código de barras 101: Guía de simbologías de código de barras
Un Símbolo de código de barras es una imagen legible por máquina que transmite datos. Los códigos de barras se pueden dividir en tres tipos generales: lineal, lineal apilada y bidimensional (o 2D): códigos de barras lineales
UPC-A
el UPC-A (también conocido simplemente como el UPC) es el código de barras estándar al por menor «código de precio» en los Estados Unidos. UPC-A es estrictamente numérico; las barras solo pueden representar los dígitos del 0 al 9., Un código de barras UPC-A contiene 12 dígitos, junto con una zona tranquila (en blanco) a cada lado, y los símbolos de inicio, medio y parada. El símbolo del medio separa el lado izquierdo y el lado derecho, que están codificados de manera diferente. Cuando se usa un dígito en el lado izquierdo, las barras son negras y los espacios son blancos, y cuando se usa en el lado derecho, los colores se invierten., La lógica detrás de hacer esto es un poco complicada, e implica una propiedad matemática llamada «paridad», pero el efecto es invertir el blanco y negro, y permitir que el escáner diga si está leyendo el código de izquierda a derecha o de derecha a izquierda.
El sistema actual de numeración depende del tipo de producto y el propósito del código de barras; el primer dígito del código de barras indica el sistema de numeración., Los 10 dígitos que siguen contienen información sobre el producto, y en todas las aplicaciones descritas a continuación, el dígito en el extremo derecho (no incluido en la descripción de la aplicación) es una suma de verificación, que se puede usar para probar la precisión de la lectura del escáner. A continuación se muestra una lista de aplicaciones UPC-A comunes:




UPC-E
el código de barras UPC-E se puede utilizar cuando el espacio disponible es demasiado pequeño para un código de barras UPC-A. contiene la misma información que una etiqueta UPC-A, pero utiliza algunos trucos para reducir el número de dígitos a seis.,

El truco más básico del código UPC-E es eliminar los ceros finales en el código del fabricante y los ceros iniciales en el código del producto. Los detalles de la técnica son complicados, y no funciona para todo, pero cubre todos los códigos con un total de 5 ceros iniciales/finales, así como un número significativo de códigos con cuatro ceros.
UPC-E utiliza un truco mucho más complejo para comprimir la suma de comprobación y el código del sistema numérico. Un efecto secundario de esta técnica es que los únicos códigos del sistema de numeración permitidos son 0 y 1.,
EAN-13
el código EAN-13 es básicamente una versión internacional de UPC-A. EAN-13 agrega un dígito 13 en el lado izquierdo del código UPC-A (de modo que se convierte en el primer dígito). El estándar EAN-13 incluye códigos de barras UPC-A; agregar un 0 inicial a un código UPC-A lo convierte en el código EAN-13 equivalente.

Las principales diferencias entre EAN-13 y UPC-A (además del dígito inicial adicional) son que con EAN-13, el fabricante y los códigos de producto pueden variar en longitud, y que los tres primeros dígitos conforman el prefijo GS1, o «código de país».,»
el prefijo GS1 es emitido por GS1, la Organización Internacional de estándares de código de barras. Puede identificar la organización nacional miembro de GS1 o un uso especial. Las organizaciones miembros emiten los códigos del fabricante, y los fabricantes establecen sus propios códigos de producto. El número de código de barras EAN-13 completo, que consiste en el prefijo GS1, el código del fabricante, el código del producto y el dígito de suma de verificación, también se conoce como GTIN, o número de artículo de comercio Global.,Además de los prefijos nacionales GS1, típicamente utilizados para artículos estándar al por menor, hay prefijos para fines especializados, como cupones, reembolsos, publicaciones en serie (revistas y periódicos), Libros (ISBN) y partituras (ISMN).

en los Estados Unidos, los escáneres de códigos de precios y los sistemas de punto de Venta/inventario suelen ser capaces de leer códigos de barras UPC-A y EAN-13.
EAN-8
EAN-8 es un código de barras GS1 para usar en artículos pequeños cuando una etiqueta de código de barras EAN-13 completa sería demasiado grande para caber., Consta de ocho dígitos-cuatro en el lado izquierdo y cuatro en el derecho. Utilizan el mismo tipo de codificación que UPC-A y EAN-13, con el último dígito utilizado como suma de comprobación.

