Barcode 101: Przewodnik po symbolach kodów kreskowych
symbol kodu kreskowego jest obrazem do odczytu maszynowego, który przekazuje dane. Kody kreskowe można podzielić na trzy ogólne typy: liniowe, liniowe i dwuwymiarowe (lub 2D): liniowe Kody kreskowe
UPC-A
UPC-A (zwany także po prostu UPC) jest standardowym kodem kreskowym w Stanach Zjednoczonych. UPC-A jest ściśle numeryczny; słupki mogą reprezentować tylko cyfry od 0 do 9., Kod kreskowy UPC-A zawiera 12 cyfr, wraz z cichą (pustą) strefą po obu stronach oraz symbolami startu, środka i zatrzymania. Symbol środkowy oddziela lewą i prawą stronę, które są kodowane inaczej. Gdy cyfra jest używana po lewej stronie, paski są czarne, a spacje są białe, a gdy jest używana po prawej stronie, kolory są odwrócone., Logika stojąca za tym jest trochę skomplikowana i obejmuje matematyczną właściwość o nazwie „parzystość”, ale efekt polega na odwróceniu czerni i bieli i umożliwieniu skanerowi stwierdzenia, czy czyta Kod od lewej do prawej, czy od prawej do lewej.
rzeczywisty system numeracji zależy od rodzaju produktu i przeznaczenia kodu kreskowego; pierwsza cyfra kodu kreskowego wskazuje system numeracji., Poniższe 10 cyfr zawiera informacje o produkcie, a we wszystkich opisanych poniżej aplikacjach cyfra po prawej stronie (nieuwzględniona w opisie aplikacji) jest sumą kontrolną, która może być używana do testowania dokładności odczytu skanera. Poniżej znajduje się lista popularnych aplikacji UPC – A:




UPC-E
Kod kreskowy UPC-E może być używany, gdy dostępna przestrzeń jest zbyt mała dla kodu kreskowego UPC-A. zawiera te same informacje, co etykieta UPC-A, ale wykorzystuje pewne sztuczki, aby zmniejszyć liczbę cyfr do sześciu.,

najbardziej podstawową sztuczką kodu UPC-E jest usunięcie końcowych zer w kodzie producenta i wiodących zer w kodzie produktu. Szczegóły tej techniki są skomplikowane i nie działa ona na wszystko, ale obejmuje wszystkie kody z sumie 5 zerami wiodącymi/końcowymi, a także znaczną liczbę kodów z czterema zerami.
UPC-E wykorzystuje znacznie bardziej skomplikowaną sztuczkę do kompresji sumy kontrolnej i kodu systemu liczbowego. Efektem ubocznym tej techniki jest to, że jedynymi dozwolonymi kodami systemu numeracji są 0 i 1.,
EAN-13
Kod EAN-13 jest w zasadzie międzynarodową wersją UPC-A. EAN-13 dodaje trzynastą cyfrę po lewej stronie kodu UPC-A (tak, że staje się pierwszą cyfrą). Standard EAN-13 zawiera kody kreskowe UPC-A; dodanie wiodącego 0 do kodu UPC-A zamienia go w odpowiedni kod EAN-13.

główne różnice między EAN-13 i UPC-A (poza dodatkową cyfrą wiodącą) polegają na tym, że w EAN-13 producent i kody produktów mogą się różnić długością, a pierwsze trzy cyfry składają się na prefiks GS1, czyli „kod kraju.,”
prefiks GS1 jest wydawany przez GS1, międzynarodową organizację standardów kodów kreskowych. Może on zidentyfikować krajową organizację członkowską GS1 lub specjalne zastosowanie. Organizacje członkowskie wydają kody producenta, a producenci ustalają własne kody produktów. Kompletny numer kodu kreskowego EAN-13, składający się z prefiksu GS1, kodu producenta, kodu produktu i cyfry sumy kontrolnej, jest również znany jako GTIN lub Global Trade Item Number.,Oprócz krajowych prefiksów GS1, zwykle stosowanych w przypadku standardowych produktów detalicznych, istnieją prefiksy do celów specjalistycznych, takich jak kupony, zwroty, publikacje seryjne( czasopisma i gazety), książki (ISBN) i nuty (ISMN).

