenterer vores modelydelse ved hjælp af forskellige målinger og en forvirringsmatri..
Her er en yderligere artikel for dig at forstå evaluation metrics – 11 vigtige Model Evaluation Metrics For Machine Learning Alle bør vide