Áttekintés
- Pontosság, emlékszem, két fontos még meg nem értett témák a gépi tanulás
- megbeszéljük, hogy mi a pontosság, mind pedig emlékszem, hogyan dolgoznak, szerepük értékelése során egy gépi tanulási modell
- akkor is értsék a Görbe Alatti Terület (AUC) pedig Pontosság feltételek
Bevezető
Kérdezd meg bármelyik gépi tanulás, szakmai vagy adatok tudós arról, hogy a zavaros fogalmak a tanulás útja., A válasz mindig a precizitásra és a visszahívásra irányul.
a pontosság és a visszahívás közötti különbség valójában könnyen megjegyezhető – de csak akkor, ha valóban megértette, hogy az egyes kifejezések mit jelentenek. De elég gyakran, és ezt igazolhatom, a szakértők általában félig sült magyarázatokat kínálnak, amelyek még inkább összezavarják az újonnan érkezőket.
tehát állítsuk be a rekordot ebben a cikkben.

minden gépi tanulási modell esetében tudjuk, hogy a modell “jó illeszkedése” elérése rendkívül fontos., Ez magában foglalja az alulfelszerelés és a túlcsordulás közötti egyensúly elérését, vagyis az elfogultság és a variancia közötti kompromisszumot.
azonban, amikor a besorolás – van egy másik kompromisszum, hogy gyakran figyelmen kívül hagyják mellett a torzítás-variancia kompromisszum. Ez a precíziós visszahívási kompromisszum. Az adatkészletekben gyakran fordulnak elő kiegyensúlyozatlan osztályok, és amikor konkrét felhasználási esetekről van szó, valójában nagyobb jelentőséget szeretnénk tulajdonítani a precíziós és visszahívási mutatóknak, valamint a köztük lévő egyensúly elérésének.
de hogyan kell ezt megtenni?, Az osztályozási értékelési mutatókat a precizitásra és a visszahívásra összpontosítva fogjuk megvizsgálni ebben a cikkben. Azt is megtanuljuk, hogyan kell kiszámítani ezeket a mutatókat Python-ban egy adathalmaz és egy egyszerű osztályozási algoritmus segítségével. Szóval, kezdjük el!
itt részletesen megismerheti az értékelési mutatókat-a gépi tanulási modellek értékelési mutatóit.
Tartalomjegyzék
- a Problémamegállapítás megértése
- mi a pontosság?
- mi a visszahívás?,
- a legegyszerűbb értékelési mutató-pontosság
- az F1-pontszám szerepe
- a híres precíziós visszahívási kompromisszum
- a görbe alatti terület megértése (AUC)
A Problémamegállapítás megértése
határozottan hiszek a tanulás során. Tehát ebben a cikkben gyakorlati szempontból fogunk beszélni-egy adatkészlet használatával.
vegyük fel az UCI adattárban elérhető népszerű szívbetegség-adatkészletet. Itt meg kell jósolnunk, hogy a beteg szívbetegségben szenved-e, vagy nem használja-e az adott jellemzőket., A tiszta adatkészletet innen töltheti le.
mivel ez a cikk kizárólag a modellértékelési mutatókra összpontosít, a legegyszerűbb osztályozót – a kNN osztályozási modellt fogjuk használni jóslatok készítéséhez.
Mint mindig, most kell elkezdeni importálásával a szükséges könyvtárak, valamint csomagok:
Akkor vessünk egy pillantást az adatok, valamint a cél változóval van dolgunk:
nézzük, ha van hiányzó értékeket:
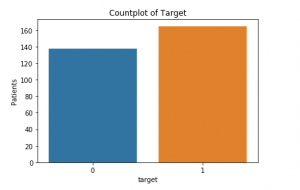
nincs hiányzó értékeket., Most megnézhetjük, hogy valójában hány beteg szenved szívbetegségben (1), és hányan nem (0):
Ez az alábbi számlálási terület:
folytassuk a képzési és vizsgálati adataink, valamint a bemeneti és célváltozóink megosztásával. Mióta használunk KNN kötelező skála az adatsorok is:
A megérzés mögött választotta a legjobb értéke k túlmutat e cikk, de tudnunk kell, hogy meg tudjuk határozni az optimális értéke k, amikor a legnagyobb eredmény az, hogy az értéket., Az, hogy tudjuk értékelni a képzés, illetve a vizsgálati eredmények akár 20 legközelebbi szomszédok:
ahhoz, Hogy értékelje a max teszt pontszám, majd a k-értékek társul hozzá, akkor futtassa a következő parancsot:

Így elértük, hogy az optimális értéke k, hogy 3, 11, vagy 20 pont 83.5. Ezen értékek egyikét véglegesítjük, és ennek megfelelően illesztjük be a modellt:

most hogyan értékeljük, hogy ez a modell ” jó ” modell-e vagy sem?, Ehhez egy úgynevezett Zavartmátrixot használunk:
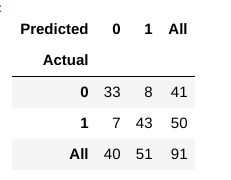
a zavartmátrix segít betekintést nyerni abba, hogy a jóslataink mennyire helyesek voltak, és hogyan állnak szemben a tényleges értékekkel.