w Stanach Zjednoczonych skanery kodów cenowych i systemy punktów sprzedaży / zapasów są zazwyczaj zdolne do odczytu zarówno kodów kreskowych UPC-A, jak i EAN-13.
EAN-8
EAN-8 to kod kreskowy GS1 do użytku na małych przedmiotach, gdy pełna etykieta z kodem kreskowym EAN-13 byłaby zbyt duża, aby się zmieścić., Składa się z ośmiu cyfr-czterech po lewej stronie i czterech po prawej. Używają tego samego rodzaju kodowania, co UPC-A i EAN-13, przy czym ostatnia cyfra jest używana jako suma kontrolna.

Kod kreskowy EAN-8 może być używany z numerami identyfikacyjnymi produktów GTIN-8 lub RCN-8.
GTIN-8 jest jak skrócona wersja kodu EAN-13, ale bez informacji o pochodzeniu produktu. Aby użyć numeru GTIN-8, producent musi zażądać go od krajowej organizacji członkowskiej., Kod kreskowy EAN-8 kodujący numer identyfikacyjny GTIN-8 jest ważny do użytku globalnego, podobnie jak kod kreskowy EAN-13.
natomiast numery RCN-8 są przeznaczone wyłącznie do użytku na produktach marki house lub store-label i mogą być używane tylko w firmie, która je wydaje. Jeśli zostanie zeskanowany przez innego sprzedawcę, da nieprawidłowy odczyt.
Kod 128
opisane powyżej Kody kreskowe UTF i EAN kodują tylko cyfry, ale Kod 128 jest liniowym kodem kreskowym, który koduje zarówno litery alfabetu, jak i cyfry, dzięki czemu jest przydatny do różnych celów poza podstawowymi cenami i zapasami.,
Kod 128 koduje 128-znakowy zestaw ASCII, który zawiera wszystkie znaki Alfabetyczne, numeryczne, interpunkcyjne i arytmetyczne znajdujące się na anglojęzycznej klawiaturze komputera, a także kilka niewidocznych znaków sterujących.,
w celu włączenia wszystkich znaków ASCII, Kod 128 używa trzech różnych zestawów znaków:



pojedynczy kod 128 może zawierać znaki ze wszystkich trzech zestawów znaków, przełączając się między nimi wielokrotnie.
podstawowy format kodu kreskowego Code 128 składa się z kodu początkowego (który ustawia początkowy zestaw znaków na A, B lub C), Danych kodu, cyfry sumy kontrolnej i kodu stop, który oznacza koniec kodu kreskowego. Podobnie jak w przypadku innych liniowych kodów kreskowych, po obu stronach znajdują się puste strefy ciszy.
GS1-128 (znany również jako UCC-128 i EAN-128) jest międzynarodowym standardem używania kodu 128 w etykietach z kodami kreskowymi w łańcuchu dostaw., GS1-128 składa się z podstawowego formatu kodu 128 z identyfikatorem aplikacji dodanym do danych kodu.

identyfikatory aplikacji mają od 2 do 4 znaków i identyfikują typ danych, które będą następowały — zazwyczaj w standardowych aplikacjach łańcucha dostaw, takich jak numer seryjny, liczba kontenerów, numer partii, Waga, objętość itp., w tym śledzenie i informacje o transakcjach. Każdy identyfikator ustawia długość i format danych, które po nim następują.,
ponieważ większość danych kodu aplikacji ma stałą długość, możliwe jest dołączenie kilku kodów w jednym kodzie kreskowym GS1 – 128, po prostu dodając nowe identyfikatory aplikacji i dane kodu.

