Descripción general
- La precisión y la recuperación son dos temas cruciales pero incomprendidos en el aprendizaje automático
- discutiremos qué son la precisión y la recuperación, cómo funcionan y su papel en la evaluación de un modelo de aprendizaje automático
- también obtendremos una comprensión del área bajo la curva (AUC) y los Términos de precisión
Introducción
acerca de los conceptos más confusos en su viaje de aprendizaje., E invariablemente, la respuesta gira hacia la precisión y el recuerdo.
la diferencia entre precisión y recuerdo es realmente fácil de recordar, pero solo una vez que haya entendido realmente lo que significa cada término. Pero muy a menudo, y puedo dar fe de esto, los expertos tienden a ofrecer explicaciones a medias que confunden aún más a los recién llegados.
así que vamos a dejar las cosas claras en este artículo.

para cualquier modelo de aprendizaje automático, sabemos que lograr un ‘buen ajuste’ en el modelo es extremadamente crucial., Esto implica lograr el equilibrio entre el subajuste y el sobreajuste, o en otras palabras, una compensación entre sesgo y varianza.
sin embargo, cuando se trata de la clasificación, hay otra compensación que a menudo se pasa por alto a favor de la compensación sesgo – varianza. Este es el compromiso precisión-retiro. Las clases desequilibradas ocurren comúnmente en conjuntos de datos y cuando se trata de casos de uso específicos, de hecho, nos gustaría dar más importancia a las métricas de precisión y recuperación, y también cómo lograr el equilibrio entre ellas.
Pero, ¿cómo hacerlo?, Exploraremos las métricas de evaluación de clasificación centrándose en la precisión y el recuerdo en este artículo. También aprenderemos cómo calcular estas métricas en Python tomando un conjunto de datos y un algoritmo de clasificación simple. Así que, vamos a empezar!
Puede obtener información detallada sobre las métricas de evaluación aquí: métricas de evaluación para modelos de aprendizaje automático.
tabla de contenidos
- entendiendo la declaración del problema
- ¿Qué es la precisión?
- ¿Qué es el Recuerdo?,
- La métrica de evaluación más fácil – precisión
- El papel de la puntuación de F1
- La famosa compensación de recuperación de precisión
- Comprender el área bajo la curva (AUC)
comprender la declaración del problema
creo firmemente en aprender haciendo. Así que a lo largo de este artículo, hablaremos en términos prácticos, mediante el uso de un conjunto de datos.
tomemos el popular conjunto de datos de enfermedades cardíacas disponible en el repositorio UCI. Aquí, tenemos que predecir si el paciente está sufriendo de una dolencia cardíaca o no utilizando el conjunto dado de características., Puede descargar el conjunto de datos limpio desde aquí.
dado que este artículo se centra únicamente en las métricas de evaluación de modelos, usaremos el clasificador más simple: el modelo de clasificación kNN para hacer predicciones.
Como siempre, vamos a empezar por la importación de las librerías necesarias y paquetes:
Entonces vamos a echar un vistazo a los datos y las variables objetivo que nos ocupa:
Vamos a comprobar si tenemos los valores que faltan:
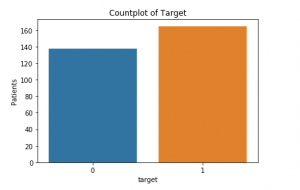
no Hay valores perdidos., Ahora podemos echar un vistazo a cuántos pacientes están sufriendo realmente de enfermedad cardíaca (1) y cuántos no lo están (0):
Este es el gráfico de conteo a continuación:
procedamos dividiendo nuestros datos de entrenamiento y pruebas y nuestras variables de entrada y objetivo. Dado que estamos usando KNN, es obligatorio escalar nuestros conjuntos de datos también:
la intuición detrás de elegir el mejor valor de k está más allá del alcance de este artículo, pero debemos saber que podemos determinar el valor óptimo de k cuando obtenemos la puntuación más alta de la prueba para ese valor., Para ello, podemos evaluar las puntuaciones de entrenamiento y pruebas de hasta 20 vecinos más cercanos:
para evaluar la puntuación máxima de la prueba y los valores de k asociados a ella, ejecute el siguiente comando:

así, hemos obtenido el valor óptimo de k para ser 3, 11 o 20 con una puntuación de 83.5. Finalizaremos uno de estos valores y ajustaremos el modelo en consecuencia:

ahora, ¿cómo evaluamos si este modelo es un modelo ‘bueno’ o no?, Para eso, usamos algo llamado matriz de confusión:
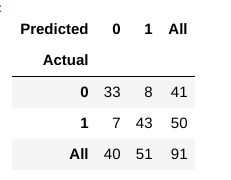
una matriz de confusión nos ayuda a obtener una idea de cuán correctas fueron nuestras predicciones y cómo se sostienen contra los valores reales.
