stregkode 101: vejledning til stregkodesymboler
et stregkodesymbol er et maskinlæsbart billede, der formidler data. Stregkoder kan opdeles i tre generelle typer: lineær, stablet lineær, og to-dimensionelle (eller 2D): Lineære Stregkoder
UPC-A
UPC-A (også blot kaldet UPC) er den standard, detailhandel “pris-kode” stregkode i Usa. UPC – A er strengt numerisk; søjlerne kan kun repræsentere cifrene fra 0 til 9., A UPC-A stregkode indeholder 12 cifre sammen med en stille (tom) zoneone på hver side og start -, mellem-og stopsymboler. Det midterste symbol adskiller venstre side og højre side, som er kodet forskelligt. Når der bruges et ciffer på venstre side, er stængerne sorte, og mellemrummet er hvidt, og når det bruges på højre side, vendes farverne., Logikken bag at gøre dette er lidt kompliceret og involverer en matematisk egenskab kaldet “paritet”, men effekten er at vende sort / hvid og lade scanneren fortælle, om den læser koden fra venstre til højre eller fra højre til venstre.
det faktiske nummereringssystem afhænger af produkttypen og formålet med stregkoden; det første ciffer i stregkoden angiver nummereringssystemet., De 10 cifre, der følger, indeholder oplysninger om produktet, og i alle de applikationer, der er beskrevet nedenfor, er cifferet yderst til højre (ikke inkluderet i applikationsbeskrivelsen) et checksum, som kan bruges til at teste nøjagtigheden af scannerens læsning. Nedenfor er en liste over almindelige UPC-A-applikationer:




UPC-E
UPC-E stregkoden kan bruges, når den ledige plads er for lille til en UPC-A stregkode. den indeholder de samme oplysninger som en UPC-A-etiket, men den bruger nogle tricks til at reducere antallet af cifre til seks.,

he UPC-E-kodens mest basale trick er at fjerne efterfølgende nuller i producentens kode og førende nuller i Produktkoden. Detaljerne i teknikken er komplicerede, og det virker ikke for alt, men det dækker alle koder med i alt 5 førende/efterfølgende nuller samt et betydeligt antal koder med fire nuller.UPC-E bruger et meget mere komplekst trick til at komprimere checksum og nummersystemkoden. En bivirkning af denne teknik er, at de eneste tilladte nummereringssystemkoder er 0 og 1.,
EAN-13
EAN-13-koden er dybest set en international version af UPC-A. EAN-13 tilføjer et 13.ciffer i yderste venstre side af UPC-A-koden (så den bliver det første ciffer). EAN-13 standard inkluderer UPC-A stregkoder; tilføje en førende 0 til en UPC-A kode forvandler det til den tilsvarende EAN-13 kode.

De vigtigste forskelle mellem EAN-13 og UPC-A (udover den ekstra førende ciffer) er, at med EAN-13, producent og produkt-koder kan variere i længde, og at de første tre cifre gøre op GS1 præfiks, eller “country code.,”
GS1-præfikset udstedes af GS1, International barcode standards organi .ation. Det kan identificere den nationale GS1 medlem organisation eller en særlig anvendelse. Medlemsorganisationerne udsteder producentens koder, og producenterne sætter deres egne produktkoder. Det komplette EAN-13 stregkodenummer, der består af GS1-præfikset, producentens kode, produktkoden og checksumcifret, kaldes også GTIN eller Global Trade varenummer.,Udover de nationale GS1 præfikser, der typisk anvendes til standard detail elementer, der er præfikser til specielle formål, såsom kuponer, tilbagebetalinger, periodiske publikationer (magasiner og aviser), bøger (ISBN), og noder (ISMN).

I Usa, pris-kode-scannere og point-of-sale/lager-systemer er typisk i stand til at læse både UPC-A og EAN-13 stregkoder.
EAN-8
EAN-8 er en GS1 stregkode til brug på små emner, når en fuld EAN-13 stregkode etiket ville være for stor til at passe., Den består af otte cifre-fire på venstre side og fire til højre. De bruger den samme slags kodning som UPC-A og EAN-13, hvor det sidste ciffer bruges som checksum.

