Oversikt
- Presisjon og recall er to avgjørende ennå misforstått emner i maskinlæring
- Vi diskutere hva presisjon og recall er, hvordan de fungerer, og deres rolle i å vurdere en maskin læringsmodell
- Vi vil også få en forståelse av Området Under Kurven (AUU) og Nøyaktighet vilkår
Innledning
Spør en hvilken som helst maskin læring professional eller data som forsker om de mest forvirrende begreper i sin reise for å lære., Og alltid, svaret svinger mot Precision og Recall.
forskjellen mellom Presisjon og Recall er faktisk lett å huske – men kun etter at du har virkelig forstått hva hver begrepet står for. Men ganske ofte, og jeg kan bevitne dette, eksperter har en tendens til å tilby halv-bakt forklaringer som forvirre nykommere enda mer.
Så la oss sette posten rett i denne artikkelen.

For noen machine learning modell, vet vi at det å oppnå en «god plass» på modellen er ekstremt viktig., Dette innebærer å oppnå balanse mellom underfitting og overfitting, eller med andre ord, en tradeoff mellom skjevhet og varians.
Men, når det kommer til klassifisering – det er en annen kompromisset som ofte blir oversett i favør av bias-varians byttehandel. Dette er presisjon-recall byttehandel. Ubalansert klasser er vanlig forekommende i datasett og når det kommer til spesifikke tilfeller, ville vi faktisk liker å gi mer vekt på presisjon og recall beregninger, og også hvordan å oppnå balanse mellom dem.
Men, hvordan du gjør det?, Vi vil utforske klassifisering evaluering beregninger ved å sette fokus på presisjon og recall i denne artikkelen. Vi vil også lære å beregne disse beregningene i Python ved å ta et dataset og en enkel klassifisering algoritme. Så, la oss komme i gang!
Du kan lære om evaluering beregninger i dybden her – Evaluering Beregninger for maskinlæring Modeller.
Innholdsfortegnelse
– >
- Forstå Problemet Uttalelse
- Hva er Presisjon?
- Hva er Recall?,
- Den Enkleste Evaluering Metric – Nøyaktighet
- Rollen som F1-Score
- Den Berømte Presisjon-Recall Kompromisset
- Forståelse Området Under Kurven (AUU)
Forstå Problemet Uttalelse
jeg har stor tro på å lære ved å gjøre. Så i denne artikkelen vil vi snakke i praksis – ved hjelp av et dataset.
La oss ta opp den populære hjertesykdommer Datasettet som er tilgjengelig på UCI depotet. Her har vi å forutsi om pasienten lider av et hjerte sykdom eller ikke bruker det gitt sett av funksjoner., Du kan laste ned den rene dataset fra her.
Siden denne artikkelen utelukkende fokuserer på modell evaluering beregninger, vil vi bruke den enkleste classifier – det kNN klassifisering modell til å gjøre forutsigelser.
Som alltid, vi skal starte med å importere de nødvendige biblioteker og pakker:
la oss få en titt på data og målet variablene vi har å gjøre med:
La oss sjekke om vi har manglende verdier:
Det er ingen mangler verdier., Nå kan vi ta en titt på hvor mange pasienter det er faktisk lider av hjerte-og karsykdommer (1), og hvor mange er ikke (0):
Dette er det antall tomten nedenfor:
La oss gå videre ved å dele våre trening og test data og våre innspill og mål variabler. Siden vi bruker KNN, det er obligatorisk å skalere vår datasett for:
Den intuisjonen bak å velge den beste verdien av k er utenfor omfanget av denne artikkelen, men vi skal vite at vi kan bestemme den optimale verdien av k når vi får den høyeste test score for at verdien., For at vi kan vurdere trening og testing score for opp til 20 nærmeste naboer:
for Å vurdere max test score og k-verdiene som er forbundet med det, kan du kjøre følgende kommando:

Dermed har vi fått den optimale verdien av k for å være 3, 11, eller 20 med en score på 83,5. Vi vil sluttføre en av disse verdiene og passer modellen tilsvarende:

Nå, hvordan kan vi vurdere om denne modellen er en » god » modell eller ikke?, For at vi bruker noe som kalles en Forvirring Matrise:
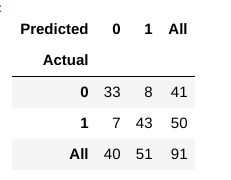
En forvirring matrix hjelper oss å få et innblikk i hvordan korrigere våre spådommer var og hvor de holder opp mot den faktiske verdier.