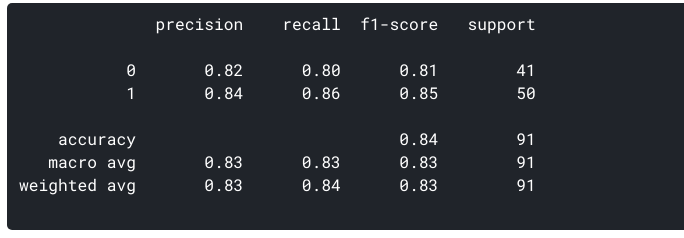
de nuestros datos de tren y prueba, ya sabemos que nuestros datos de prueba consistieron en 91 puntos de datos. Ese es el valor de la 3ra fila y 3ra columna al final. También notamos que hay algunos valores reales y predichos. Los valores reales son el número de puntos de datos que se categorizaron originalmente en 0 o 1., Los valores predichos son el número de puntos de datos que nuestro modelo KNN predijo como 0 o 1.
los valores reales son:
- Los pacientes que realmente no tienen una enfermedad cardíaca = 41
- Los pacientes que realmente tienen una enfermedad cardíaca = 50
los valores predichos son:
- Número de pacientes que se predijo que no tienen una enfermedad cardíaca = 40
- Número de pacientes que se predijo que tienen una enfermedad cardíaca = 51
todos los valores que obtenemos arriba tienen un término., Vamos a repasarlos uno por uno:
- los casos en los que los pacientes en realidad no tenían enfermedad cardíaca y nuestro modelo también predijo que no la tenían se llaman los verdaderos negativos. Para nuestra matriz, verdaderos negativos = 33.
- los casos en los que los pacientes realmente tienen enfermedad cardíaca y nuestro modelo también predijo que la tienen se llaman los verdaderos positivos. Para nuestra matriz, verdaderos positivos = 43
- sin embargo, hay algunos casos en los que el paciente realmente no tiene enfermedad cardíaca, pero nuestro modelo ha predicho que sí., Este tipo de error es el Error de Tipo I y llamamos a los valores como falsos positivos. Para nuestra matriz, falsos positivos = 8
- Del mismo modo, hay algunos casos en los que el paciente realmente tiene enfermedad cardíaca, pero nuestro modelo ha predicho que él/ella no. este tipo de error es el Error tipo II y llamamos a los valores como falsos negativos. Para nuestra matriz, falsos negativos = 7
¿Qué es la precisión?
derecha – así que ahora llegamos al quid de este artículo. ¿Qué es la precisión? ¿Y qué tiene que ver todo el aprendizaje anterior?,
en los términos más simples, la precisión es la relación entre los positivos verdaderos y todos los positivos. Para nuestra Declaración del problema, esa sería la medida de los pacientes que identificamos correctamente que tienen una enfermedad cardíaca de todos los pacientes que realmente la tienen. Matemáticamente:

¿Cuál es la Precisión para nuestro modelo? Sí, es 0,843 o, cuando predice que un paciente tiene una enfermedad cardíaca, es correcto alrededor del 84% de las veces.
La precisión también nos da una medida de los puntos de datos relevantes., Es importante que no comencemos a tratar a un paciente que en realidad no tiene una dolencia cardíaca, pero nuestro modelo predijo que la tiene.
¿qué es el recuerdo?
El recall es la medida de nuestro modelo que identifica correctamente los verdaderos positivos. Por lo tanto, para todos los pacientes que realmente tienen una enfermedad cardíaca, el recuerdo nos dice cuántos identificamos correctamente como que tienen una enfermedad cardíaca. Matemáticamente:

Para nuestro modelo, Recordemos = 0.86. Recall también da una medida de la precisión con la que nuestro modelo es capaz de identificar los datos relevantes., Nos referimos a ella como sensibilidad o tasa positiva verdadera. ¿Qué pasa si un paciente tiene una enfermedad cardíaca, pero no se le administra tratamiento porque nuestro modelo lo predijo? Que es una situación que nos gustaría evitar!
la métrica más fácil de entender – precisión
Ahora llegamos a una de las métricas más simples de todas, la precisión. La precisión es la relación entre el número total de predicciones correctas y el número total de predicciones. ¿Puedes adivinar cuál será la fórmula de precisión?
