Présentation
- la Précision et le rappel sont deux crucial encore mal compris des sujets dans l’apprentissage de la machine
- Nous allons discuter de ce que la précision et le rappel sont, comment ils fonctionnent, et leur rôle dans l’évaluation d’un apprentissage de la machine modèle
- Nous allons également avoir une compréhension de l’Aire Sous la Courbe (ASC) et la Précision des termes
Introduction
Demandez à n’importe quelle machine d’apprentissage professionnel ou de données scientifique sur la plus déroutante des concepts dans leur parcours d’apprentissage., Et invariablement, la réponse vire vers la précision et le rappel.
la différence entre précision et rappel est en fait facile à retenir – mais seulement une fois que vous avez vraiment compris ce que chaque terme signifie. Mais très souvent, et je peux en témoigner, les experts ont tendance à offrir des explications à moitié cuites qui déroutent encore plus les nouveaux arrivants.
alors mettons les choses au clair dans cet article.

Pour toute machine modèle d’apprentissage, nous savons que la réalisation d’un » bon » sur le modèle est extrêmement crucial., Cela implique d’atteindre l’équilibre entre le sous-ajustement et le sur-ajustement, ou en d’autres termes, un compromis entre le biais et la variance.
Cependant, en ce qui concerne la classification – il y a un autre compromis qui est souvent négligé en faveur du compromis biais-variance. C’est le rappel et de précision compromis. Les classes déséquilibrées se produisent généralement dans les ensembles de données et lorsqu’il s’agit de cas d’utilisation spécifiques, nous aimerions en fait accorder plus d’importance aux mesures de précision et de rappel, ainsi qu’à la manière d’atteindre l’équilibre entre elles.
Mais, comment faire?, Nous explorerons les mesures d’évaluation de la classification en mettant l’accent sur la précision et le rappel dans cet article. Nous allons également apprendre à calculer ces métriques en Python en prenant un jeu de données et un algorithme de classification simple. Donc, nous allons commencer!
Vous pouvez en apprendre davantage sur les mesures d’évaluation en profondeur ici-mesures D’évaluation pour les modèles D’apprentissage automatique.
table des matières
- comprendre l’énoncé du problème
- Qu’est-ce que la précision?
- qu’est-Ce que le Rappel?,
- La mesure D’évaluation la plus simple – précision
- Le rôle du Score F1
- Le fameux compromis précision-rappel
- comprendre L’aire sous la courbe (AUC)
comprendre l’énoncé du problème
je crois fermement à l’apprentissage par la pratique. Donc, tout au long de cet article, nous parlerons en termes pratiques – en utilisant un ensemble de données.
reprenons le jeu de données populaire sur les maladies cardiaques disponible sur le référentiel UCI. Ici, nous devons prédire si le patient souffre d’une maladie cardiaque ou ne pas utiliser l’ensemble donné de caractéristiques., Vous pouvez télécharger le jeu de données propre à partir d’ici.
étant donné que cet article se concentre uniquement sur les mesures d’évaluation du modèle, nous utiliserons le classificateur le plus simple – le modèle de classification kNN pour faire des prédictions.
Comme toujours, nous allons commencer par importer les bibliothèques nécessaires et des paquets:
Ensuite, laissez-nous obtenir un regard sur les données et les variables de l’objet que nous traitons avec:
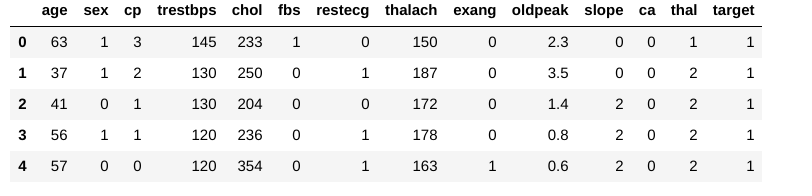
Laissez-nous vérifier si nous avons des valeurs manquantes:
Il n’y a pas de valeurs manquantes., Maintenant, nous pouvons regarder combien de patients souffrent réellement d’une maladie cardiaque (1) et combien ne le sont pas (0):
Voici le diagramme de comptage ci-dessous:
procédons en divisant nos données d’entraînement et de test et nos variables d’entrée et cibles. Puisque nous utilisons KNN, il est également obligatoire de mettre à l’échelle nos jeux de données:
l’intuition derrière le choix de la meilleure valeur de k dépasse le cadre de cet article, mais nous devons savoir que nous pouvons déterminer la valeur optimale de k lorsque nous obtenons le score de test le plus élevé pour cette valeur., Pour cela, nous pouvons évaluer la formation et les scores des tests jusqu’à 20 voisins les plus proches:
Pour évaluer le test de max score et les valeurs de k sont associés, exécutez la commande suivante:

Ainsi, nous avons obtenu la valeur optimale de k à 3, 11, ou 20 avec un score de 83,5. Nous finaliserons l’une de ces valeurs et adapterons le modèle en conséquence:

maintenant, comment évaluer si ce modèle est un » bon » modèle ou non?, Pour cela, nous utilisons quelque chose appelé une matrice de Confusion:
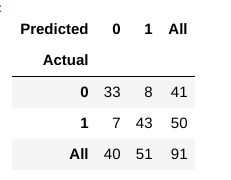
Une matrice de confusion nous aide à comprendre dans quelle mesure nos prédictions étaient correctes et comment elles résistent aux valeurs réelles.