Se puede utilizar un código de barras EAN-8 con números de identificación de producto GTIN-8 o RCN-8.
GTIN-8 es como una versión abreviada del Código EAN-13, pero sin información sobre el origen del producto. Para utilizar un número GTIN-8, el fabricante debe solicitarlo a la organización miembro nacional., Un código de barras EAN-8 que codifica un número de identificación GTIN-8 es válido para uso global, como un código de barras EAN-13.
LOS NÚMEROS RCN-8, por otro lado, son para usar solo en productos de marca propia o de marca de tienda, y solo se pueden usar dentro del negocio que los emite. Si es escaneado por otro minorista, dará una lectura incorrecta.
Code 128
Los códigos de barras UTF y EAN «price code» descritos anteriormente codifican solo números, pero Code 128 es un código de barras lineal que codifica tanto letras del alfabeto como números, lo que lo hace útil para una variedad de propósitos más allá de los precios básicos y el inventario.,
Code 128 codifica el conjunto ASCII de 128 caracteres, que incluye todos los caracteres alfabéticos, numéricos, de puntuación y aritméticos que se encuentran en un teclado de computadora en inglés, además de varios caracteres de control no visibles.,
para incluir todos los caracteres ASCII, Code 128 utiliza tres conjuntos de caracteres diferentes:



Un código de barras Single Code 128 puede incluir caracteres de los tres conjuntos de caracteres, cambiando entre ellos repetidamente.
el formato de código de barras basic Code 128 consiste en un código de inicio (que establece el conjunto de caracteres inicial A, B O C), los datos del código, un dígito de suma de verificación y un código de parada, que marca el final del código de barras. Al igual que con otros códigos de barras lineales, hay zonas silenciosas en blanco a cada lado.
GS1-128 (también conocido como UCC-128 y EAN-128) es un estándar internacional para el uso del Código 128 en etiquetas de códigos de barras de la cadena de suministro., GS1-128 consiste en el formato de código básico 128 con un Identificador de aplicación agregado a los datos de código.

los identificadores de aplicación son de 2 a 4 caracteres de longitud e identifican el tipo de datos que seguirán, por lo general, las aplicaciones estándar de la cadena de suministro, como el número de serie, el número de contenedores, el número de lote, el peso, el volumen, etc., incluido el rastreo y la información sobre transacciones. Cada identificador establece la longitud y el formato de los datos que le siguen.,debido a que la mayoría de los datos de código de aplicación son de longitud fija, es posible incluir varios códigos en un código de barras GS1-128, simplemente agregando nuevos identificadores de aplicación y datos de código.

Code 39
La simbología Code 39 también es alfanumérica y de longitud variable. Fue desarrollado en 1974, y todavía está en uso relativamente amplio; la mayoría de los lectores de códigos de barras pueden leer Código 39. En el Código 39, cada carácter se compone de cinco barras y cuatro espacios, con tres de esas barras / espacios siendo anchos, y los otros estrechos., Como resultado, todos los caracteres tienen el mismo ancho, y un código de barras Code 39 generalmente ocupa más espacio que el código de barras Code 128 equivalente.

el sistema Basic Code 39 Se compone de 43 caracteres, incluyendo letras mayúsculas, números y algunos caracteres especiales/de puntuación. Dependiendo de la aplicación y del sistema, es posible utilizar los 128 caracteres ASCII.
Un código de barras Code 39 consiste en un carácter de inicio, los datos codificados y un carácter de parada., Tanto los caracteres de inicio como de parada son idénticos, y generalmente están representados por el símbolo * asterisco. no hay carácter de suma de comprobación, pero algunas capacidades de comprobación de errores están integradas en el sistema de codificación.
El Código 39 Se utiliza para muchos de los mismos tipos de aplicaciones que el Código 128, y existen estándares oficiales del Código 39 (incluido un estándar ANSI). Sin embargo, no está incluido en el sistema GS1.
Interleaved 2 of 5
Interleaved 2 of 5 (o ITF) es un código de barras lineal de longitud variable solo para números., Codifica dígitos en pares, con el primer dígito en cada par representado por barras, y el segundo dígito representado por espacios, de modo que se intercalan. Dos de las cinco barras o espacios que representan cada dígito son anchos, y los otros son estrechos.