![]()
Para nuestro modelo, la Precisión será = 0.835.,
usar la precisión como una métrica definitoria para nuestro modelo tiene sentido intuitivamente, pero la mayoría de las veces, siempre es aconsejable usar precisión y recuperación también. Puede haber otras situaciones donde nuestra precisión es muy alta, pero nuestra precisión o recuerdo es baja. Idealmente, para nuestro modelo, nos gustaría evitar completamente cualquier situación en la que el paciente tenga enfermedad cardíaca, pero nuestro modelo clasifica como él no lo tiene, es decir, apunta a un alto recuerdo.,
por otro lado, para los casos en los que el paciente no está sufriendo de enfermedad cardíaca y nuestro modelo predice lo contrario, también nos gustaría evitar tratar a un paciente sin enfermedades cardíacas(crucial cuando los parámetros de entrada podrían indicar una dolencia diferente, pero terminamos tratándolo por una dolencia cardíaca).
aunque nuestro objetivo es la alta precisión y el alto valor de recuperación, lograr ambos al mismo tiempo no es posible., Por ejemplo, si cambiamos el modelo a uno que nos dé un alto recuerdo, podríamos detectar a todos los pacientes que realmente tienen una enfermedad cardíaca, pero podríamos terminar dando tratamientos a muchos pacientes que no la padecen.
del mismo modo, si buscamos una alta precisión para evitar dar cualquier tratamiento incorrecto y no requerido, terminamos recibiendo muchos pacientes que realmente tienen una enfermedad cardíaca sin ningún tratamiento.
El papel de la puntuación F1
comprender la precisión nos hizo darnos cuenta de que necesitamos un equilibrio entre precisión y recuperación., Primero tenemos que decidir cuál es más importante para nuestro problema de clasificación.
por ejemplo, para nuestro conjunto de datos, podemos considerar que lograr un alto recuerdo es más importante que obtener una alta precisión: nos gustaría detectar tantos pacientes cardíacos como sea posible. Para algunos otros modelos, como clasificar si un cliente del banco es un moroso de préstamo o no, es deseable tener una alta precisión ya que el banco no querría perder clientes a los que se les negó un préstamo basado en la predicción del modelo de que serían morosos.,
también hay muchas situaciones en las que tanto la precisión como el recuerdo son igualmente importantes. Por ejemplo, para nuestro modelo, si el médico nos informa que los pacientes que fueron clasificados incorrectamente como que sufren de enfermedad cardíaca son igualmente importantes ya que podrían ser indicativos de alguna otra dolencia, entonces apuntaríamos no solo a un alto recuerdo sino también a una alta precisión.
en tales casos, usamos algo llamado F1-score., F1-score es la media armónica de la precisión y el recuerdo:

esto es más fácil de trabajar ya que ahora, en lugar de equilibrar la precisión y el recuerdo, solo podemos apuntar a una buena puntuación de F1 y eso sería indicativo de una buena precisión y un buen valor de recuerdo también.,
podemos generar las métricas anteriores para nuestro conjunto de datos usando sklearn también:
curva ROC
junto con los términos anteriores, hay más valores que podemos calcular desde la matriz de confusión:
- tasa de falsos positivos (FPR): es la relación de los falsos positivos positivos al número real de negativos. En el contexto de nuestro modelo, es una medida de cuántos casos el modelo predice que el paciente tiene una enfermedad cardíaca de todos los pacientes que en realidad no tenían la enfermedad cardíaca. Para nuestros datos, el FPR es = 0.,195
- tasa negativa verdadera (TNR) o la especificidad: es la relación entre los negativos verdaderos y el número real de negativos. Para nuestro modelo, es la medida de cuántos casos predijo correctamente el modelo que el paciente no tiene enfermedad cardíaca de todos los pacientes que en realidad no tenían enfermedad cardíaca. El TNR para los datos anteriores = 0.804. A partir de estas 2 definiciones, también podemos concluir que especificidad o TNR = 1 – FPR
también podemos visualizar precisión y recuperación utilizando curvas ROC y curvas PRC.,
curvas ROC(curva característica de funcionamiento del receptor):
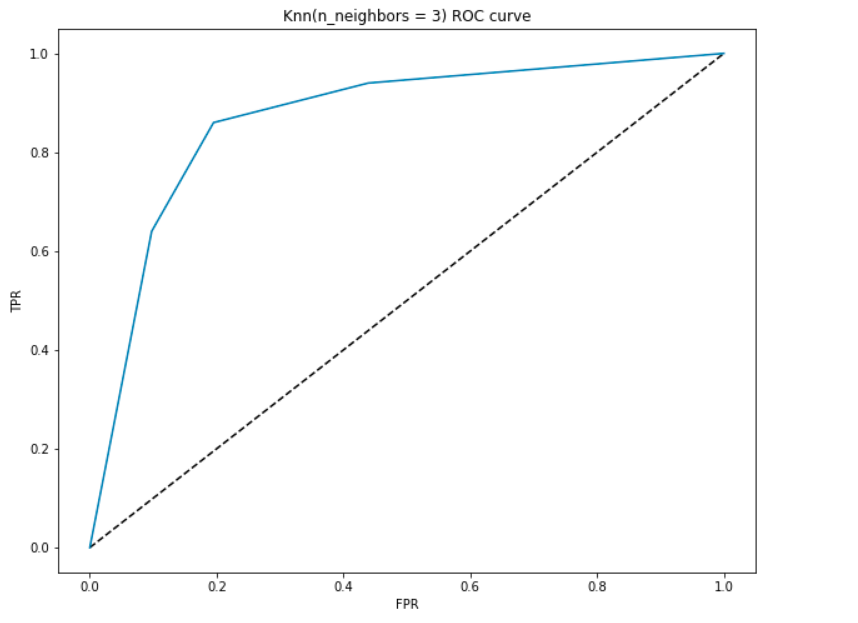
es la gráfica entre el TPR(eje y) y el FPR (eje x). Dado que nuestro modelo clasifica al paciente como con enfermedad cardíaca o no en función de las probabilidades generadas para cada clase, también podemos decidir el umbral de las probabilidades.
Por ejemplo, queremos establecer un valor umbral de 0.4. Esto significa que el modelo clasificará el punto de datos / paciente como con enfermedad cardíaca si la probabilidad de que el paciente tenga una enfermedad cardíaca es mayor que 0.4., Esto obviamente dará un alto valor de recuperación y reducirá el número de falsos positivos. De manera similar, podemos visualizar cómo funciona nuestro modelo para diferentes valores de umbral utilizando la curva ROC.
generemos una curva ROC para nuestro modelo con k = 3.
interpretación AUC –
- En el punto más bajo, es decir, en (0, 0) – el umbral se establece en 1.0. Esto significa que nuestro modelo clasifica a todos los pacientes como no tener una enfermedad cardíaca.
- En el punto más alto, es decir, en (1, 1), el umbral se establece en 0.0., Esto significa que nuestro modelo clasifica a todos los pacientes como que tienen una enfermedad cardíaca.
- El resto de la curva son los valores de FPR y TPR para los valores de umbral entre 0 y 1. En algún valor umbral, observamos que para FPR cerca de 0, estamos logrando un TPR de cerca de 1. Esto es cuando el modelo predecirá los pacientes que tienen enfermedad cardíaca casi perfectamente.
- El área con la curva y los ejes como los límites se llama el área bajo curva (AUC). Es esta área la que se considera como una métrica de un buen modelo., Con esta métrica que va de 0 a 1, debemos apuntar a un alto valor de AUC. Los modelos con un alto AUC se llaman modelos con buena habilidad. Calculemos la puntuación AUC de nuestro modelo y la gráfica anterior:

- obtenemos un valor de 0.868 como el AUC que es una puntuación bastante buena! En términos más simples, esto significa que el modelo será capaz de distinguir a los pacientes con enfermedad cardíaca y aquellos que no lo hacen el 87% de las veces. Podemos mejorar esta puntuación y le insto a probar diferentes valores de hiperparámetro.,
- La línea diagonal es un modelo Aleatorio con un AUC de 0.5, un modelo Sin habilidad, que es lo mismo que hacer una predicción aleatoria. ¿Puedes adivinar por qué?