Fra våre tog og test data, vet vi allerede at våre test data besto av 91 data poeng. Det er den 3. rad og 3. kolonne verdi på slutten. Vi kan også se at det er noen faktiske og anslåtte verdier. Den faktiske verdier er antallet datapunkter som opprinnelig var lagt inn 0 eller 1., Den predikerte verdier er antall datapunkter våre KNN modell spådd som 0 eller 1.
Den faktiske verdier er:
- pasientene som faktisk ikke har en hjertesykdom = 41
- pasientene som faktisk har en hjertesykdom = 50
Den predikerte verdier er:
- Antall pasienter som ble spådd som ikke å ha en hjertesykdom = 40
- Antall pasienter som ble spådd som å ha en hjertesykdom = 51
Alle verdiene får vi ovenfor har en sikt., La oss gå gjennom dem en etter en:
- De tilfeller der pasienter har faktisk ikke har hjerte-og karsykdommer og vår modell også spådd som ikke å ha det som kalles den Sanne Negative. For vår matrise, Sant Negative = 33.
- De tilfeller der pasienter har faktisk hjertesykdommer og vår modell også spådd å ha det kalles Ekte Positive. For vår matrise, Sanne Positiver = 43
- Men, det er noen tilfeller der pasienten faktisk har intet hjerte-og karsykdommer, men vår modell har spådd at de gjør., Denne typen feil er den Type i-Feil, og vi kaller de verdier som Falske Positiver. For vår matrise, Falske Positiver = 8
- på samme måte, det er noen tilfeller der pasienten faktisk har hjertesykdom, men vår modell har spådd at han/hun ikke. Denne typen feil er den Type II-Feil, og vi kaller de verdier som Falske Negativer. For vår matrise, Falske Negativer = 7
Hva er Presisjon?
Høyre – så nå kommer vi til kjernen i denne artikkelen. Hva i all verden er Presisjon? Og hva betyr alle de ovennevnte læring har å gjøre med det?,
I enkleste form, Presisjon er forholdet mellom den Sanne Positive, og alle de Positive. For vårt problem uttalelse, som ville være målestokken for pasienter som vi identifisere ha en hjertesykdom ut av alle pasientene faktisk har det. Matematisk:

Hva er Presisjon for vår modell? Ja, det er 0.843 eller, når det spår at en pasient har hjertesykdom, det er riktig rundt 84% av tiden.
Presisjon gir oss også et mål på hvor relevante data poeng., Det er viktig at vi ikke begynner å behandle en pasient som faktisk ikke har et hjerte sykdom, men vår modell spådd å ha det.
Hva er Recall?
Det husker er målestokken for vår modell å identifisere Ekte Positive. Derfor, for alle pasienter som faktisk har hjertesykdom, husker forteller oss hvor mange vi riktig identifisert som å ha en hjertesykdom. Matematisk:

For vår modell, Recall = 0.86. Recall gir også et mål på hvor nøyaktig vår modell er i stand til å identifisere relevante data., Vi viser til det som Følsomhet eller Sanne Positive Pris. Hva hvis en pasient har hjertesykdom, men det er ingen behandling som er gitt til ham/henne fordi vår modell spådd så? Det er en situasjon vi ønsker å unngå!
