przegląd
- precyzja i przypomnienie to dwa kluczowe, ale niezrozumiałe tematy w uczeniu maszynowym
- omówimy, czym są precyzja i przypomnienie, jak działają i ich rola w ocenie modelu uczenia maszynowego
- uzyskamy również zrozumienie obszaru pod krzywą (AUC) i terminów dokładności
wprowadzenie
zapytaj każdego specjalistę od uczenia maszynowego lub analityka danych o najbardziej mylących pojęciach w ich podróży edukacyjnej., I niezmiennie, odpowiedź kieruje się w stronę precyzji i przypomnienia.
różnica między precyzją a przypomnieniem jest naprawdę łatwa do zapamiętania – ale tylko wtedy, gdy naprawdę zrozumiesz, co oznacza każdy termin. Ale dość często, i mogę to potwierdzić, eksperci mają tendencję do oferowania na wpół upieczonych wyjaśnień, które jeszcze bardziej mylą nowo przybyłych.
więc ustalmy rekord w tym artykule.

w przypadku każdego modelu uczenia maszynowego wiemy, że osiągnięcie „dobrego dopasowania” do modelu jest niezwykle ważne., Polega to na osiągnięciu równowagi między niedopasowaniem i nadmiernym dopasowaniem, lub innymi słowy, kompromisu między odchyleniem a wariancją.
jednak, jeśli chodzi o klasyfikację – istnieje inny kompromis, który jest często pomijany na rzecz kompromisu bias-variance. To jest Precision-recall tradeoff. Klasy niezrównoważone występują często w zestawach danych, a jeśli chodzi o konkretne przypadki użycia, chcielibyśmy w rzeczywistości nadać większą wagę precyzji i metrykom przypominania, a także sposobowi osiągnięcia równowagi między nimi.
ale jak to zrobić?, W tym artykule zbadamy wskaźniki oceny klasyfikacji, koncentrując się na precyzji i przypomnieniu. Nauczymy się również, jak obliczać te metryki w Pythonie, biorąc zestaw danych i prosty algorytm klasyfikacji. Więc zaczynajmy!
Szczegółowe informacje o metrykach ewaluacyjnych można znaleźć tutaj-metryki ewaluacyjne dla modeli uczenia maszynowego.
spis treści
- zrozumienie problemu
- co to jest precyzja?
- co to jest Recall?,
- najprostsza Metryka oceny – dokładność
- rola wyniku F1
- słynny kompromis precyzji-Przypomnienie
- zrozumienie obszaru pod krzywą (AUC)
zrozumienie problemu
mocno wierzę w uczenie się przez działanie. Więc w całym tym artykule, będziemy rozmawiać w praktyczny sposób-za pomocą zestawu danych.
przejdźmy do popularnego zbioru danych o chorobach serca dostępnego w repozytorium UCI. Tutaj musimy przewidzieć, czy pacjent cierpi na dolegliwość serca, czy nie korzysta z danego zestawu funkcji., Możesz pobrać czysty zbiór danych stąd.
ponieważ ten artykuł skupia się wyłącznie na metrykach oceny modelu, użyjemy najprostszego klasyfikatora-modelu klasyfikacji kNN do tworzenia prognoz.
jak zwykle zaczniemy od zaimportowania niezbędnych bibliotek i pakietów:
następnie przyjrzyjmy się danym i zmiennym docelowym, z którymi mamy do czynienia:
Sprawdźmy czy nie mamy brakujących wartości:
nie ma brakujących wartości., Teraz możemy przyjrzeć się, ilu pacjentów rzeczywiście cierpi na choroby serca (1), a ilu Nie (0):
oto wykres liczby poniżej:
kontynuujmy dzieląc nasze dane treningowe i testowe oraz nasze zmienne wejściowe i docelowe. Ponieważ używamy KNN, obowiązkowe jest skalowanie naszych zbiorów danych również:
intuicja stojąca za wyborem najlepszej wartości k wykracza poza zakres tego artykułu, ale powinniśmy wiedzieć, że możemy określić optymalną wartość k, gdy otrzymamy najwyższy wynik testu dla tej wartości., W tym celu możemy ocenić wyniki treningu i testów dla maksymalnie 20 najbliższych sąsiadów:
aby ocenić maksymalny wynik testu i związane z nim wartości k, uruchom następujące polecenie:

w ten sposób uzyskaliśmy optymalną wartość k na 3, 11 lub 20 z wynikiem 3, 11 lub 20.83.5. Sfinalizujemy jedną z tych wartości i odpowiednio dopasujemy model:

jak teraz ocenić, czy ten model jest 'dobrym' modelem, czy nie?, W tym celu używamy czegoś, co nazywa się Macierzą zamieszania:
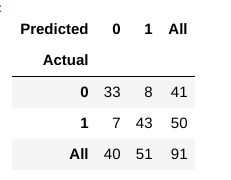
macierz zamieszania pomaga nam uzyskać wgląd w poprawność naszych prognoz i ich zgodność z rzeczywistymi wartościami.