vonat-és tesztadatainkból már tudjuk, hogy tesztadataink 91 adatpontból álltak. Ez a 3. sor és a 3. oszlop értéke a végén. Azt is észrevesszük, hogy vannak tényleges és előre jelzett értékek. A tényleges értékek az adatpontok száma, amelyeket eredetileg 0 vagy 1 kategóriába soroltak., Az előre jelzett értékek a KNN modellünk által 0-ra vagy 1-re előre jelzett adatpontok száma.
A tényleges értékek:
- A betegek, akik valójában nem egy szívbetegség = 41
- A betegek, akik tényleg van szívbetegség = 50
A becsült értékek a következők:
- betegek Száma, akik előre, mintha nem is lenne szívbetegség = 40
- betegek Száma, akik megjósolta, hogy a szívbetegség = 51
az Összes értékeket megkapjuk a fenti kifejezés., Nézzük át őket egyenként:
- azok az esetek, amikor a betegeknek valójában nem volt szívbetegségük, és a modellünk azt is megjósolta, hogy nem rendelkezik valódi negatívokkal. A mátrixunk esetében az igaz negatívok = 33.
- azokat az eseteket, amikor a betegek valóban szívbetegségben szenvednek, és modellünk azt is megjósolta, hogy valódi pozitívnak nevezik. A mátrixunk esetében igaz pozitívok = 43
- vannak azonban olyan esetek, amikor a betegnek valójában nincs szívbetegsége, de modellünk azt jósolta, hogy igen., Ez a fajta hiba az I. típusú hiba, az értékeket hamis pozitívnak nevezzük. A mátrixunk esetében hamis pozitívok = 8
- hasonlóképpen vannak olyan esetek, amikor a betegnek valóban szívbetegsége van, de modellünk azt jósolta, hogy nem. ez a fajta hiba a II.típusú hiba, és az értékeket hamis Negatívoknak nevezzük. Mátrixunk esetében hamis negatívok = 7
mi a pontosság?
jobb-így most jön a lényege ennek a cikknek. Mi a világon a precizitás? És mi köze van ehhez a fenti tanulásnak?,
a legegyszerűbb értelemben a pontosság az igazi pozitívok és az összes pozitív közötti arány. A mi problémamegállapítás, ez lenne az intézkedés a betegek, hogy mi helyesen azonosítani, amelynek szívbetegség ki az összes beteg ténylegesen birtoklás ez. Matematikailag:

mi a precizitás modellünk számára? Igen, ez 0,843, vagy ha azt jósolja, hogy a betegnek szívbetegsége van, az idő körülbelül 84% – a helyes.
A pontosság a vonatkozó adatpontok mérését is megadja., Fontos, hogy ne kezdjünk el olyan beteget kezelni, akinek valójában nincs szívbetegsége, de modellünk azt jósolta, hogy megvan.
mi a visszahívás?
a visszahívás A modellünk mércéje, amely helyesen azonosítja a valódi pozitívumokat. Így minden olyan beteg esetében, akik valóban szívbetegségben szenvednek, a recall elmondja nekünk, hogy hányat azonosítottunk helyesen szívbetegségként. Matematikailag:

modellünk esetében visszahívás = 0, 86. A visszahívás azt is méri, hogy modellünk pontosan képes-e azonosítani a vonatkozó adatokat., Érzékenységnek vagy valódi pozitív aránynak nevezzük. Mi van akkor, ha egy betegnek szívbetegsége van, de nincs olyan kezelés, amelyet neki adtak, mert a modellünk ezt megjósolta? Ezt a helyzetet szeretnénk elkerülni!