En EAN-8 stregkode kan bruges enten med GTIN-8 eller RCN-8 produkt-id-numre.
GTIN-8 er som en forkortet version af EAN-13-koden, men uden information om produktets oprindelse. For at kunne bruge et GTIN-8-nummer skal en producent anmode om det fra den nationale medlemsorganisation., En EAN-8 stregkode, der koder for et GTIN-8 identifikationsnummer er gyldigt til global brug, ligesom en EAN-13 stregkode.
RCN-8 numre, på den anden side, er kun til brug på hus-brand eller store-label produkter, og kan kun bruges inden for den virksomhed, der udsteder det. Hvis det scannes af en anden forhandler, det vil give en forkert læsning.
Code 128
UTF-og EAN – “pris-kode” stregkoder, der er beskrevet ovenfor indkode kun tal, men Code 128 er en lineær stregkode, der indeholder både bogstaver i alfabetet og tal, hvilket gør den anvendelig til mange forskellige formål ud over grundlæggende prissætning og lagerbeholdning.,kode 128 koder for ASCII-sættet med 128 tegn, der inkluderer alle alfabetiske, numeriske, tegnsætning og aritmetiske tegn, der findes på et engelsksproget computertastatur, plus flere ikke-synlige kontroltegn.,
for at medtage alle ASCII-tegn, Code 128 bruger tre forskellige tegnsæt:



En enkelt Kode 128 stregkode, der kan indeholde tegn fra alle tre tegnsæt, skifte mellem dem flere gange.
stregkodeformatet grundlæggende kode 128 består af en startkode (som indstiller det oprindelige tegnsæt til A, B eller C), kodedataene, et checksumciffer og en stopkode, der markerer slutningen af stregkoden. Som med andre lineære stregkoder er der tomme stille zonesoner på hver side.
GS1-128 (også kendt som UCC-128 og EAN-128) er en international standard for brug af kode 128 i supply-chain stregkodeetiketter., GS1-128 består af det grundlæggende kode 128-format med en Applikationsidentifikator tilføjet til kodedataene.

Ansøgningen identifikatorer er 2 til 4 tegn i længden, og identificere typen af data, der vil følge — typisk standard supply-chain-applikationer, såsom serienummer, antal beholdere, masse, mængde, vægt, volumen osv., herunder sporings-og transaktionsoplysninger. Hver identifikator angiver længden og formatet af de data, der følger den.,da de fleste applikationskodedata er fast længde, er det muligt at inkludere flere koder i en GS1-128 stregkode, blot ved at tilføje nye Applikationsidentifikatorer og kodedata.

Kode 39
kode 39-symbologien er også alfanumerisk og variabel længde. Den blev udviklet i 1974 og er stadig i relativt bred Brug; de fleste stregkodelæsere kan læse Kode 39. I Kode 39 består hvert tegn af fem søjler og fire mellemrum, hvor tre af disse søjler/mellemrum er brede, og de andre smalle., Som følge heraf har alle tegn samme bredde, og en kode 39 stregkode tager normalt mere plads end den tilsvarende kode 128 stregkode.

det grundlæggende Code 39-system består af 43 tegn, herunder store bogstaver, tal og nogle specielle / tegnsætningstegn. Afhængigt af applikationen og systemet kan det være muligt at bruge alle 128 ASCII-tegn.
En kode 39 stregkode består af et starttegn, de kodede data og et stoptegn., Både start-og stop-tegnene er identiske og er generelt repræsenteret af * – stjernesymbolet. der er ingen checksum karakter, men nogle fejlkontrol kapaciteter er indbygget i kodningssystemet.
kode 39 bruges til mange af de samme typer applikationer som Kode 128, og der findes officielle kode 39-standarder (inklusive en ANSI-standard). Det er dog ikke inkluderet i GS1-systemet.
Interleaved 2 af 5
Interleaved 2 af 5 (eller ITF) er en lineær stregkode med variabel længde., Det koder cifre parvis, med det første ciffer i hvert par repræsenteret af søjler, og det andet ciffer repræsenteret af mellemrum, så de er interleaved. To af de fem søjler eller mellemrum, der repræsenterer hvert ciffer, er brede, og de andre er smalle.