Kod 39
kod 39 jest również alfanumeryczny i o zmiennej długości. Został opracowany w 1974 roku i jest nadal w stosunkowo szerokim użyciu; większość czytników kodów kreskowych może odczytać kod 39. W kodzie 39 każdy znak składa się z pięciu taktów i czterech spacji, z których trzy są szerokie, a pozostałe wąskie., W rezultacie wszystkie znaki mają tę samą szerokość, a kod kreskowy Code 39 zajmuje zwykle więcej miejsca niż równoważny Kod kreskowy Code 128.

podstawowy system Code 39 składa się z 43 znaków, w tym dużych liter, cyfr i niektórych znaków specjalnych / interpunkcyjnych. W zależności od aplikacji i systemu możliwe jest użycie wszystkich 128 znaków ASCII.
Kod kreskowy kod 39 składa się ze znaku startowego, zakodowanych danych i znaku stop., Zarówno znaki start, jak i stop są identyczne i są zazwyczaj reprezentowane przez symbol * gwiazdki. nie ma znaku sumy kontrolnej, ale niektóre funkcje sprawdzania błędów są wbudowane w system kodowania.
Kod 39 jest używany w wielu tego samego typu aplikacjach co Kod 128, istnieją też oficjalne standardy Code 39 (w tym standard ANSI). Nie jest on jednak uwzględniony w systemie GS1.
Interleaved 2 of 5
Interleaved 2 of 5 (lub ITF) jest liniowym kodem kreskowym o zmiennej długości., Koduje cyfry w parach, z pierwszą cyfrą w każdej parze reprezentowaną przez słupki, a drugą cyfrę reprezentowaną przez spacje, tak aby były przeplatane. Dwa z pięciu słupków lub spacji reprezentujących każdą cyfrę są szerokie, a pozostałe wąskie.

przeplatane 2 z 5 jest zawarte w systemie GS1 jako standard ITF-14, który ma ustawioną długość 14 cyfr.,
Kod kreskowy ITF składa się z kodu startowego (dwie pary wąskich pasków/wąskich spacji), zakodowanych danych, cyfry sumy kontrolnej (wymagana dla ITF-14, opcjonalnie w innym miejscu) i kodu stopu (szeroki pasek, wąska spacja, wąski pasek), ze strefami ciszy po obu stronach.
W zakodowanych danych mogą wystąpić wzorce identyczne z kodem startu i stopu, co może skutkować złym odczytem, jeśli skaner nie odczyta kodu do końca. Aby temu zapobiec, standard ITF-14 wymaga ciężkiej czarnej obwódki zwanej paskiem nośnika.,
Kody kreskowe ITF są zwykle używane w sprzedaży hurtowej i wysyłkowej dla kartonów lub kartonów produktów. Specjalna wersja kodu kreskowego ITF jest również używana na 135 kanistrach folii.
Codabar
Codabar został pierwotnie opracowany przez Pitneya Bowesa w 1972 roku. Jest to kod kreskowy o zmiennej długości, który wykorzystuje mały zestaw pasków do kodowania cyfr od 0 do 9, a w niektórych aplikacjach kilka symboli, takich jak znaki dolara i Plusa. zawiera również cztery symbole start/stop (zazwyczaj reprezentowane przez A, B, C i D). Kod Codabar składa się z symbolu startu, zakodowanych danych i symbolu stopu., jest to samokontrola, chociaż niektóre aplikacje określają cyfrę kontrolną.

Codabar jest tradycyjnie używany przez biblioteki, przez banki krwi oraz przez niektóre firmy, takie jak Federal Express, i nadal jest używany w niektórych z tych aplikacji.
Pharmacode
Pharmacode jest przeznaczony do kontroli i bezpieczeństwa opakowań w przemyśle farmaceutycznym.