A legegyszerűbb metrika, hogy megértsük-pontosság
most jön az egyik legegyszerűbb mutatókat az összes, pontosság. A pontosság a helyes jóslatok teljes számának és az előrejelzések teljes számának aránya. Meg tudja kitalálni, mi lesz a pontosság képlete?
![]()
modellünk esetében a pontosság = 0,835 lesz.,
a pontosságnak, mint a modell meghatározó metrikájának a használata intuitív módon értelmezhető, de gyakrabban, mint nem, mindig tanácsos a precizitást és a visszahívást is használni. Lehetnek más helyzetek is, amikor pontosságunk nagyon magas, de pontosságunk vagy visszahívásunk alacsony. Ideális esetben modellünknél teljes mértékben el szeretnénk kerülni minden olyan helyzetet, amikor a beteg szívbetegségben szenved, de modellünk úgy osztályozza, hogy nem rendelkezik vele, azaz célja a magas visszahívás.,
másrészt azokban az esetekben, amikor a beteg nem szenved szívbetegségben, és modellünk az ellenkezőjét jósolja, azt is szeretnénk elkerülni, hogy szívbetegségben szenvedő beteget kezeljünk(döntő fontosságú, ha a bemeneti paraméterek más betegséget jelezhetnek, de végül szívbetegségben kezeljük).
bár nagy pontosságra és nagy visszahívási értékre törekszünk, mindkettő elérése egyszerre nem lehetséges., Például, ha megváltoztatjuk a modellt, amely magas visszahívást ad nekünk, észlelhetjük az összes szívbetegségben szenvedő beteget, de előfordulhat, hogy sok olyan betegnek adunk kezeléseket, akik nem szenvednek tőle.
hasonlóképpen, ha nagy pontosságra törekszünk, hogy elkerüljük a helytelen és nem kívánt kezelést,akkor sok olyan betegünk lesz, akiknek valóban szívbetegsége van, kezelés nélkül.
az F1-Score szerepe
a megértés pontossága ráébresztett minket, szükségünk van egy kompromisszum a pontosság és a visszahívás között., Először el kell döntenünk, hogy melyik fontosabb a besorolási problémánk szempontjából.
például adatkészletünknél figyelembe vehetjük, hogy a nagy visszahívás elérése fontosabb, mint a nagy pontosság elérése – minél több szívbeteget szeretnénk felismerni. Néhány más modell esetében, például annak osztályozása, hogy a banki ügyfél hitel-e vagy sem, kívánatos nagy pontosságú, mivel a bank nem akarja elveszíteni azokat az ügyfeleket, akiket a modell előrejelzése alapján megtagadtak a hiteltől.,
sok olyan helyzet is van, ahol mind a pontosság, mind a visszahívás egyaránt fontos. Például modellünk esetében, ha az orvos tájékoztat minket arról, hogy a szívbetegségben szenvedőnek helytelenül besorolt betegek ugyanolyan fontosak, mivel más betegségre utalhatnak, akkor nemcsak a magas visszahívásra, hanem a nagy pontosságra is törekednénk.