Interleaved 2 af 5 er inkluderet i GS1-systemet som ITF-14-standarden, som har en indstillet længde på 14 cifre.,
En ITF-stregkode består af en startkode (to smalle bjælke/smalle rumpar), de kodede data, et checksumciffer (påkrævet til ITF-14, valgfrit andetsteds) og en stopkode (bred bjælke, smalt rum, smal bjælke) med stille zonesoner på hver side.
mønstre, der er identiske med start-og stopkoden, kan forekomme inden for de kodede data, hvilket kan resultere i en dårlig læsning, hvis scanneren ikke læser koden hele vejen igennem. For at forhindre dette kræver ITF-14-standarden en tung sort kant kaldet bærerbjælken.,
ITF stregkoder bruges typisk i engros og forsendelse for kasse eller karton masser af et produkt. En specialiseret version af ITF-stregkoden bruges også på 135 filmbeholdere.
Codabar
Codabar blev oprindeligt udviklet af Pitney bo .es i 1972. Det er en stregkode med variabel længde, der bruger et lille sæt søjler til at kode cifrene 0 til 9, og i nogle applikationer, et par symboler som dollar og plustegn. det omfatter også fire start / stop symboler (generelt repræsenteret af A, B, C og D). En Kodabar-kode består af et startsymbol, de kodede data og et stopsymbol., det er selvkontrol, selvom nogle applikationer angiver et kontrolciffer.

Codabar har traditionelt været brugt på biblioteker, ved at blodet banker, og for airbills af nogle virksomheder som Federal Express, og er stadig i brug for nogle af disse programmer.
Pharmacode
Pharmacode er designet til emballage kontrol og sikkerhed i den farmaceutiske industri.

APharmacode stregkode består kun af to bredder af søjler med en længde på op til 12 bar., Dataene er et enkelt heltal (i området 3 til 131070) kodet som et binært tal. Pharmacode stregkoder kan bruge flere farver som en ekstra check for emballage nøjagtighed.

individuelle farmaceutiske virksomheder genererer deres egne Farmakode stregkoder. De bruges på produktionslinjen, hvor de automatisk scannes på indsatser og andre genstande, der placeres i pakken, for at detektere uoverensstemmelser.
Databar
Databar er en GS1 familie af stregkode standarder generelt beregnet til reduceret plads applikationer., De koder GTIN-12 (UPC-A) og GTIN-13 (EAN-13) data i et 14-cifret format (med tilføjede ledende nuller). Lineære stregkoder i Databar-familien inkluderer de Omnidirectionelle og udvidede koder, som kan scannes omnidirectionally, og de afkortede og begrænsede koder, der kun er designet til at blive læst af håndholdte scannere.

omnidirektionelle og udvidede Databar-koder bruges i salgssteder, som UPC-A og EAN-13., Udvidede koder kan indeholde yderligere oplysninger såsom vægt og udløbsdato, udpeget ved hjælp af Applikationsidentifikatorer som GS1-128 stregkoder.

afkortede og begrænsede Databar-stregkoder bruges generelt i sundhedsvæsenet til identifikation af små genstande.