Interleaved 2 de 5 se incluye en el sistema GS1 como el estándar ITF-14, que tiene una longitud establecida de 14 dígitos.,
Un código de barras ITF consiste en un código de inicio (dos pares de barra estrecha/espacio estrecho), los datos codificados, un dígito de suma de comprobación (requerido para ITF-14, opcional en otros lugares) y un código de parada (barra ancha, espacio estrecho, barra estrecha), con zonas silenciosas a cada lado.los patrones idénticos al código de inicio y parada pueden ocurrir dentro de los datos codificados, lo que puede resultar en una mala lectura si el escáner no lee el código completamente. Para evitar esto, el estándar ITF-14 requiere un borde negro pesado llamado barra al portador.,
Los códigos de barras ITF se utilizan generalmente en la venta al por mayor y el envío de lotes de caja o cartón de un producto. Una versión especializada del código de barras ITF también se utiliza en 135 envases de película.
Codabar
Codabar fue desarrollado originalmente por Pitney Bowes en 1972. Es un código de barras de longitud variable que utiliza un pequeño conjunto de barras para codificar los dígitos del 0 al 9, y en algunas aplicaciones, algunos símbolos como el dólar y los signos más. también incluye cuatro símbolos start / stop (generalmente representados por A, B, C y D). Un código Codabar consiste en un símbolo de inicio, los datos codificados y un símbolo de parada., es autocomprobable, aunque algunas aplicaciones especifican un dígito de verificación.

Codabar ha sido utilizado tradicionalmente por las bibliotecas, por los bancos de sangre, y para los airbills por algunas empresas como Federal Express, y todavía está en uso para algunas de esas aplicaciones.
Pharmacode
Pharmacode está diseñado para el control y seguridad de envases en la industria farmacéutica.

el código de barras de APharmacode consiste en dos anchos de barras solamente, con una longitud de hasta 12 barras., Los datos son un único entero (en el rango de 3 a 131070) codificado como un número binario. Los códigos de barras Pharmacode pueden usar varios colores como una comprobación adicional de la precisión del embalaje.

las compañías farmacéuticas individuales generan sus propios códigos de barras Pharmacode. Se utilizan en la línea de producción, donde se escanean automáticamente en Insertos y otros artículos que se colocan en el paquete, para detectar desajustes.
Databar
Databar es una familia de códigos de barras GS1 generalmente pensada para aplicaciones de espacio reducido., Codifican los datos GTIN-12 (UPC-A) y GTIN-13 (EAN-13) en un formato de 14 dígitos (con ceros iniciales añadidos). Los códigos de barras lineales de la familia Databar incluyen los códigos omnidireccionales y expandidos, que se pueden escanear omnidireccionalmente, y los códigos truncados y limitados, que están diseñados para ser leídos solo por escáneres portátiles.

Los códigos de base de datos omnidireccionales y expandidos se utilizan en aplicaciones de punto de venta, como UPC-A y EAN-13., Los códigos expandidos pueden incluir información adicional, como el peso y la fecha de vencimiento, designados utilizando identificadores de aplicación a la manera de los códigos de barras GS1-128.

Los códigos de barras DataBar truncados y limitados se utilizan generalmente en la industria del cuidado de la salud para la identificación de artículos pequeños.