D’après nos données de train et de test, nous savons déjà que nos données de test comprenaient 91 points de données. C’est la valeur de la 3ème ligne et de la 3ème colonne à la fin. Nous remarquons également qu’il existe des valeurs réelles et prédites. Les valeurs réelles sont le nombre de points de données qui ont été initialement classés en 0 ou 1., Les valeurs prédites sont le nombre de points de données que notre modèle KNN prédit comme 0 ou 1.
Les valeurs réelles sont:
- Les patients qui n’ont pas en réalité une maladie cardiaque = 41
- Les patients qui en fait ont une maladie cardiaque = 50
Les valeurs prédites sont:
- Nombre de patients qui ont été prédites de ne pas avoir une maladie du cœur = 40
- Nombre de patients qui ont été prédites comme ayant une maladie cardiaque = 51
Toutes les valeurs que nous obtenons ci-dessus ont un terme., Passons en revue un par un:
- les cas dans lesquels les patients n’avaient en fait pas de maladie cardiaque et notre modèle prédisait également qu’ils ne l’avaient pas sont appelés les vrais négatifs. Pour notre matrice, les vrais négatifs = 33.
- les cas dans lesquels les patients ont réellement une maladie cardiaque et notre modèle a également prédit que l’avoir sont appelés les vrais positifs. Pour notre matrice, vrais positifs = 43
- cependant, il y a certains cas où le patient n’a pas de maladie cardiaque, mais notre modèle a prédit qu’ils le font., Ce type d’erreur est L’erreur de Type I et nous appelons les valeurs comme faux positifs. Pour notre matrice, les faux positifs = 8
- De même, il y a certains cas où le patient a réellement une maladie cardiaque, mais notre modèle a prédit que non. ce genre d’erreur est L’erreur de Type II et nous appelons les valeurs comme faux négatifs. Pour notre matrice, les faux négatifs = 7
Qu’est-ce que la précision?
à droite-alors maintenant nous arrivons à l’essentiel de cet article. Qu’est-ce que la précision dans le monde? Et qu’est-ce que tout l’apprentissage ci-dessus a à voir avec cela?,
dans les termes les plus simples, la précision est le rapport entre les vrais positifs et tous les positifs. Pour notre Énoncé de problème, ce serait la mesure des patients que nous identifions correctement ayant une maladie cardiaque parmi tous les patients qui l’ont réellement. Mathématiquement:

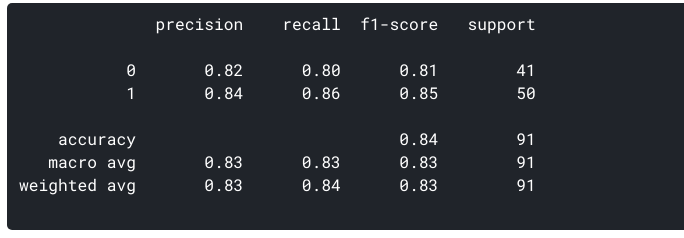
Quelle est la Précision de notre modèle? Oui, il est de 0,843 ou, quand il prédit qu’un patient a une maladie cardiaque, il est correct environ 84% du temps.
la précision nous donne également une mesure des points de données pertinents., Il est important que nous ne commencions pas à traiter un patient qui n’a pas de maladie cardiaque, mais notre modèle prédisait qu’il en avait.