Post (Postnet)
Postnet er stregkodesystemet, der har været i brug af den amerikanske posttjeneste til routing mail; det udfases til fordel for det intelligente postsystem, beskrevet nedenfor., Postnet-koder bruger søjler med variabel højde til at repræsentere cifre.
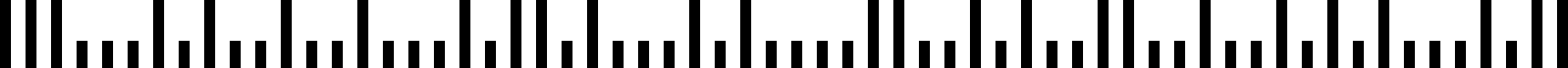
En Postnet barcode består typisk af ZIP, ZIP+4, og levering punkt koderne, med hvert ciffer repræsenteret af fem barer, to som er i fuld højde, og resten i halv højde.Post (Intelligent Mail Barcode)
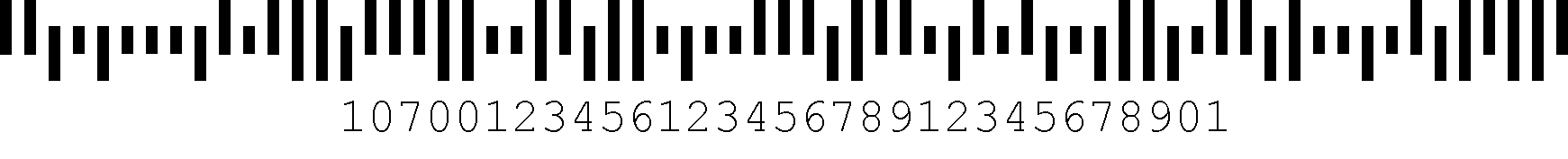
Det intelligente mail stregkode system erstatter Postnet systemet til routing mail af USPS. Det er en 65-bar variabel højde kode med fire typer af bar.,
og IM stregkode består af følgende komponenter:
Stablet Stregkoder
Stablet stregkoder er lineære stregkoder, som er opdelt i segmenter, og placeret over andre

Databar Stablet
De stablede versioner af GS1 Databar koder bruge den samme kodning som den lineære Databar koder, der er beskrevet ovenfor, og bruges i lignende programmer. De er især nyttige til genstande med begrænset plads med etiketter, der har meget smalle lineære dimensioner.,
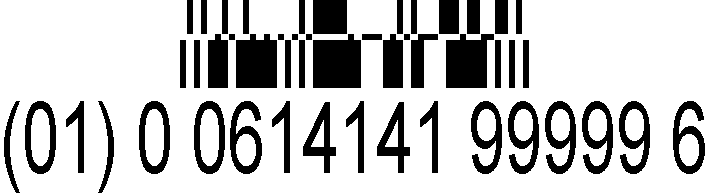
den GS1 udvidede stablede Databar kan stable en række stregkoder, der indeholder produktdata ud over den grundlæggende salgssted EAN-13 priskode.
PDF417
PDF417 er en stablet stregkode med variabel højde, variabel bredde, der består af rækker med korte søjler og mellemrum. Det kan have så få som 3 rækker, eller så mange som 90. Alle rækker skal indeholde det samme antal datakodeord, men dette antal kan variere fra 1 til 30.,

Den faktiske metode til kodning, der er baseret på et komplekst system, som bruger omkring 900 kodeord til at repræsentere data i forskellige formater. Dette gør det muligt for PDF417 at kode tekst, digitale data (i bytes) og store tal inden for samme stregkode.
hver række i en PDF417 stregkode består af et startmønster, det venstreorienterede kodeord (identificerer blandt andet rækken), datakodeordene, det højre kodeord og stopmønsteret. I modsætning til de fleste 2D stregkoder kan PDF417 læses med en laserscanner., PDF417 stregkoder kan kobles sammen, så store mængder data kan scannes i rækkefølge. Dette fjerner effektivt grænsen i mængden af data, der kan kodes, hvilket gør PDF417-formatet konkurrencedygtigt med ægte 2-d stregkoder til at repræsentere store mængder data.
PDF417 er i brug som et high-density stregkode-format i en række applikationer, herunder:
MicroPDF417
MicroPDF417 er en begrænset delmængde af PDF417 designet til situationer, hvor en fuld PDF417 kode ville være for stor. Det sætter grænser for dimensionerne af søjlerne og på mængden og formatet af data, der kan kodes (op til 200 tegn med store bogstaver, 150 binære byte eller 366 numeriske cifre). det lægger også nogle begrænsninger på fejlkorrektionskodeord.
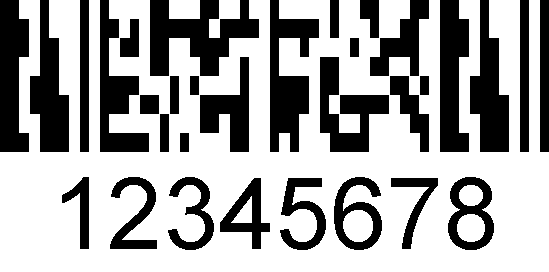
MicroPDF417 bruges i GS1 Databar Kompositkoder, hvor den kombineres med en lineær stregkode.,
2D-Matri.
i modsætning til stablede stregkoder repræsenterer ægte 2D-Matri codeskoder data i et todimensionelt array, som firkanter på et skakbræt. Dette giver dem mulighed for at pakke en stor mængde data i et kompakt rum og repræsentere et meget større tegnsæt. Disse koder skal læses med en billedscanner, snarere end en laserscanner.
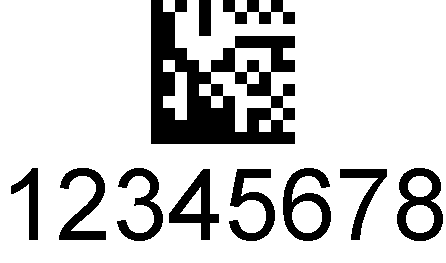
Datamatri.
Datamatri. stregkoder er firkantede eller rektangulære arrays af sort / hvide firkanter eller celler., Hver celle er en smule, repræsenterer en en eller et nul, og afhængigt af typen af kodning, en Datamatri.stregkode kan være i stand til at repræsentere så mange som 2,355 alfanumeriske tegn.