Kod kreskowy APharmacode składa się tylko z dwóch szerokości pasków, o długości do 12 pasków., Dane są pojedynczą liczbą całkowitą (w zakresie od 3 do 131070) zakodowaną jako liczba binarna. Kody kreskowe Pharmacode mogą wykorzystywać wiele kolorów jako dodatkową kontrolę dokładności pakowania.

poszczególne firmy farmaceutyczne generują własne kody kreskowe kodów farmakologicznych. Są one stosowane na linii produkcyjnej, gdzie są automatycznie skanowane na wkładkach i innych elementach umieszczanych w opakowaniu, w celu wykrycia niedopasowania.
Databar
Databar to rodzina standardów kodów kreskowych GS1 przeznaczona głównie do zastosowań o ograniczonej przestrzeni., Kodują one dane GTIN-12 (UPC-A) i GTIN-13 (EAN-13) w formacie 14-cyfrowym (z dodanymi wiodącymi zerami). Liniowe Kody kreskowe z rodziny Databar obejmują kody dookólne i rozszerzone, które mogą być skanowane dookólnie, oraz kody skrócone i ograniczone, które są przeznaczone do odczytu wyłącznie przez skanery ręczne.

wielokierunkowe i rozszerzone kody baz danych są używane w aplikacjach punktowych, takich jak UPC-A i EAN-13., Rozszerzone kody mogą zawierać dodatkowe informacje, takie jak waga i data ważności, wyznaczone za pomocą identyfikatorów aplikacji w sposób kodów kreskowych GS1-128.

skrócone i ograniczone Kody kreskowe Databar są powszechnie używane w branży ochrony zdrowia do identyfikacji małych przedmiotów.

Postal (Postnet)
Postnet jest systemem kodów kreskowych używanym przez United States Postal Service do routingu poczty., Kody Postnet używają słupków o zmiennej wysokości do reprezentowania cyfr.
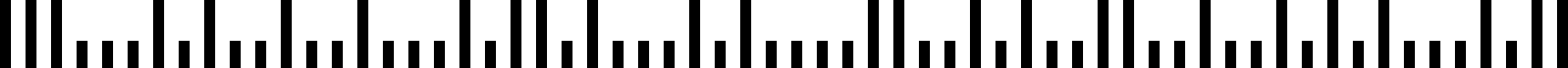
Kod kreskowy Postnet składa się zazwyczaj z kodów ZIP, ZIP+4 i punktów dostawy, z których każda cyfra jest reprezentowana przez pięć pasków, z których dwa są pełnej wysokości, a reszta w połowie wysokości.Postal (Inteligentny kod kreskowy poczty)
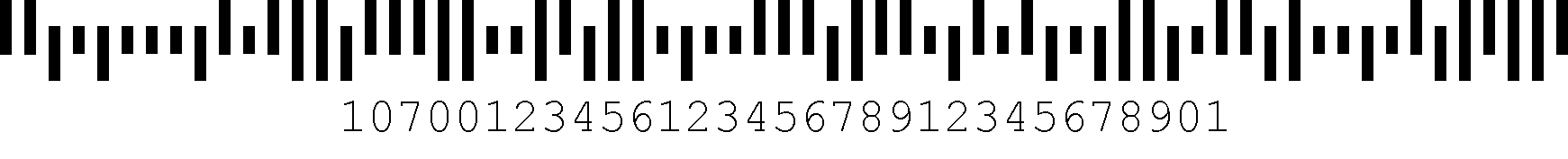
Inteligentny system kodów kreskowych poczty zastępuje system Postnet do routingu poczty przez USPS. Jest to kod o zmiennej wysokości 65 bar z czterema typami barów.,
i Kod IM barcode składa się z następujących składników:
Kody kreskowe ułożone w stos
Kody kreskowe ułożone w stos to liniowe Kody kreskowe, które są podzielone na segmenty i umieszczone jeden nad drugim

kody Databar ułożone w stos
ułożone w stos wersje kodów Databar GS1 używają tego samego podstawowego kodowania, co opisane powyżej liniowe kody Databar i są używane w podobnych aplikacjach. Są one szczególnie przydatne w przypadku przedmiotów o ograniczonej przestrzeni z etykietami o bardzo wąskich wymiarach liniowych., oprócz podstawowego kodu cenowego EAN-13, GS1 Expanded Stacked Databar może układać szereg kodów kreskowych zawierających dane produktów.
PDF417
PDF417 to kod kreskowy o zmiennej wysokości i zmiennej szerokości złożony z rzędów krótkich słupków i spacji. Może mieć aż 3 rzędy, lub aż 90. Wszystkie wiersze muszą zawierać tę samą liczbę słów kodowych danych, ale liczba ta może się wahać od 1 do 30.,

