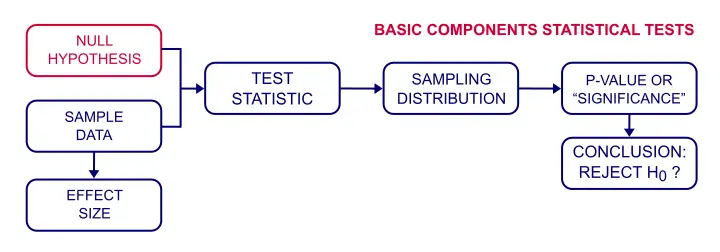
una hipótesis nula es una declaración precisa sobre una población que tratamos de rechazar con datos de muestra.Normalmente no creemos que nuestra hipótesis nula (o H0) sea verdadera. Sin embargo, necesitamos alguna declaración exacta como punto de partida para las pruebas de significación estadística.
ejemplos de hipótesis nula
a menudo, pero no siempre, la hipótesis nula establece que no hay asociación o diferencia entre variables o subpoblaciones., Así, algunas hipótesis nulas típicas son:
- La correlación entre frustración y agresión es cero (análisis de correlación);
- El ingreso promedio para los hombres es similar al de las mujeres (prueba t de muestras independientes);
- La nacionalidad no está (perfectamente) relacionada con la preferencia musical (prueba de independencia chi-cuadrado);
- El ingreso promedio de la población fue igual entre 2012 y 2016 (medidas repetidas ANOVA).
«Null» No Significa «Cero»
Un malentendido común es que «null» implica «cero». Este es a menudo, pero no siempre el caso., Por ejemplo, una hipótesis nula también puede afirmar que la correlación entre frustración y agresión es 0.5.No cero implicado aquí y – aunque algo inusual-perfectamente válido.
el «nulo » en» hipótesis nula «deriva de» nullify » 5: la hipótesis nula es la declaración que estamos tratando de refutar, independientemente de si especifica (no) un efecto cero.
prueba de hipótesis nula – ¿cómo funciona?
Quiero saber si la felicidad está relacionada con la riqueza entre los holandeses. Un enfoque para averiguar esto, es formular una hipótesis nula., Dado que «relacionado con» no es preciso, elegimos la afirmación opuesta como nuestra hipótesis nula:la correlación entre riqueza y felicidad es cero entre todos los holandeses.Ahora trataremos de refutar esta hipótesis para demostrar que la felicidad y la riqueza están relacionadas.
ahora, no podemos razonablemente preguntar a todos los 17,142,066 holandeses lo felices que generalmente se sienten.

así que vamos a pedir una muestra (digamos, 100 personas) sobre su riqueza y su felicidad. La correlación entre felicidad y riqueza resulta ser 0.25 en nuestra muestra., Ahora tenemos un problema: los resultados de la muestra tienden a diferir un poco de los resultados de la población. Así que si la correlación realmente es cero en nuestra población, podemos encontrar una correlación no cero en nuestra muestra. Para ilustrar este punto importante, echa un vistazo a la gráfica de dispersión a continuación. Visualiza una correlación cero entre felicidad y riqueza para toda una población de N = 200.

ahora dibujamos una muestra aleatoria de N = 20 de esta población (los puntos rojos en nuestra gráfica de dispersión anterior). A pesar de que nuestra correlación de población es cero, encontramos un asombroso 0.,82 correlación en nuestra muestra. La siguiente figura ilustra esto omitiendo todas las unidades no muestreadas de nuestra gráfica de dispersión anterior.

esto plantea la pregunta de cómo podemos decir algo sobre nuestra población si solo tenemos una pequeña muestra de ella. La respuesta básica: rara vez podemos decir nada con 100% de certeza. Sin embargo, podemos decir mucho con 99%, 95% o 90% de certeza.
Probabilidad
Entonces, ¿cómo funciona eso? Bueno, básicamente, algunos resultados de la muestra son muy poco probable dada nuestra hipótesis nula., Así, la siguiente figura muestra las probabilidades para diferentes correlaciones de muestra (N = 100) si la correlación de la población es realmente cero.