z naszych danych dotyczących pociągów i testów wiemy już, że nasze dane testowe składały się z 91 punktów danych. Jest to wartość 3. wiersza i 3. kolumny na końcu. Zauważamy również, że istnieją pewne rzeczywiste i przewidywane wartości. Rzeczywiste wartości to liczba punktów danych, które zostały pierwotnie sklasyfikowane na 0 LUB 1., Przewidywane wartości to liczba punktów danych naszego modelu KNN przewidywana jako 0 LUB 1.
rzeczywiste wartości to:
- pacjenci, którzy faktycznie nie mają choroby serca = 41
- pacjenci, którzy faktycznie mają chorobę serca = 50
przewidywane wartości to:
- liczba pacjentów, których przewidywano brak choroby serca = 40
- liczba pacjentów, których przewidywano brak choroby serca = 51
wszystkie wartości, które otrzymujemy powyżej mają termin., Przejdźmy do nich jeden po drugim:
- przypadki, w których pacjenci faktycznie nie mieli choroby serca, a nasz model przewidywał również, że jej nie ma, nazywa się prawdziwymi negatywami. Dla naszej macierzy prawdziwe negatywy = 33.
- przypadki, w których pacjenci rzeczywiście chorują na choroby serca i Nasz model również przewidywał, że go mają, nazywane są prawdziwymi pozytywami. Dla naszej matrycy, True Positives = 43
- istnieją jednak przypadki, w których pacjent faktycznie nie ma choroby serca, ale nasz model przewiduje, że tak., Ten rodzaj błędu jest błędem typu I, A wartości nazywamy fałszywymi alarmami. Dla naszej matrycy, False Positives = 8
- Podobnie, są przypadki, w których pacjent rzeczywiście ma chorobę serca, ale nasz model przewiduje, że on / ona nie. tego rodzaju błąd jest typu II błąd i nazywamy wartości jako False Negatives. Dla naszej matrycy, False Negatives = 7
czym jest precyzja?
racja – więc teraz dochodzimy do sedna tego artykułu. Czym jest precyzja? A co ma z tym wspólnego Cała powyższa nauka?,
w najprostszych słowach precyzja to stosunek między prawdziwymi dodatkami a wszystkimi dodatkami. Dla naszego problemu stwierdzenie, że byłoby miarą pacjentów, że prawidłowo zidentyfikować choroby serca z wszystkich pacjentów faktycznie mających to. Matematycznie:

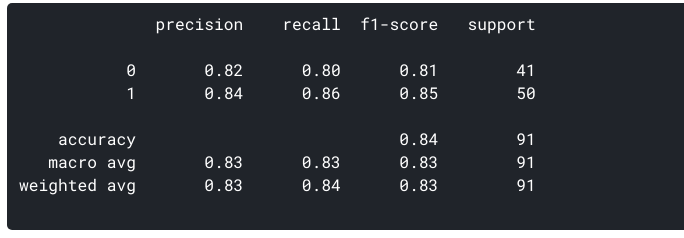
Jaka jest precyzja dla naszego modelu? Tak, jest to 0,843 lub, gdy przewiduje, że pacjent ma choroby serca, to jest prawidłowe około 84% czasu.
precyzja daje nam również pomiar odpowiednich punktów danych., Ważne jest, abyśmy nie zaczęli leczyć pacjenta, który faktycznie nie ma choroby serca, ale nasz model przewidywał, że ją ma.
Co To jest Recall?
Przypomnienie jest miarą naszego modelu poprawnie identyfikującego prawdziwe pozytywy. Tak więc, dla wszystkich pacjentów, którzy rzeczywiście mają choroby serca, przypomnienie mówi nam, jak wielu prawidłowo zidentyfikowaliśmy jako posiadające choroby serca. Matematycznie:

dla naszego modelu, Recall = 0.86. Recall daje również miarę tego, jak dokładnie Nasz model jest w stanie zidentyfikować odpowiednie dane., Określamy ją jako czułość lub rzeczywisty wskaźnik dodatni. Co zrobić, jeśli pacjent ma chorobę serca, ale nie ma leczenia dla niego / jej, ponieważ nasz model przewidział tak? To jest sytuacja, której chcielibyśmy uniknąć!