faktyczna metoda kodowania opiera się na złożonym systemie, który wykorzystuje około 900 kodowych słów do reprezentowania danych w różnych formatach. Umożliwia to PDF417 kodowanie tekstu, danych cyfrowych (w bajtach) i dużych liczb w ramach tego samego kodu kreskowego.
każdy wiersz kodu kreskowego PDF417 składa się ze wzoru początkowego, lewego słowa kodowego (identyfikującego między innymi wiersz), słów kodowych danych, prawego słowa kodowego i wzorca stop. W przeciwieństwie do większości kodów kreskowych 2D, PDF417 można odczytać za pomocą skanera laserowego.,
Kody kreskowe PDF417 mogą być łączone, dzięki czemu duże ilości danych mogą być skanowane w kolejności. To skutecznie usuwa limit ilości danych, które mogą być zakodowane, dzięki czemu format PDF417 jest konkurencyjny do prawdziwych kodów kreskowych 2-D, ponieważ reprezentuje duże ilości danych.
PDF417 jest używany jako format kodów kreskowych o dużej gęstości w wielu aplikacjach, w tym:
MicroPDF417
MicroPDF417 to Ograniczony podzbiór PDF417 przeznaczony do sytuacji, w których Pełny kod PDF417 byłby zbyt duży. Wprowadza ograniczenia dotyczące wymiarów słupków oraz ilości i formatu danych, które można zakodować(do 200 znaków tekstu pisanego wielkimi literami, 150 bajtów binarnych lub 366 cyfr). wprowadza również pewne ograniczenia w kodowych kodach korekcji błędów.
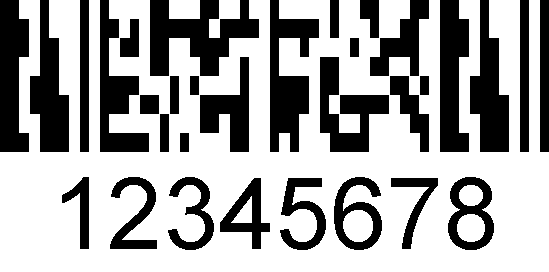
MicroPDF417 jest używany w kodach złożonych GS1 Databar, gdzie jest łączony z liniowym kodem kreskowym.,
Matryca 2D
w przeciwieństwie do kodów kreskowych, prawdziwe kody matrycy 2D reprezentują dane w dwuwymiarowej tablicy, jak kwadraty na szachownicy. Pozwala to na spakowanie dużej ilości danych w zwartą przestrzeń i reprezentowanie znacznie większego zestawu znaków. Kody te muszą być odczytywane za pomocą skanera obrazowego, a nie skanera laserowego.
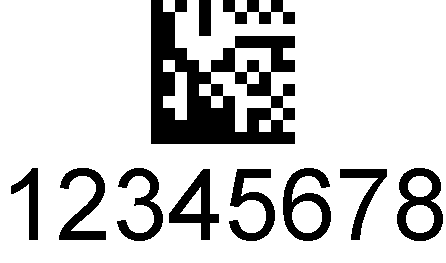
Kody kreskowe DataMatrix
Kody kreskowe DataMatrix są kwadratowymi lub prostokątnymi tablicami czarno-białych kwadratów lub komórek., Każda komórka jest bitem, reprezentującym jedynkę lub zero, a w zależności od rodzaju kodowania Kod kreskowy DataMatrix może reprezentować aż 2355 znaków alfanumerycznych.