curva de recuperación de precisión (PRC)
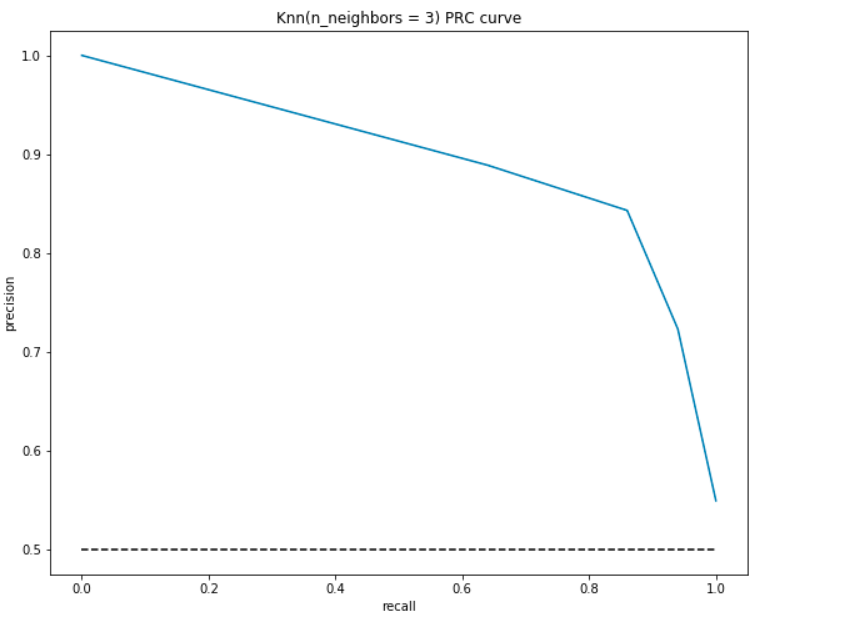
como su nombre indica, esta curva es una representación directa de la precisión(eje y) y la recuperación(eje x). Si observa nuestras definiciones y fórmulas para la precisión y el recuerdo anteriores, notará que en ningún momento estamos usando los verdaderos negativos(el número real de personas que no tienen enfermedad cardíaca).,
esto es particularmente útil para las situaciones en las que tenemos un conjunto de datos desequilibrado y el número de negativos es mucho mayor que los positivos(o cuando el número de pacientes que no tienen enfermedad cardíaca es mucho mayor que los pacientes que la tienen). En tales casos, nuestra mayor preocupación sería detectar a los pacientes con cardiopatía lo más correctamente posible y no necesitaríamos la TNR.
al igual que el ROC, trazamos la precisión y el recuerdo para diferentes valores de umbral:
interpretación de PRC:
- En el punto más bajo, es decir,, at (0, 0) – el umbral se establece en 1.0. Esto significa que nuestro modelo no hace distinciones entre los pacientes que tienen enfermedad cardíaca y los pacientes que no.
- En el punto más alto, es decir, en (1, 1), el umbral se establece en 0.0. Esto significa que tanto nuestra precisión como el recuerdo son altos y el modelo hace distinciones perfectamente.
- El resto de la curva son los valores de precisión y recuperación para los valores de umbral entre 0 y 1. Nuestro objetivo es hacer que la curva se acerque lo más posible a (1, 1), lo que significa una buena precisión y recuperación.,
- Similar a ROC, el área con la curva y los ejes como los límites es el área bajo curva (AUC). Considere esta área como una métrica de un buen modelo. El AUC oscila entre 0 y 1. Por lo tanto, debemos aspirar a un valor alto del AUC. Calculemos el AUC para nuestro modelo y el gráfico anterior:

como antes, obtenemos un buen AUC de alrededor del 90%. Además, el modelo puede lograr una alta precisión con recuperación como 0 y lograría una recuperación alta al comprometer la precisión del 50%.,
notas finales
Para concluir, en este artículo, vimos cómo evaluar un modelo de clasificación, especialmente centrado en la precisión y el recuerdo, y encontrar un equilibrio entre ellos. Además, explicamos cómo representar el rendimiento de nuestro modelo utilizando diferentes métricas y una matriz de confusión.
Aquí hay un artículo adicional para que entienda las métricas de evaluación: 11 métricas de Evaluación de modelos importantes para el aprendizaje automático que todos deben conocer