En DataMatrix kode, der har to forskellige typer af grænser, og på et sæt af sider, der støder op, grænsen er solid, og på de to andre sider, det skiftevis sorte og hvide blodlegemer, som giver det udseende af kun at have de to faste grænser., Den faste, eller finder, grænser tillader scanneren at orientere kodens billede, mens den alternerende-celle, eller timer, grænser gør det muligt at tælle rækker og kolonner.Datamatri. – koder kan være ekstremt små, og de kan læses med lav kontrast. Dette gør det muligt at udskrive dem eller endda laser-ætset på små genstande. De kan også skaleres op til en meget stor størrelse til brug på genstande som tunge maskiner, bygninger eller jernbanevogne.,
det faktiske kodningssystem er komplekst og inkluderer overflødig lagring af data, så hvis en del af en Datamatri. – kode går tabt eller beskadiges, kan det stadig være muligt at læse alle dataene. Datamatri.kan indkode tal og alfanumeriske ASCII-tegn ved hjælp af flere kodning og komprimering systemer.Datamatri.bruges til mærkning af små komponenter i elektronikindustrien, enten med trykte etiketter eller direkte mærkning; de bruges også i fødevareindustrien til kvalitetskontrol.,De fleste smartphones kan læse Datamatri. – koder, så de kan bruges til markedsføring, reklame og andre applikationer, hvor smartphone-adgang er ønskelig.
QR-Kode
QR (eller Quick Response) Kode-formatet blev oprindeligt designet til brug i den Japanske bilindustri til at holde styr på dele og biler på samlebånd. På grund af sin alsidighed er det blevet meget udbredt i en række industrielle og forbrugerorienterede applikationer.,