Postal (Postnet)
Postnet es el sistema de código de barras que ha sido utilizado por el Servicio Postal de los Estados Unidos para enrutar el correo; se está eliminando gradualmente a favor del sistema de correo inteligente, que se describe a continuación., Los códigos Postnet usan barras de altura variable para representar dígitos.
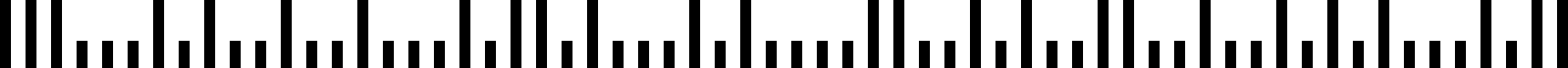
Un código de barras Postnet típicamente consiste en los códigos ZIP, ZIP+4 y delivery point, con cada dígito representado por cinco barras, dos de las cuales son de altura completa, y el resto de media altura.Postal (código de barras de correo inteligente)
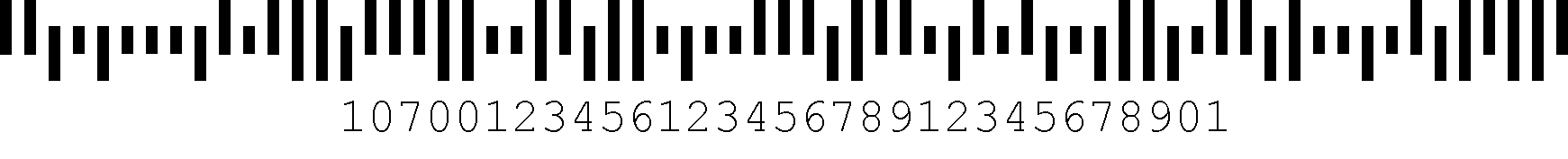
El sistema de código de barras de correo inteligente está reemplazando al sistema Postnet para enrutar correo por el USPS. Es un código de altura variable de 65 barras con cuatro tipos de barras.,
Y IM barcode consta de los siguientes componentes:
Códigos de barras apilados
Los códigos de barras apilados son códigos de barras lineales que se dividen en segmentos y se colocan uno encima del otro

DataBar Stacked
Las versiones apiladas de los códigos GS1 Databar utilizan la misma codificación básica que los códigos Linear Databar, descritos anteriormente, y se utilizan en aplicaciones similares. Son particularmente útiles para artículos de espacio limitado con etiquetas que tienen dimensiones lineales muy estrechas.,
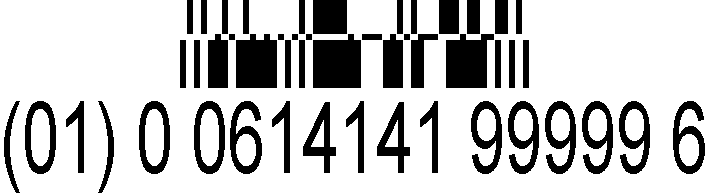
el GS1 Expanded Stacked Databar puede apilar una serie de códigos de barras que contienen datos de productos además del código de precio básico del punto de venta EAN-13.
PDF417
PDF417 es un código de barras apiladas de altura variable, ancho variable compuesto por filas de barras cortas y espacios. Puede tener tan pocas como 3 filas, o tantas como 90. Todas las filas deben contener el mismo número de palabras de código de datos, pero ese número puede variar de 1 a 30.,

el método real de codificación se basa en un sistema complejo que utiliza aproximadamente 900 palabras de código para representar datos en diferentes formatos. Esto permite al PDF417 codificar texto, datos digitales (en bytes) y grandes números dentro del mismo código de barras. cada fila de un código de barras PDF417 consiste en un patrón de inicio, la palabra de código de la izquierda (identificando la fila, entre otras cosas), las palabras de código de datos, la palabra de código de la derecha y el patrón de parada. A diferencia de la mayoría de los códigos de barras 2D, el PDF417 se puede leer con un escáner láser., los códigos de barras PDF417 se pueden vincular para que se puedan escanear grandes cantidades de datos en secuencia. Esto elimina efectivamente el límite en la cantidad de datos que se pueden codificar, haciendo que el formato PDF417 sea competitivo con los códigos de barras 2-D verdaderos para representar grandes cantidades de datos.
El PDF417 está en uso como un formato de código de barras de alta densidad en una serie de aplicaciones, incluyendo:
MicroPDF417
MicroPDF417 es un subconjunto limitado de PDF417 diseñado para situaciones en las que un código PDF417 completo sería demasiado grande. Pone límites en las dimensiones de las barras, y en la cantidad y el formato de los datos que se pueden codificar (hasta 200 caracteres de texto en mayúsculas, 150 bytes binarios o 366 dígitos numéricos). también pone algunas restricciones en las palabras de código de corrección de errores.
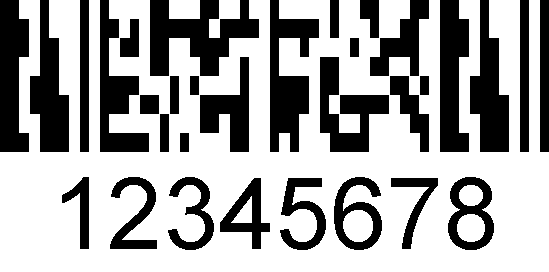
MicroPDF417 se utiliza en códigos compuestos GS1 Databar, donde se combina con un código de barras lineal.,
matriz 2D
a diferencia de los códigos de barras apilados, los códigos de matriz 2D verdaderos representan datos en una matriz bidimensional, como cuadrados en un tablero de ajedrez. Esto les permite empaquetar una gran cantidad de datos en un espacio compacto y representar un conjunto de caracteres mucho más grande. Estos códigos deben leerse con un escáner de imágenes, en lugar de con un escáner láser.
DataMatrix
Los códigos de barras DataMatrix son matrices cuadradas o rectangulares de cuadrados o celdas en blanco y negro., Cada celda es un bit, representando un uno o un cero, y dependiendo del tipo de codificación, un código de barras DataMatrix puede representar hasta 2,355 caracteres alfanuméricos.