kod DataMatrix ma dwa różne typy obramowania; na jednym zestawie sąsiednich stron obramowanie jest stałe, a na pozostałych dwóch stronach, na przemian czarne i białe komórki, co nadaje mu wygląd tylko dwóch stałych obramowań., Obramowania bryły lub Findera pozwalają skanerowi na orientację obrazu kodu, a obramowania komórki przemiennej lub timera umożliwiają liczenie wierszy i kolumn.
kody DataMatrix mogą być bardzo małe i mogą być odczytywane przy niskim kontraście. Dzięki temu można je drukować lub nawet wytrawiać laserowo na małych przedmiotach. Mogą być również skalowane do bardzo dużych rozmiarów do użytku na przedmiotach, takich jak ciężkie maszyny, budynki lub wagony kolejowe.,
rzeczywisty system kodowania jest złożony i obejmuje nadmiarowe przechowywanie danych, więc jeśli część kodu DataMatrix zostanie utracona lub uszkodzona, nadal może być możliwe odczytanie wszystkich danych. DataMatrix może kodować numery i alfanumeryczne znaki ASCII za pomocą kilku systemów kodowania i kompresji.
DataMatrix jest stosowany do etykietowania małych elementów w przemyśle elektronicznym, zarówno za pomocą drukowanych etykiet, jak i bezpośredniego znakowania; są również stosowane w przemyśle spożywczym do kontroli jakości.,Większość smartfonów może odczytywać kody DataMatrix, umożliwiając ich wykorzystanie w marketingu, reklamie i innych aplikacjach, w których pożądany jest dostęp do smartfonów.
kod QR
format kodu QR (lub Quick Response) został pierwotnie zaprojektowany do użytku w japońskim przemyśle motoryzacyjnym do śledzenia części i samochodów na linii montażowej. Ze względu na swoją wszechstronność, stał się szeroko stosowany w różnych zastosowaniach przemysłowych i konsumenckich.,

kod QR przypomina Kod DataMatrix; jest kwadratowy (otoczony pustą strefą) i składa się z kwadratowych czarnych i białych komórek. Ale zamiast obramowań, używa zestawu dużych kwadratów położenia i wyrównania (i mniejszego zestawu znaków czasu) ustawionych w ciele kodu.
QR code może kodować cztery różne typy danych: liczby, znaki alfanumeryczne, binarne / bajty i japońskie Kana / kanji., Kodowanie alfanumeryczne jest ograniczone do cyfr, wielkich liter i niektórych znaków interpunkcyjnych, ale kodowanie binarne / bajtowe obejmuje zestaw znaków ISO 8859-1 Latin-1, który w całości lub częściowo obejmuje języki zachodnioeuropejskie. Kodowanie Kana / kanji wykorzystuje zestaw znaków JIS X 0208. QR code może kodować adresy URL stron internetowych, umożliwiając użytkownikom telefonów komórkowych polubienie bezpośrednio strony internetowej poprzez skanowanie zakodowanego adresu URL.
rozmiar i gęstość kodu QR mogą się różnić, w zależności od ilości danych, które mają być przechowywane., Maksymalna pojemność pamięci wynosi około 7000 znaków numerycznych, 4200 znaków alfanumerycznych, 2900 znaków binarnych lub 1800 znaków kana / kanji. Kod QR można podzielić na kilka mniejszych kodów, pozwalając im zmieścić się w obszarze, w którym większy kod nie zmieściłby się.
QR kody odnotowały szybki wzrost liczby i zakresu zastosowań, do których są używane w ostatnich latach, po części dlatego, że mogą być łatwo odczytane przez smartfony, tablety i inne urządzenia mobilne., Obecne aplikacje QQR code obejmują:
wszechstronność, pojemność i dostępność kodu QR pozwala na korzystanie z niego na wiele nietypowych sposobów., Kody QR zostały umieszczone na dziełach sztuki, znaczkach, pieniądzach, nagrobkach, posągach, eksponatach muzealnych, szlakach turystycznych, okładkach komiksów, kartkach z życzeniami — prawie wszędzie, gdzie mogą się zmieścić i pełnić jakąś funkcję.
patenty na kod QR są w posiadaniu firmy Denso Wave (spółki zależnej Denso, która z kolei jest własnością Toyoty), która zdecydowała się nie korzystać ze swoich praw patentowych i zezwala na korzystanie z kodów bez żadnych wymogów licencyjnych.
oprócz aplikacji do odczytu kodów QR, dostępne są również bezpłatne oprogramowanie i Internetowe usługi do generowania kodów QR.,
Aztec
Kod kreskowy Aztec 2D przypomina kody DataMatrix i QR. Składa się z kwadratu czarnych i białych komórek (lub pikseli) z symbolem lokalizacyjnym złożonym z koncentrycznych kwadratów bezpośrednio w centrum. Obszar centralny (wokół kwadratowego oka byka) zawiera informacje o rozmiarze symbolu, wraz z innymi danymi kodowania. Oznacza to, że nie wymaga pustej strefy ani granicy. Kod zawiera również wewnętrzną siatkę odniesienia na przemian czarno-białych pikseli w każdym 16 wierszu i kolumnie.,