EN QR-kode ligner en DataMatrix kode; det er firkantet (omgivet af en helt blank zone), og består af firkantede sorte og hvide blodlegemer. Men i stedet for grænser, det bruger et sæt af store position og justering kvadrater (og et mindre sæt af timing mærker) sat ind i kroppen af koden.
QR-kode kan kode fire forskellige typer data: tal, alfanumeriske tegn, binære/bytes og japanske kana/kanji., Alfanumerisk kodning er begrænset til tal, store bogstaver og nogle tegnsætning, men binær/byte-kodning omfatter ISO 8859-1 Latin-1 tegnsæt, som helt eller delvist dækker de vesteuropæiske sprog. Kana / Kanji kodning bruger JIS 020 0208 tegnsæt. QR-kode kan kode websiteebadresser, så mobiltelefonbrugere kan lide direkte til et websiteebsted ved at scanne dets kodede URL.
størrelsen og densiteten af en coder-kode kan variere afhængigt af mængden af data, der skal gemmes., Den maksimale lagerkapacitet er cirka 7.000 numeriske tegn, 4,200 alfanumeriske tegn, 2,900 binære tegn, eller 1,800 kana/kanji-tegn. En coder-kode kan opdeles i flere mindre koder, så de kan passe ind i et område, hvor en større kode ikke ville passe.
QR-koder har oplevet en hurtig stigning i antallet og rækkevidden af applikationer, som de bruges til i de senere år, dels fordi de let kan læses af smartphones, tablets og andre mobile enheder., Aktuelle applications .r-kodeapplikationer inkluderer:
patenterne til coder-koden ejes af Denso Waveave (et datterselskab af Denso, som igen ejes af Toyota), som har valgt ikke at udøve sine patentrettigheder og tillader brug af koderne uden licenskrav.
ud over readingr-kodelæsningsapps er gratis Soft .are og webebbaserede tjenester til generering af .r-koder let tilgængelige.,
A .tec
a .tec 2D stregkode kode ligner Datamatri.og .r koder. Den består af en firkant med sorte og hvide celler (eller PI .els) med et lokaliseringssymbol lavet af koncentriske firkanter direkte i midten. Det centrale område (omkring firkantet tyreøje) indeholder oplysninger om symbolets størrelse sammen med andre kodningsdata. Det betyder, at det ikke kræver en tom helt zoneone eller en grænse. Koden indeholder også en intern reference gitter af skiftende sort / hvide pi .els på hver 16.række og kolonne.,

De data, der er arrangeret i en spiral ud fra centrum og ud; hvert lag af spiralen er lavet af to ringe af pixels, tilføjer fire pixels til den samlede bredde. Den centrale bull ‘ s-eye firkant plus lag af kodning og størrelse data tilsammen danner kernen, som kan være kompakt (11 11 11) eller Fuld (15.15). Et A .tec-symbol med en kompakt kerne kan have så mange som 4 lag. Et symbol med en fuld kerne kan have 32 lag og kan kode over 3.800 cifre, 3.000 tegn i tekst eller 1.900 byte binære data., Tekst kan kodes som ASCII og Latin-1; kodningstilstanden kan ændres på flere punkter i dataene.
a .tec-kodesystemet er offentligt domæne, og applikationer er tilgængelige til generering af koder og læsning af dem på mobile enheder. I betragtning af ligheden i design, læsbarhed og kapacitet kunne a .tec-koder bruges i mange af de applikationer, som QR-koder bliver populære til, skønt deres anvendelse i praksis er mere begrænset.
a .tec-koder er dog ret almindelige i transportbranchen., De bruges på flyselskab elektroniske boardingkort, og for online og mobile togbilletter i mange dele af Europa.
derudover bruges de i faktureringssystemerne i flere canadiske virksomheder, og den polske regering bruger dem i sit bilregistreringssystem.
Ma .icode
Ma .icode er en 2D Matri.stregkode, der ligner lidt a .tec-koden, kun med et rundt pletcenter i stedet for en firkantet. Et nærmere kig viser en anden forskel-i stedet for firkantede pi .els kodes dataene i sekskantede prikker, der er arrangeret i et sekskantet mønster.,

MaxiCode var designet til en specialiseret funktion — routing og sporing United Parcel Service-pakker — og det fortsætter med at være dets vigtigste anvendelse.
i Modsætning til de andre 2D-matrix-koder, der er beskrevet her, MaxiCode symboler har en fast størrelse (ca 1 tomme firkant) og en fast mængde data, der kan være kodet (cirka 93 tegn, afhængigt af de data tilstand). Som manyas 8 ma .icode symboler kan være forbundet, eller lænket sammen.,
der er fem datatilstande i den aktuelle brug (såvel som to forældede tilstande):
alle disse tilstande kan indeholde en sekundær meddelelse, som For UPS-forsendelse normalt indeholder mere detaljerede forsendelses-og sporingsoplysninger. I Modus 4, 5 og 6 fusioneres den sekundære meddelelse effektivt med den primære meddelelse.
Ma .icode bruger fem kodesæt; en enkelt meddelelse kan skifte mellem dem gentagne gange. De fem kode sæt sammen omfatter standard ASCII-tegnsæt plus de fleste Latin-1 tegn.