najprostsza Metryka do zrozumienia – dokładność
teraz dochodzimy do jednej z najprostszych metryk ze wszystkich, dokładności. Dokładność to stosunek całkowitej liczby poprawnych prognoz do całkowitej liczby prognoz. Czy wiesz, jaki będzie wzór na dokładność?
dla naszego modelu dokładność wyniesie 0.835.,
używanie dokładności jako metryki definiującej nasz model ma sens intuicyjnie, ale częściej niż nie, zawsze wskazane jest użycie precyzji i przypomnienia. Mogą być inne sytuacje, w których nasza dokładność jest bardzo wysoka, ale nasza precyzja lub pamięć jest niska. Idealnie, dla naszego modelu, chcielibyśmy całkowicie uniknąć sytuacji, w których pacjent ma choroby serca, ale nasz model klasyfikuje się jako nie ma go tj. dążyć do wysokiej przypomnieć.,
z drugiej strony, w przypadkach, gdy pacjent nie cierpi na choroby serca, a nasz model przewiduje coś przeciwnego, chcielibyśmy również uniknąć leczenia pacjenta bez chorób serca(istotne, gdy parametry wejściowe mogą wskazywać na inną dolegliwość, ale ostatecznie leczymy go na dolegliwość serca).
chociaż dążymy do wysokiej precyzji i wysokiej wartości przywoływania, osiągnięcie obu w tym samym czasie nie jest możliwe., Na przykład, jeśli zmienimy model na taki, który zapewni nam wysoką pamięć, możemy wykryć wszystkich pacjentów, którzy rzeczywiście mają choroby serca, ale możemy skończyć dając leczenie wielu pacjentom, którzy nie cierpią z tego powodu.
Podobnie, jeśli dążymy do wysokiej precyzji, aby uniknąć niewłaściwego i nieodwracalnego leczenia, w końcu otrzymujemy wielu pacjentów, którzy rzeczywiście mają chorobę serca, bez żadnego leczenia.
rola F1-Score
zrozumienie dokładności uświadomiło nam, że potrzebujemy kompromisu między precyzją a przypomnieniem., Najpierw musimy zdecydować, co jest ważniejsze dla naszego problemu klasyfikacji.
na przykład dla naszego zbioru danych możemy uznać, że osiągnięcie wysokiego poziomu przywołania jest ważniejsze niż uzyskanie wysokiej precyzji – chcielibyśmy wykryć jak najwięcej pacjentów serca, jak to możliwe. W przypadku niektórych innych modeli, takich jak klasyfikowanie, czy klient banku jest niewypłacalny, czy nie, pożądane jest, aby mieć wysoką precyzję, ponieważ bank nie chciałby stracić klientów, którym odmówiono pożyczki na podstawie prognozy modelu, że będą niewypłacalni.,
jest też wiele sytuacji, w których zarówno precyzja, jak i przypomnienie są równie ważne. Na przykład dla naszego modelu, jeśli lekarz poinformuje nas, że pacjenci, którzy zostali błędnie zaklasyfikowani jako cierpiący na choroby serca, są równie ważni, ponieważ mogą wskazywać na jakąś inną dolegliwość, wówczas dążymy nie tylko do wysokiej powtarzalności, ale także do wysokiej precyzji.
w takich przypadkach używamy czegoś o nazwie F1-score., Wynik F1 jest średnią harmoniczną precyzji i przypomnienia:

jest to łatwiejsze do pracy od teraz, zamiast równoważenia precyzji i przypomnienia, możemy po prostu dążyć do dobrego wyniku F1, co byłoby wskaźnikiem dobrej precyzji i dobrej wartości Przywołania.,
możemy wygenerować powyższe dane dla naszego zbioru za pomocą sklepu:
Krzywa ROC
wraz z powyższymi określeniami, istnieje więcej wartości, które możemy obliczyć z macierzy zamieszania:
- wskaźnik fałszywie dodatni (FPR): jest to współczynnik False Positive Rate (FPR): false positives do rzeczywistej liczby negatywów. W kontekście naszego modelu jest to miara liczby przypadków, w których model przewiduje, że pacjent ma chorobę serca od wszystkich pacjentów, którzy faktycznie nie mieli choroby serca. Dla naszych danych FPR wynosi = 0.,195
- True Negative Rate (TNR) lub swoistość: jest to stosunek prawdziwych negatywów i rzeczywistej liczby negatywów. Dla naszego modelu jest to miara liczby przypadków, w których model prawidłowo przewidział, że pacjent nie ma chorób serca od wszystkich pacjentów, którzy faktycznie nie mieli chorób serca. TNR dla powyższych danych = 0,804. Z tych 2 definicji możemy również wnioskować, że specyficzność lub TNR = 1-FPR
możemy również wizualizować precyzję i przywoływanie za pomocą krzywych ROC i krzywych PRC.,
krzywe ROC(charakterystyka pracy odbiornika):
jest to Wykres pomiędzy TPR(oś y) i FPR(oś x). Ponieważ nasz model klasyfikuje pacjenta jako chorego na choroby serca lub nie na podstawie prawdopodobieństwa generowanego dla każdej klasy, możemy również określić próg prawdopodobieństwa.