Qu’est-ce que le rappel?
le rappel est la mesure de notre modèle identifiant correctement les vrais positifs. Ainsi, pour tous les patients qui ont réellement une maladie cardiaque, recall nous indique combien nous avons correctement identifié comme ayant une maladie cardiaque. Mathématiquement:

Pour notre modèle, Rappel = 0.86. Rappelons aussi donne une mesure de la précision de notre modèle est capable d’identifier les données pertinentes., Nous nous référons à elle comme sensibilité ou vrai taux positif. Que se passe – t-il si un patient a une maladie cardiaque, mais qu’aucun traitement ne lui est administré parce que notre modèle l’a prédit? C’est une situation que nous aimerions éviter!
la mesure la plus facile à comprendre – la précision
Nous arrivons maintenant à L’une des mesures les plus simples de toutes, la précision. La précision est le rapport du nombre total de prédictions correctes et le nombre total de prédictions. Pouvez-vous deviner quelle sera la formule de précision?
![]()
Pour notre modèle, l’Exactitude de la = 0.835.,
utiliser la précision comme métrique déterminante pour notre modèle a du sens intuitivement, mais le plus souvent, il est toujours conseillé d’utiliser la précision et le rappel. Il peut y avoir d’autres situations où notre précision est très élevée, mais notre précision ou notre rappel est faible. Idéalement, pour notre modèle, nous aimerions éviter complètement toutes les situations où le patient a une maladie cardiaque, mais notre modèle le classe comme ne pas l’avoir, c’est-à-dire viser un rappel élevé.,
en revanche, pour les cas où le patient ne souffre pas de maladie cardiaque et que notre modèle prédit le contraire, nous aimerions également éviter de traiter un patient sans maladie cardiaque(crucial lorsque les paramètres d’entrée pourraient indiquer une maladie différente, mais que nous finissons par le traiter pour une maladie cardiaque).
bien que nous visons une haute précision et une valeur de rappel élevée, atteindre les deux en même temps n’est pas possible., Par exemple, si nous changeons le modèle pour un modèle qui nous donne un rappel élevé, nous pourrions détecter tous les patients qui ont réellement une maladie cardiaque, mais nous pourrions finir par donner des traitements à beaucoup de patients qui n’en souffrent pas.
de même, si nous visons la haute précision pour éviter de donner un traitement erroné et non requis, nous finissons par obtenir beaucoup de patients qui ont réellement une maladie cardiaque sans aucun traitement.
le rôle de la F1-Score
comprendre la précision nous a fait réaliser, nous avons besoin d’un compromis entre précision et rappel., Nous devons d’abord décider lequel est le plus important pour notre problème de classification.
par exemple, pour notre ensemble de données, nous pouvons considérer qu’obtenir un rappel élevé est plus important que d’obtenir une haute précision – nous aimerions détecter autant de patients cardiaques que possible. Pour certains autres modèles, comme classer si un client de la banque est un défaut de prêt ou non, il est souhaitable d’avoir une grande précision car la banque ne voudrait pas perdre des clients qui se sont vu refuser un prêt en fonction de la prédiction du modèle selon laquelle ils seraient défaillants.,
Il y a aussi beaucoup de situations où la précision et le rappel sont tout aussi importants. Par exemple, pour notre modèle, si le médecin nous informe que les patients qui ont été classés à tort comme souffrant de maladie cardiaque sont tout aussi importants car ils pourraient indiquer une autre maladie, alors nous viserions non seulement un rappel élevé, mais aussi une grande précision.
Dans de tels cas, nous utilisons quelque chose appelé F1-score., F1-score est la moyenne harmonique de la précision et du rappel:

c’est plus facile à utiliser car maintenant, au lieu d’équilibrer la précision et le rappel, nous pouvons simplement viser un bon F1-score et cela indiquerait une bonne précision et une bonne valeur de rappel.,
nous pouvons également générer les métriques ci-dessus pour notre ensemble de données en utilisant sklearn:
courbe ROC
avec les termes ci-dessus, il y a plus de valeurs que nous pouvons calculer à partir de la matrice de confusion:
- taux de faux positifs au nombre réel de négatifs. Dans le contexte de notre modèle, il s’agit d’une mesure du nombre de cas dans lesquels le modèle prédit que le patient a une maladie cardiaque parmi tous les patients qui n’ont pas réellement eu la maladie cardiaque. Pour nos données, le FPR est = 0.,195
- taux négatif réel (TNR) ou spécificité: c’est le rapport entre les vrais négatifs et le nombre réel de négatifs. Pour notre modèle, c’est la façon dont de nombreux cas, le modèle prédire correctement les patients n’ont pas de maladie cardiaque de tous les patients qui n’ont pas de maladie cardiaque. Le TNR pour les données ci-dessus = 0,804. À partir de ces 2 définitions, nous pouvons également conclure que la spécificité ou TNR = 1 – FPR
Nous pouvons également visualiser la précision et le rappel en utilisant les courbes ROC et les courbes PRC.,
courbes ROC(courbe caractéristique de fonctionnement du récepteur):
c’est le tracé entre le TPR(axe y) et le FPR(axe x). Étant donné que notre modèle classe le patient comme ayant une maladie cardiaque ou non en fonction des probabilités générées pour chaque classe, nous pouvons également décider du seuil des probabilités.