ilyen esetekben az úgynevezett F1-score-t használjuk., Az F1-score a precizitás és a visszahívás harmonikus átlaga:

Ez azóta könnyebb, a pontosság és a visszahívás kiegyensúlyozása helyett csak egy jó F1-pontszámra tudunk törekedni, ami jó pontosságra és jó visszahívási értékre is utalna.,
Tudunk generálni a fenti mérőszámok mi adatbázis használata sklearn is:
ROC Görbe
Mentén a fenti feltételek vannak még értékek, ki tudjuk számítani a zűrzavar, mátrix:
- Hamis Pozitív Arány (FPR): Ez az arány a Hamis Pozitív, hogy a Tényleges szám Negatív. Modellünk összefüggésében ez egy intézkedés arra vonatkozóan, hogy hány esetben a modell azt jósolja, hogy a betegnek szívbetegsége van minden olyan betegtől, akiknek valójában nem volt szívbetegsége. Adataink esetében az FPR = 0.,195
- True Negative Rate (TNR) vagy a specificitás: ez az igazi negatívok aránya és a negatívok tényleges száma. Modellünk esetében ez az az intézkedés, hogy hány esetben a modell helyesen megjósolta, hogy a betegnek nincs szívbetegsége minden olyan betegtől, akinek valójában nem volt szívbetegsége. A fenti adatok TNR = 0,804. Ezekből 2 meghatározások is tudunk következtetni, hogy a Specifikusság, vagy TNR = 1 – FPR
azt is elképzelni, Precíz Visszahívás használata ROC görbék, valamint KÍNÁBÓL görbék.,
ROC görbék (Receiver Operating character Curve):
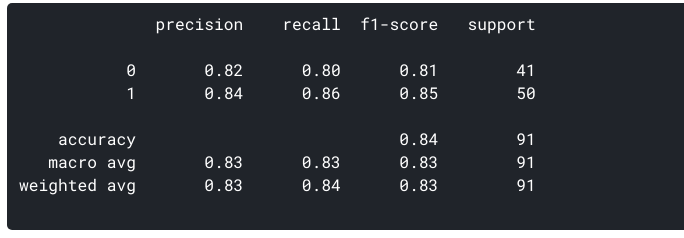
Ez a TPR(y-axis) és az FPR(x-axis) közötti telek. Mivel modellünk a pácienst szívbetegségnek minősíti, vagy nem az egyes osztályokra generált valószínűségek alapján, eldönthetjük a valószínűségek küszöbértékét is.
például 0, 4 küszöbértéket akarunk beállítani. Ez azt jelenti, hogy a modell az adatpontot/beteget szívbetegségnek minősíti, ha a szívbetegségben szenvedő beteg valószínűsége nagyobb, mint 0, 4., Ez nyilvánvalóan magas visszahívási értéket ad, és csökkenti a hamis pozitívumok számát. Hasonlóképpen, a ROC görbe segítségével megjeleníthetjük, hogyan teljesít a modellünk a különböző küszöbértékekhez.
hozzunk létre egy ROC görbét modellünkhöz k = 3-mal.
AUC értelmezés-
- a legalacsonyabb ponton, azaz (0, 0)- a küszöbértéket 1, 0 értéken kell beállítani. Ez azt jelenti, hogy modellünk minden beteget úgy osztályoz, hogy nincs szívbetegsége.
- a legmagasabb ponton, azaz az (1, 1) értéknél a küszöbérték 0, 0 értéken van beállítva., Ez azt jelenti, hogy modellünk minden beteget szívbetegségnek osztályoz.
- a görbe többi része a 0 és 1 közötti küszöbértékek FPR és TPR értékei. Bizonyos küszöbértéknél megfigyeljük, hogy az fpr közel 0-hoz közel 1 TPR-t érünk el. Ez az, amikor a modell szinte tökéletesen megjósolja a szívbetegségben szenvedő betegeket.
- a görbével rendelkező területet és a határként megadott tengelyeket a görbe alatti területnek(AUC) nevezzük. Ez a terület tekinthető egy jó modell metrikájának., Ezzel a 0-tól 1-ig terjedő mutatóval az AUC magas értékére kell törekednünk. A magas AUC-val rendelkező modelleket jó képességű modelleknek nevezik. Számítsuk ki modellünk AUC pontszámát és a fenti ábrát:

- 0, 868 értéket kapunk az AUC-ként, ami elég jó pontszám! A legegyszerűbb értelemben ez azt jelenti, hogy a modell képes lesz megkülönböztetni a szívbetegeket és azokat, akik nem az idő 87% – át teszik ki. Javíthatunk ezen a pontszámon, és kérem, próbáljon ki különböző hiperparaméter értékeket.,
- az átlós vonal egy véletlenszerű modell, amelynek AUC-je 0,5, egy készség nélküli modell, amely ugyanolyan, mint egy véletlenszerű előrejelzés. Kitalálod, miért?