na przykład chcemy ustawić wartość progową 0.4. Oznacza to, że model klasyfikuje punkt danych / pacjenta jako chorego na chorobę serca, jeśli prawdopodobieństwo wystąpienia choroby serca u pacjenta jest większe niż 0,4., To oczywiście da wysoką wartość przywoływania i zmniejszy liczbę fałszywych alarmów. Podobnie, możemy wizualizować, jak nasz model działa dla różnych wartości progowych za pomocą krzywej ROC.
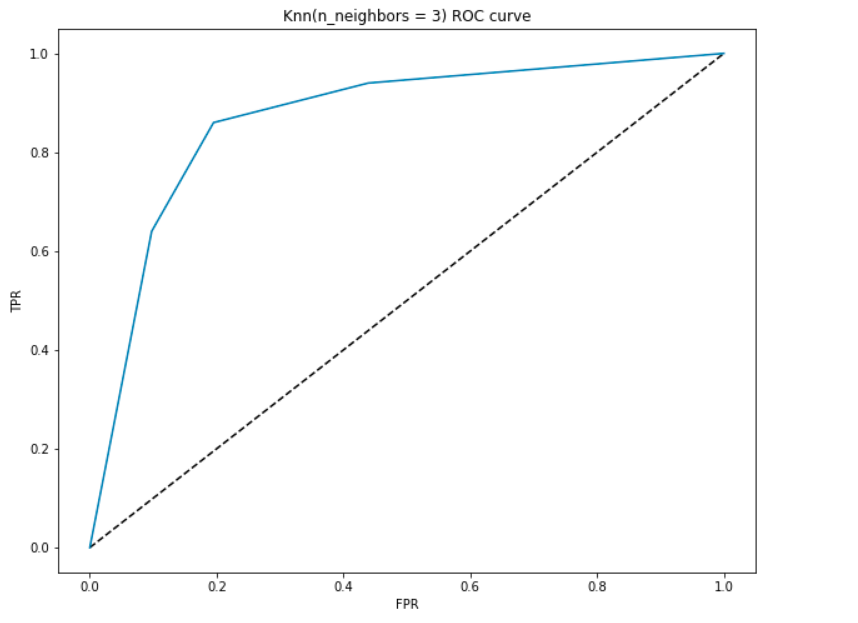
wygenerujmy krzywą ROC dla naszego modelu z k = 3.
interpretacja AUC-
- w najniższym punkcie, tj. w (0, 0)- próg jest ustawiony na 1,0. Oznacza to, że nasz model klasyfikuje wszystkich pacjentów jako nie mających choroby serca.
- w najwyższym punkcie tj. w (1, 1) próg jest ustawiony na 0,0., Oznacza to, że nasz model klasyfikuje wszystkich pacjentów jako cierpiących na choroby serca.
- reszta krzywej to wartości FPR i TPR dla wartości progowych z zakresu od 0 do 1. Przy pewnej wartości progowej obserwujemy, że dla FPR zbliżonego do 0 osiągamy TPR zbliżony do 1. To jest, gdy model będzie przewidywać pacjentów z chorobami serca prawie idealnie.
- obszar z krzywą i osiami jako granicami nazywa się obszarem pod krzywą (AUC). To właśnie ten obszar jest uważany za metrykę dobrego modelu., Przy tej metryce w zakresie od 0 do 1, powinniśmy dążyć do wysokiej wartości AUC. Modele o wysokim AUC nazywane są modelami z dobrymi umiejętnościami. Obliczmy wynik AUC dla naszego modelu i powyższego wykresu:

- otrzymujemy wartość 0.868 jako AUC, co jest całkiem dobrym wynikiem! W najprostszym ujęciu oznacza to, że model będzie w stanie odróżnić pacjentów z chorobami serca i tych, którzy nie 87% czasu. Możemy poprawić ten wynik i zachęcam do wypróbowania różnych wartości hiperparametrów.,
- linia diagonalna to model losowy o wartości AUC 0,5, model bez umiejętności, który jest taki sam jak robienie losowej prognozy. Wiesz dlaczego?