Den Enkleste Beregning for å Forstå – Nøyaktighet
Nå er vi kommet til en av de enkleste beregninger av alt, Nøyaktighet. Nøyaktighet er forholdet mellom det totale antall korrekte spådommer og totalt antall spådommer. Kan du gjette hva formelen for Korrektheten vil bli?
![]()
For vår modell, Nøyaktighet vil være = 0.835.,
ved Hjelp av nøyaktighet som et definerende beregning for vår modell er det fornuftig intuitivt, men mer ofte enn ikke, det er alltid lurt å bruke Precision og Recall også. Det kan være andre situasjoner hvor våre nøyaktighet er svært høy, men våre presisjon eller tilbakekall er lav. Ideelt sett, for vår modell, vi ønsker å fullstendig unngå alle situasjoner der pasienten har hjertesykdom, men vår modell klassifiserer som han ikke trenger det altså, mål for høy recall.,
På den annen side, for de tilfeller der pasienten ikke lider av hjerte-og karsykdommer og vår modell spår det motsatte, og vi ønsker også å unngå behandling av en pasient som ikke hadde noe hjerte-og karsykdommer(avgjørende når input parametere kan indikere en annen sykdom, men vi ender opp med å behandle ham/henne for en hjerte sykdom).
Selv om vi gjør mål for høy presisjon og høy recall verdi, å oppnå begge deler samtidig, er ikke mulig., For eksempel, hvis vi endre modellen til en gi oss en høy husker, vi kan oppdage alle pasienter som faktisk har hjertesykdom, men vi kan ende opp med å gi behandlinger til en rekke pasienter som ikke lider av det.
på samme måte, hvis vi mål for høy presisjon for å unngå å gi noen feil og unrequired behandling, ender vi opp med å få mange pasienter som faktisk har en hjertesykdom kommer uten noen behandling.
Rollen som F1-Score
Forstå Korrektheten gjort oss innse, vi trenger en tradeoff mellom Presisjon og Recall., Vi må først bestemme hvilken som er mer viktig for vår klassifisering problem.
For eksempel, for vårt datasett, kan vi vurdere at det å oppnå en høy recall er mer viktig enn å få en høy presisjon – vi ønsker å oppdage så mange hjertet pasienter som mulig. For enkelte andre modeller, som å klassifisere om en bank kunde er et lån defaulter eller ikke, det er ønskelig å ha en høy presisjon siden banken ville ikke ønsker å miste kunder som ble nektet et lån basert på modellens prediksjon om at de ville bli defaulters.,
Det er også en rekke situasjoner der både presisjon og recall er like viktig. For eksempel, for vår modell, hvis legen informerer oss om at pasienter som ble feilaktig klassifisert som lider av hjertesykdommer er like viktige, siden de kan være en indikasjon på noen annen sykdom, så ville vi tar sikte på ikke bare en høy husker, men en høy presisjon, så vel.