un código DataMatrix tiene dos tipos diferentes de borde; en un conjunto de lados adyacentes, el borde es sólido, y en los otros dos lados, alterna celdas blancas y negras, lo que le da la apariencia de tener solo los dos bordes sólidos., Los bordes sólidos, o finder, permiten al escáner orientar la imagen del código, mientras que los bordes de celda alterna, o temporizador, le permiten contar las filas y columnas.
Los códigos DataMatrix pueden ser extremadamente pequeños, y se pueden leer con bajo contraste. Esto permite imprimirlos o incluso grabarlos con láser en artículos pequeños. También se pueden ampliar a un tamaño muy grande para su uso en artículos como maquinaria pesada, edificios o vagones de ferrocarril.,
el sistema de codificación real es complejo, e incluye almacenamiento redundante de datos, por lo que si parte de un código DataMatrix se pierde o se daña, todavía puede ser posible leer todos los datos. DataMatrix puede codificar números y caracteres ASCII alfanuméricos utilizando varios sistemas de codificación y compresión.
DataMatrix se utiliza para el etiquetado de pequeños componentes en la industria electrónica, ya sea con etiquetas impresas, o marcado DIRECTO; también se utilizan en la industria alimentaria para el control de calidad.,La mayoría de los teléfonos inteligentes pueden leer códigos DataMatrix, lo que les permite ser utilizados para marketing, publicidad y otras aplicaciones donde el acceso de teléfonos inteligentes es deseable.
código QR
el formato de código QR (o Respuesta Rápida) fue diseñado originalmente para su uso en la industria automotriz japonesa para realizar un seguimiento de las piezas y de los automóviles en la línea de montaje. Debido a su versatilidad, se ha utilizado ampliamente en una variedad de aplicaciones industriales y orientadas al consumidor.,

un código QR se asemeja a un código DataMatrix; es cuadrado (rodeado por una zona bastante en blanco), y consiste en celdas cuadradas en blanco y negro. Pero en lugar de bordes, utiliza un conjunto de cuadrados grandes de posición y alineación (y un conjunto más pequeño de marcas de tiempo) dentro del cuerpo del código.
el código QR puede codificar cuatro tipos diferentes de Datos: números, caracteres alfanuméricos, binarios/bytes y kana/kanji japonés., La codificación alfanumérica se limita a números, letras mayúsculas y algunos signos de puntuación, pero la codificación binaria/byte incluye el conjunto de caracteres ISO 8859-1 Latin-1, que cubre total o parcialmente los idiomas de Europa Occidental. La codificación Kana/kanji utiliza el conjunto de caracteres JIS X 0208. El código QR puede codificar URL de sitios web, lo que permite a los usuarios de teléfonos móviles dar like directamente a un sitio web escaneando su URL codificada.
El tamaño y la densidad de un código QR pueden variar, dependiendo de la cantidad de datos a almacenar., La capacidad máxima de almacenamiento es de aproximadamente 7.000 caracteres numéricos, 4.200 caracteres alfanuméricos, 2.900 caracteres binarios o 1.800 caracteres kana/kanji. Un código QR se puede dividir en varios códigos más pequeños, lo que les permite encajar en un área en la que un código más grande no encajaría.
Los códigos QR han visto un rápido aumento en el número y la gama de aplicaciones para las que se utilizan en los últimos años, en parte porque pueden ser fácilmente leídos por teléfonos inteligentes, tabletas y otros dispositivos móviles., Las aplicaciones actuales de código QQR incluyen:
la versatilidad, capacidad y accesibilidad del Código QR le permite ser utilizado en una variedad de formas inusuales., Los códigos QR se han incluido en obras de arte, sellos, dinero, lápidas, estatuas, exhibiciones de museos, rutas de senderismo, portadas de cómics, tarjetas de felicitación, casi en cualquier lugar que puedan caber y servir para algún tipo de función.
Las patentes del Código QR son propiedad de Denso Wave (una subsidiaria de Denso, que a su vez es propiedad de Toyota), que ha optado por no ejercer sus derechos de patente, y permite el uso de los códigos sin ningún requisito de licencia.además de las aplicaciones de lectura de códigos QR, el software gratuito y los servicios basados en la web para generar códigos QR están fácilmente disponibles.,
Aztec
el código de barras Aztec 2D se asemeja a los códigos DataMatrix y QR. Consiste en un cuadrado de celdas blancas y negras (o píxeles) con un símbolo de ubicación hecho de cuadrados concéntricos directamente en el centro. El área central (alrededor de la diana cuadrada) contiene información sobre el tamaño del símbolo, junto con otros datos de codificación. Esto significa que no requiere una zona en blanco o un límite. El código también contiene una cuadrícula de referencia interna de píxeles negros/blancos alternados en cada fila y columna 16.,