Krzywa Precision-Recall (PRC)
jak sama nazwa wskazuje, krzywa ta jest bezpośrednią reprezentacją precyzji(oś y) i przywołania(oś x). Jeśli zaobserwujesz nasze definicje i formuły precyzji i przypomnienia powyżej, zauważysz, że w żadnym momencie nie używamy prawdziwych negatywów (rzeczywista liczba osób, które nie mają chorób serca).,
jest to szczególnie przydatne w sytuacjach, w których mamy niezrównoważony zestaw danych, a liczba negatywów jest znacznie większa niż pozytywów (lub gdy liczba pacjentów nie mających choroby serca jest znacznie większa niż pacjenci mający go). W takich przypadkach naszym większym zmartwieniem byłoby wykrycie pacjentów z chorobami serca tak poprawnie, jak to możliwe i nie potrzebowaliby TNR.
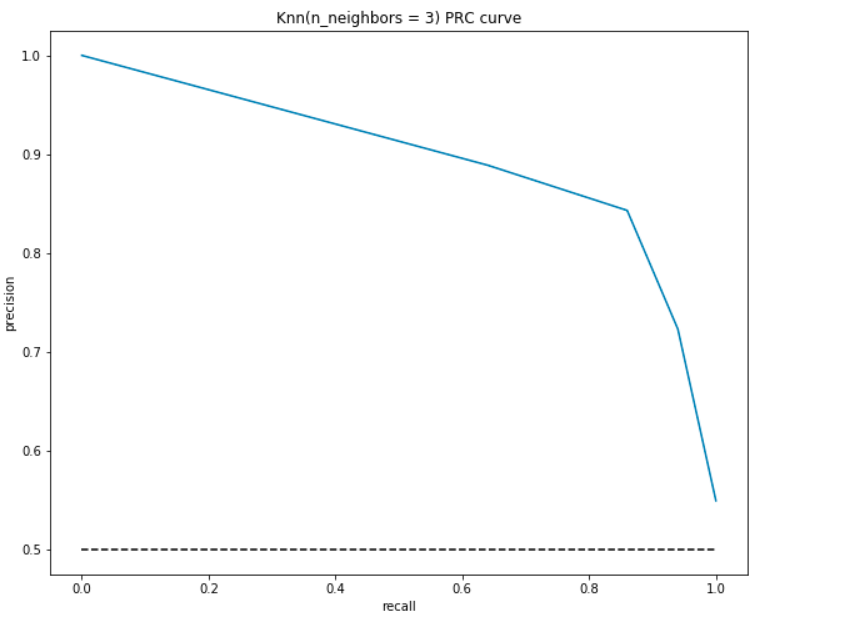
podobnie jak ROC, wykreślamy dokładność i przywołujemy dla różnych wartości progowych:
interpretacja PRC:
- w najniższym punkcie, tj., at (0, 0)- próg wynosi 1,0. Oznacza to, że nasz model nie rozróżnia pacjentów z chorobami serca i pacjentów, którzy nie mają.
- w najwyższym punkcie, tj. w (1, 1), próg jest ustawiony na 0,0. Oznacza to, że zarówno nasza precyzja, jak i przypomnienie są wysokie, a model doskonale rozróżnia.
- reszta krzywej to wartości precyzji i przypomnienia dla wartości progowych z zakresu od 0 do 1. Naszym celem jest, aby krzywa była jak najbliżej (1, 1), Jak to możliwe – co oznacza dobrą precyzję i przypomnienie.,
- podobnie jak ROC, obszar z krzywą i osiami jako granicami jest obszarem pod krzywą (AUC). Potraktuj ten obszar jako metrykę dobrego modelu. Wartości AUC wahają się od 0 do 1. Dlatego powinniśmy dążyć do wysokiej wartości AUC. Obliczmy AUC dla naszego modelu i powyższego wykresu:

tak jak wcześniej, otrzymujemy dobre AUC około 90%. Ponadto model może osiągnąć wysoką precyzję z wycofaniem jako 0 i osiągnie wysoki poziom wycofywania, zmniejszając precyzję o 50%.,
Uwagi końcowe
podsumowując, w tym artykule zobaczyliśmy, jak ocenić model klasyfikacji, szczególnie koncentrując się na precyzji i przypomnieniu, i znaleźć równowagę między nimi. Wyjaśniamy również, jak reprezentować wydajność naszego modelu za pomocą różnych wskaźników i macierzy zamieszania.
oto dodatkowy artykuł do zrozumienia wskaźników ewaluacji-11 ważnych wskaźników ewaluacji modelu dla uczenia maszynowego, które każdy powinien znać