Par exemple, nous voulons définir une valeur de seuil de 0,4. Cela signifie que le modèle classera le point de données / le patient comme ayant une maladie cardiaque si la probabilité que le patient ait une maladie cardiaque est supérieure à 0,4., Cela donnera évidemment une valeur de rappel élevée et réduira le nombre de faux positifs. De même, nous pouvons visualiser les performances de notre modèle pour différentes valeurs de seuil à l’aide de la courbe ROC.
générons une courbe ROC pour notre modèle avec k = 3.
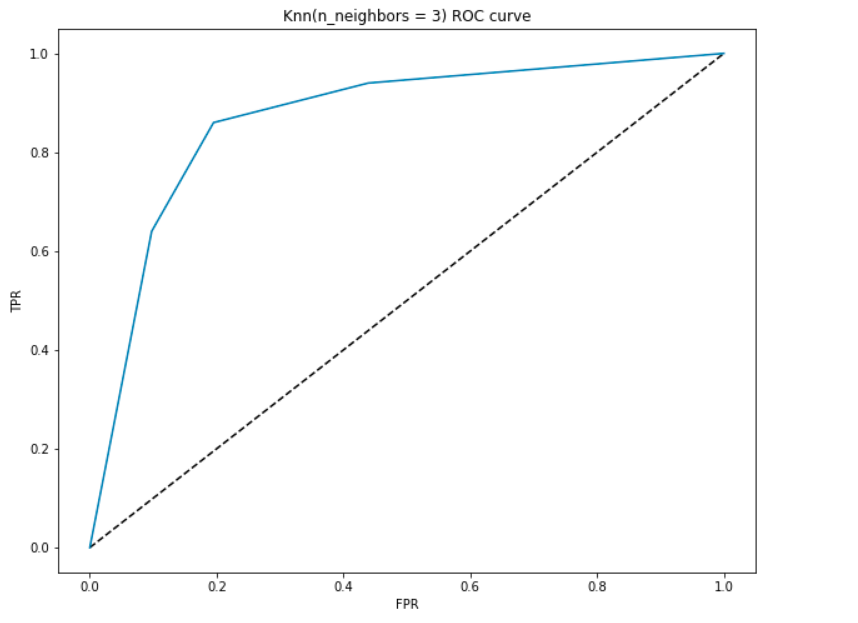
l’ASC de l’Interprétation-
- Au point le plus bas, c’est à dire à (0, 0)- le seuil est fixé à 1.0. Cela signifie que notre modèle classe tous les patients comme n’ayant pas de maladie cardiaque.
- Au plus haut point, c’est à dire à (1, 1), le seuil est fixé à 0.0., Cela signifie que notre modèle classe tous les patients comme ayant une maladie cardiaque.
- le reste de la courbe est les valeurs de FPR et TPR pour les valeurs seuils comprises entre 0 et 1. À une certaine valeur seuil, nous observons que pour un FPR proche de 0, nous obtenons un TPR proche de 1. C’est à ce moment que le modèle prédit presque parfaitement les patients atteints de maladie cardiaque.
- l’aire avec la courbe et les axes comme limites est appelée L’aire sous la courbe(AUC). C’est cette zone qui est considérée comme un indicateur d’un bon modèle., Avec cette métrique allant de 0 à 1, nous devrions viser une valeur élevée de L’ASC. Les modèles avec une AUC élevée sont appelés modèles avec une bonne compétence. Calculons le score AUC de notre modèle et le graphique ci-dessus:

- nous obtenons une valeur de 0.868 comme AUC ce qui est un très bon score! En termes simples, cela signifie que le modèle sera en mesure de distinguer les patients atteints de maladie cardiaque et ceux qui ne le font pas 87% du temps. Nous pouvons améliorer ce score et je vous invite à essayer différentes valeurs d’hyperparamètre.,
- la ligne diagonale est un modèle aléatoire avec une ASC de 0,5, un modèle sans compétence, ce qui équivaut à faire une prédiction aléatoire. Pouvez-vous deviner pourquoi?