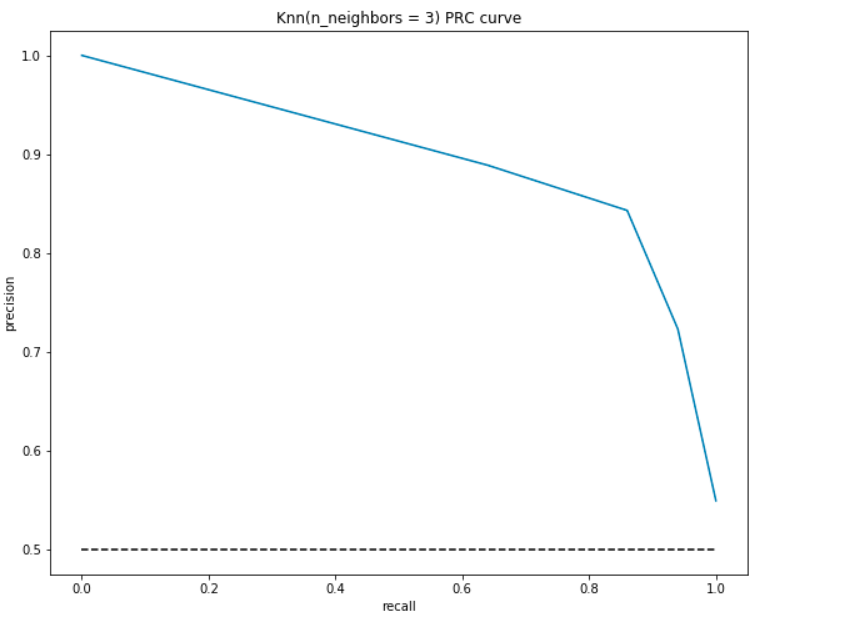
Precision-Recall Curve (PRC)
ahogy a neve is sugallja, ez a görbe a pontosság(y-tengely) és a visszahívás(x-tengely) közvetlen ábrázolása. Ha figyelembe vesszük a definíciókat és képleteket a fenti precizitáshoz és visszahíváshoz, akkor észre fogod venni, hogy semmi esetre sem használjuk az igazi negatívokat(az emberek tényleges számát, akiknek nincs szívbetegségük).,
Ez különösen akkor hasznos, ha kiegyensúlyozatlan adatkészletünk van, és a negatívok száma sokkal nagyobb, mint a pozitív(vagy ha a szívbetegségben nem szenvedő betegek száma sokkal nagyobb, mint a betegek száma). Ilyen esetekben nagyobb gondunk lenne a szívbetegségben szenvedő betegek lehető legpontosabb kimutatása, és nem lenne szükség a TNR-re.
Mint a ROC, szervezünk, a pontosság, emlékszem, hogy a különböző küszöbértékek:
KNK-Értelmezés:
- a legalacsonyabb pont, azaz, a (0, 0)- a küszöbérték 1,0-ra van beállítva. Ez azt jelenti, hogy modellünk nem tesz különbséget a szívbetegségben szenvedő betegek és azok között a betegek között, akik nem.
- a legmagasabb ponton, azaz (1, 1), a küszöbérték 0, 0. Ez azt jelenti, hogy mind a pontosság, mind a visszahívás magas, és a modell tökéletesen megkülönbözteti.
- a görbe többi része a 0 és 1 közötti küszöbértékek pontossági és visszahívási értékei. Célunk, hogy a görbe a lehető legközelebb legyen (1, 1) – ami jó pontosságot és visszahívást jelent.,
- a ROC-hoz hasonlóan a görbével rendelkező terület és a tengelyek mint határok a görbe alatti terület(AUC). Tekintsük ezt a területet egy jó modell metrikájaként. Az AUC 0-tól 1-ig terjed. Ezért az AUC magas értékére kell törekednünk. Számítsuk ki modellünk és a fenti telek AUC-jét:

mint korábban, körülbelül 90% – os jó AUC-t kapunk. Emellett a modell nagy pontosságot érhet el a 0-as visszahívással, és nagy visszahívást érhet el az 50% – os pontosság veszélyeztetésével.,
a Végén Megjegyzi,
megkötésére, ebben a cikkben láttuk, hogyan kell értékelni egy osztályozási modell, különösen odafigyel, precíz emlékszem, megtalálni az egyensúlyt közöttük. Azt is elmagyarázzuk, hogyan reprezentáljuk a modell teljesítményét különböző metrikák és egy zavarmátrix segítségével.
itt van egy további cikk az értékelési mutatók megértéséhez – 11 fontos Modellértékelési mutatók a gépi tanuláshoz mindenkinek tudnia kell