I slike tilfeller bruker vi noe som kalles F1-score., F1-score er det Harmoniske gjennomsnittet av Precision og Recall:

Dette er lettere å jobbe med siden nå, i stedet for å balansere presisjon og recall, kan vi bare satse på en god F1-score, og det ville være en indikasjon på en god Presisjon og en god Recall verdien.,
Vi kan generere over verdier for våre datasett ved hjelp av sklearn også:
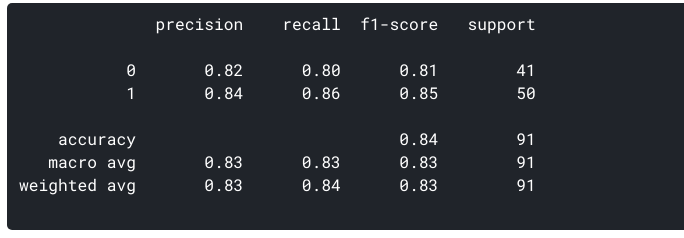
ROC-Kurve
Sammen med vilkårene ovenfor, er det flere verdier kan vi beregne fra forvirring matrise:
- Falsk Positiv Rate (FPR): Det er forholdet mellom Falske Positive til det Faktiske antall av Negativer. I sammenheng med vår modell, det er et mål for hvor mange saker som gjorde modellen forutsier at pasienten har en hjertesykdom fra alle pasienter som egentlig ikke har hjerte-og karsykdommer. For våre data, FPR er = 0.,195
- Sanne Negative Rate (TNR) eller Spesifisitet: Det er forholdet mellom den Sanne Negative, og det Faktiske Antall Negativer. For vår modell, det er målestokken for hvor mange tilfeller gjorde modellen tippe at pasienten ikke har hjerte-og karsykdommer fra alle pasienter som egentlig ikke har hjerte-og karsykdommer. Den TNR for de ovennevnte data = 0.804. Fra disse 2 definisjoner, kan vi også konkludere med at Spesifisitet eller TNR = 1 – FPR
Vi kan også visualisere Presisjon og Recall ved hjelp av ROC-kurver og PRC-kurver.,
ROC-Kurver(Receiver Operating Characteristic Curve):
Det er tomt mellom TPR(y-aksen) og FPR(x-aksen). Siden vår modell klassifiserer pasienten som har hjertesykdom eller ikke basert på sannsynligheter som er generert for hver klasse, kan vi bestemme terskelen av sannsynligheter som godt.
For eksempel, ønsker vi å sette en terskelverdi på 0,4. Dette betyr at modellen vil klassifisere datapoint/pasient som har hjertesykdommer om sannsynligheten for pasienten å ha en hjertesykdom er større enn 0,4., Dette vil åpenbart gi en høy recall verdi og redusere antall Falske Positiver. På samme måte kan vi se hvordan vår modell utfører for ulik terskel verdiene ved hjelp av ROC-kurven.
La oss generere en ROC-kurve for vår modell med k = 3.
AUU Tolkning-
- På det laveste punktet, dvs. i (0, 0)- terskelen er satt til 1.0. Dette betyr at vår modell klassifiserer alle pasienter som ikke har en hjertesykdom.
- På det høyeste punktet dvs. i (1, 1), terskelen settes til 0.0., Dette betyr at vår modell klassifiserer alle pasienter som har en hjertesykdom.
- resten av kurven er verdiene av FPR og TPR terskelen for verdier mellom 0 og 1. På noen terskelverdi, ser vi at for FPR nær 0, vi er å oppnå en TPR av nær 1. Dette er når modellen vil forutsi pasienter som har hjertesykdom nesten perfekt.
- området med kurven og de aksene som grenser kalles Området Under Kurven(AUU). Det er dette området som er regnet som en beregning av en god modell., Med denne verdien varierer fra 0 til 1, og vi bør ha som mål for en høy verdi av AUU. Modeller med en høy AUU er kalt til modeller med god ferdighet. La oss beregne AUU resultat av vår modell og over plot:

- Vi få en verdi av 0.868 som AUU som er en ganske god score! I enkleste form, betyr dette at modellen vil være i stand til å skille pasienter med hjerte-og karsykdommer, og de som ikke 87% av tiden. Vi kan forbedre denne poengsummen, og jeg oppfordrer deg prøve forskjellige hyperparameter verdier.,
- diagonal linje er en tilfeldig modell med en AUU 0.5, en modell med ingen ferdighet, noe som bare det samme som å gjøre et tilfeldig prediksjon. Kan du gjette hvorfor?