Los datos están dispuestos en una espiral desde el centro hacia fuera; cada capa de la espiral se compone de dos anillos de píxeles, agregando cuatro píxeles al ancho total. El cuadrado central más la capa de datos de codificación y tamaño juntos forman el núcleo, que puede ser compacto (11 X 11) o completo (15 X 15). Un símbolo Azteca con un núcleo compacto puede tener hasta 4 capas. Un símbolo con un núcleo completo puede tener 32 capas y puede codificar más de 3.800 dígitos, 3.000 caracteres de texto o 1.900 bytes de datos binarios., El texto se puede codificar como ASCII y Latin-1; el modo de codificación se puede cambiar en varios puntos dentro de los datos.
El sistema de código Aztec es de dominio público, y hay aplicaciones disponibles para generar códigos y leerlos en dispositivos móviles. Dada la similitud en diseño, legibilidad y capacidad, los códigos aztecas podrían usarse en muchas de las aplicaciones para las que los códigos QR se están volviendo populares, aunque en la práctica, su uso es más limitado.
Los códigos aztecas son, sin embargo, bastante comunes en la industria del transporte., Se utilizan en las tarjetas de embarque electrónicas de las líneas aéreas y en los billetes de tren en línea y móviles en muchas partes de Europa. además, se utilizan en los sistemas de facturación de varias corporaciones canadienses, y el gobierno polaco Los utiliza en su sistema de registro de automóviles.
Maxicode
MaxiCode es un código de barras de matriz 2D que se parece un poco al Código Azteca, solo que con un centro redondo en lugar de uno cuadrado. Una mirada más cercana muestra otra diferencia: en lugar de píxeles cuadrados, los datos están codificados en puntos hexagonales que están dispuestos en un patrón hexagonal.,

MaxiCode fue diseñado para una función especializada-routing and tracking United Parcel Service packages-y que sigue siendo su uso principal. a diferencia de los otros códigos de matriz 2D descritos aquí, los símbolos MaxiCode tienen un tamaño fijo (aproximadamente 1 pulgada cuadrada) y una cantidad fija de datos que pueden codificarse (aproximadamente 93 caracteres, dependiendo del modo de datos). Como muchos otros, 8 símbolos MaxiCode pueden estar enlazados o encadenados.,
hay cinco modos de datos en uso actual (así como dos modos obsoletos):
Todos estos modos pueden incluir un mensaje secundario, que para el envío de UPS generalmente contiene información de envío y seguimiento más detallada. En los modos 4, 5 y 6, el mensaje secundario se fusiona efectivamente con el mensaje primario.
MaxiCode utiliza cinco conjuntos de código; un solo mensaje puede cambiar entre ellos repetidamente. Los cinco conjuntos de código juntos incluyen el conjunto de caracteres ASCII estándar más la mayoría de los caracteres latinos-1.