courbe de rappel de précision (PRC)
comme son nom l’indique, cette courbe est une représentation directe de la précision(axe y) et du rappel(axe x). Si vous observez nos définitions et formules pour la précision et le rappel ci-dessus, vous remarquerez qu’à aucun moment nous n’utilisons les vrais négatifs(le nombre réel de personnes qui n’ont pas de maladie cardiaque).,
ceci est particulièrement utile pour les situations où nous avons un ensemble de données déséquilibré et le nombre de négatifs est beaucoup plus grand que les positifs(ou lorsque le nombre de patients n’ayant pas de maladie cardiaque est beaucoup plus grand que les patients qui en ont). Dans de tels cas, notre plus grande préoccupation serait de détecter les patients atteints de maladie cardiaque aussi correctement que possible et n’aurait pas besoin du TNR.
comme le ROC, nous traçons la précision et le rappel pour différentes valeurs de seuil:
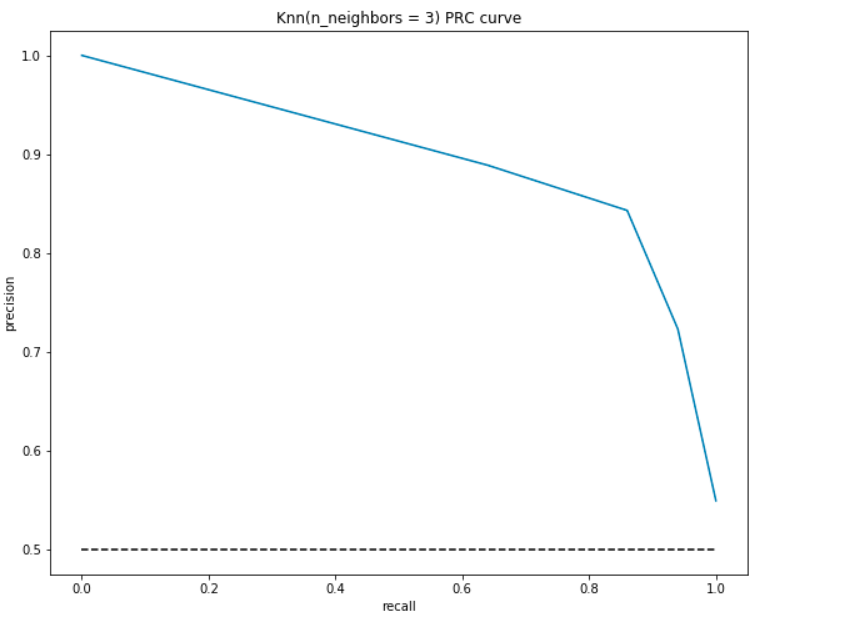
interprétation PRC:
- au point le plus bas, c’est-à-dire, en (0, 0)- le seuil est fixé à 1.0. Cela signifie que notre modèle ne fait aucune distinction entre les patients qui ont une maladie cardiaque et les patients qui n’en ont pas.
- au point le plus élevé, c’est-à-dire à (1, 1), le seuil est fixé à 0,0. Cela signifie que notre précision et notre rappel sont élevés et que le modèle fait des distinctions parfaitement.
- le reste de la courbe correspond aux valeurs de précision et de rappel pour les valeurs seuils comprises entre 0 et 1. Notre objectif est de rendre la courbe aussi proche que possible de (1, 1) – ce qui signifie une bonne précision et un bon rappel.,
- semblable à ROC, l’aire avec la courbe et les axes comme limites est L’aire sous la courbe(AUC). Considérer cette zone comme une métrique d’un bon modèle. L’AUC varie de 0 à 1. Par conséquent, nous devrions viser une valeur élevée de L’ASC. Calculons l’AUC pour notre modèle et le graphique ci-dessus:

comme précédemment, nous obtenons une bonne AUC d’environ 90%. En outre, le modèle peut atteindre une haute précision avec rappel comme 0 et atteindrait un rappel élevé en compromettant la précision de 50%.,
notes de fin
pour conclure, dans cet article, nous avons vu comment évaluer un modèle de classification, en particulier en mettant l’accent sur la précision et le rappel, et trouver un équilibre entre eux. Nous expliquons également comment représenter les performances de notre modèle à l’aide de différentes métriques et d’une matrice de confusion.
Voici un article supplémentaire pour vous permettre de comprendre les mesures d’évaluation – 11 mesures importantes D’évaluation de modèles pour L’apprentissage automatique que tout le monde devrait connaître