Una computadora fácilmente calcular estas probabilidades. Sin embargo, hacerlo requiere un tamaño muestral (100 en nuestro caso) y una supuesta correlación poblacional ρ (0 en nuestro caso). Por eso necesitamos una hipótesis nula.
Si miramos esta distribución de muestreo cuidadosamente, vemos que las correlaciones de la muestra alrededor de 0 son más probables: hay una probabilidad de 0.68 de encontrar una correlación entre -0.1 y 0.1. ¿Qué significa eso?, Bueno, recuerde que las probabilidades pueden verse como frecuencias relativas. Así que imaginen que dibujaríamos 1.000 muestras en lugar de la que tenemos. Esto daría lugar a 1.000 coeficientes de correlación y unos 680 de ellos – una frecuencia relativa de 0,68-estarían en el rango de -0,1 a 0,1. Del mismo modo, hay una probabilidad de 0.95 (o 95%) de encontrar una correlación de muestra entre -0.2 y 0.2.
valores de P
se encontró una correlación muestral de 0,25. ¿Qué tan probable es que si la correlación de la población es cero?, La respuesta se conoce como el valor p (abreviatura de valor de probabilidad):un valor p es la probabilidad de encontrar algún resultado de la muestra o uno más extremo si la hipótesis nula es verdadera.Dada nuestra correlación de 0.25,» más extremo » generalmente significa mayor que 0.25 o menor que -0.25. No podemos decir de nuestro gráfico, pero la tabla subyacente nos dice que p ≈ 0.012. Si la hipótesis nula es verdadera, hay una probabilidad del 1.2% de encontrar nuestra correlación de la muestra.
Conclusión?
si nuestra correlación poblacional es realmente cero, entonces podemos encontrar una correlación muestral de 0.25 en una muestra de N = 100., La probabilidad de que esto suceda es solo 0.012 por lo que es muy poco probable. Una conclusión razonable es que nuestra correlación de población no era cero después de todo.conclusión: rechazamos la hipótesis nula. Dado el resultado de nuestra muestra, ya no creemos que la felicidad y la riqueza no estén relacionadas. Sin embargo, todavía no podemos afirmar esto con certeza.
hipótesis nula – limitaciones
hasta ahora, solo concluimos que la correlación poblacional probablemente no es cero. Esa es la única conclusión de nuestro enfoque de hipótesis nula y no es realmente tan interesante.,lo que realmente queremos saber es la correlación poblacional. Nuestra correlación muestral de 0,25 parece una estimación razonable. Llamamos a tal Número una estimación puntual.
Ahora, una nueva muestra puede llegar a una correlación diferente. Una pregunta interesante es cuánto fluctuarían nuestras correlaciones de muestra sobre las muestras si dibujáramos muchas de ellas. La siguiente figura muestra precisamente eso, asumiendo nuestro tamaño muestral de N = 100 y nuestra estimación (punto) de 0.25 para la correlación poblacional.,

intervalos de confianza
nuestro resultado de la muestra sugiere que alrededor del 95% de muchas muestras deberían llegar a una correlación entre 0,06 y 0,43. Este rango se conoce como intervalo de confianza. Aunque no es exactamente correcto, es más fácil de como el ancho de banda que es probable que encierre la correlación de la población.
Una cosa a tener en cuenta es que el intervalo de concidencia es bastante amplio. Casi contiene una correlación cero, exactamente la hipótesis nula que rechazamos anteriormente.,
otra cosa a tener en cuenta es que nuestra distribución de muestreo y el intervalo de confianza son ligeramente asimétricos. Son simétricos para la mayoría de las otras estadísticas (como medias o coeficientes beta), pero no correlaciones.