dane są ułożone w spiralę od środka na zewnątrz; każda warstwa spirali składa się z dwóch pierścieni pikseli, dodając cztery piksele do całkowitej szerokości. Centralny kwadrat bull ' s-eye plus Warstwa danych kodowania i rozmiaru tworzą razem rdzeń, który może być kompaktowy (11 X 11) lub pełny (15 X 15). Aztecki symbol o zwartym rdzeniu może mieć aż 4 warstwy. Symbol z pełnym rdzeniem może mieć 32 warstwy i może kodować ponad 3800 cyfr, 3000 znaków tekstu lub 1900 bajtów danych binarnych., Tekst może być kodowany jako ASCII i Latin-1; tryb kodowania może być zmieniany w wielu punktach w danych.
System Aztec code jest domeną publiczną, a aplikacje są dostępne do generowania kodów i odczytywania ich na urządzeniach mobilnych. Ze względu na podobieństwo w konstrukcji, czytelność i pojemność, kody Aztec mogą być używane w wielu aplikacjach, dla których kody QR stają się popularne, chociaż w praktyce ich użycie jest bardziej ograniczone.
kody Azteków są jednak dość powszechne w branży transportowej., Są one stosowane na elektronicznych kartach pokładowych linii lotniczych oraz w przypadku biletów kolejowych online i mobilnych w wielu częściach Europy.
ponadto są one wykorzystywane w systemach bilingowych kilku kanadyjskich korporacji, a polski rząd wykorzystuje je w swoim systemie rejestracji samochodów.
Maxicode
MaxiCode to kod kreskowy z matrycą 2D, który wygląda trochę jak kod aztecki, tylko z okrągłym środkiem tarczy zamiast kwadratu. Bliższe spojrzenie pokazuje inną różnicę — zamiast pikseli kwadratowych dane są zakodowane w sześciokątne kropki, które są ułożone w sześciokątny wzór.,

MaxiCode został zaprojektowany z myślą o wyspecjalizowanej funkcji — routingu i śledzenia pakietów United Parcel Service — i to nadal jest jego głównym zastosowaniem.
W przeciwieństwie do innych opisanych tu kodów macierzy 2D, Symbole MaxiCode mają stały rozmiar (około 1 cala kwadratu) i stałą ilość danych, które mogą być zakodowane (około 93 znaków, w zależności od trybu danych). Ponieważ wiele symboli MaxiCode może być połączonych lub połączonych łańcuchowo.,
w obecnym użyciu jest pięć trybów danych (a także dwa przestarzałe):
wszystkie te tryby mogą zawierać dodatkową wiadomość, która w przypadku wysyłki UPS zwykle zawiera bardziej szczegółowe informacje o wysyłce i śledzeniu. W trybach 4, 5 i 6 komunikat pomocniczy jest skutecznie scalany z Komunikatem głównym.
MaxiCode używa pięciu zestawów kodu; pojedyncza wiadomość może przełączać się między nimi wielokrotnie. Pięć zestawów kodów zawiera standardowy zestaw znaków ASCII oraz większość znaków Latin-1.