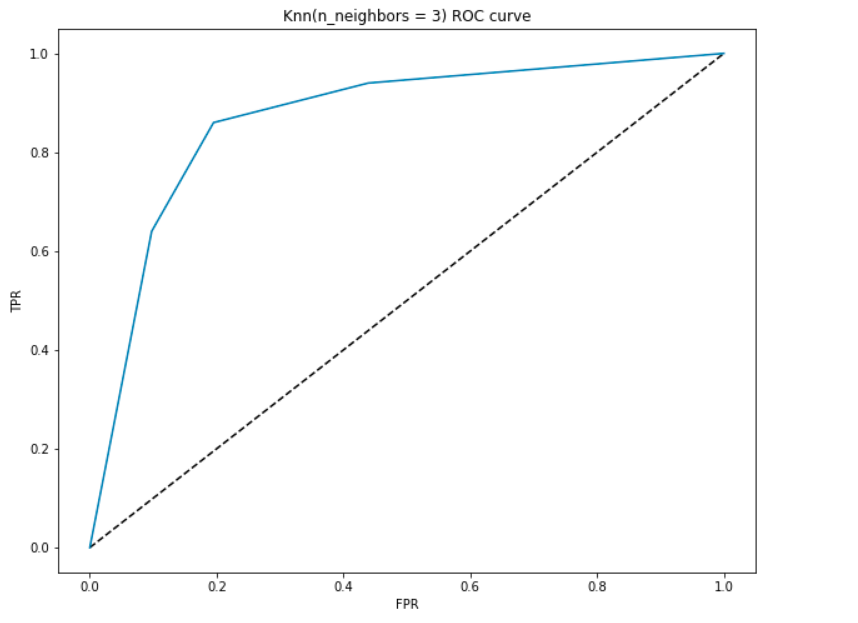
Presisjon-Recall-Kurve (PRC)
Som navnet antyder, er denne kurven er en direkte representasjon av presisjon(y-aksen) og recall(x-aksen). Hvis du observerer våre definisjoner og formler for Presisjon og Recall ovenfor, vil du legge merke til at ikke på noe punkt er vi ved hjelp av den Sanne Negative(det faktiske antallet av personer som ikke har hjertesykdommer).,
Dette er spesielt nyttig for de situasjoner hvor vi har en ubalansert datasettet og antall negativer er mye større enn de positive(eller når antallet pasienter har ingen hjertesykdom er mye større enn de pasientene som har det). I slike tilfeller, våre høyere bekymring ville være å oppdage pasienter med hjertesykdommer så riktig som mulig, og ville ikke trenger TNR.
Som ROC, vi plotte presisjon og recall for ulik terskel verdier:
PRC Tolkning:
- På det laveste punktet, dvs., i (0, 0)- terskelen er satt til 1.0. Dette betyr at vår modell gir ingen forskjeller mellom pasienter som har hjertesykdom og pasienter som ikke er det.
- På det høyeste punktet dvs. i (1, 1), terskelen settes til 0.0. Dette betyr at både våre presisjon og recall er høy, og modellen gjør forskjellen på en perfekt måte.
- resten av kurven er verdiene av Precision og Recall for terskelen verdier mellom 0 og 1. Vårt mål er å gjøre kurven så nær (1, 1) som mulig – noe som betyr en god presisjon og recall.,
- Lik ROC, området med kurven og de aksene som grenser er Området Under Kurven(AUU). Vurdere dette området som en beregning av en god modell. AUU varierer fra 0 til 1. Derfor bør vi satse på en høy verdi av AUU. La oss beregne AUU for vår modell og over plot:

Som før, vi får en god AUU på rundt 90%. Også, kan modellen oppnå høy presisjon med recall som 0 og ville oppnå en høy husker at det går på bekostning av presisjonen på 50%.,
Avslutt Notater
for Å konkludere, i denne artikkelen, vi så hvordan man skal vurdere en klassifisering modell, spesielt med fokus på presisjon og recall, og finne en balanse mellom dem. Også, forklarer vi hvordan du representerer vår modell ytelse ved hjelp av ulike beregninger og en forvirring matrise.
Her er en ekstra artikkel for deg å forstå evaluering beregninger – 11 Viktig Modell Evaluering Beregninger for maskinlæring Alle bør vite