Überblick
- Precision und recall sind zwei entscheidende noch missverstanden topics in machine learning
- Wir werden besprechen, was für precision und recall sind, wie Sie funktionieren, und Ihre Rolle in der Bewertung eines machine-learning-Modell
- Wir werden auch einen Einblick in die Fläche Unter der Kurve (AUC) und Genauigkeit Begriffe
Einführung
Fragen machine learning professional oder Daten, die Wissenschaftler über die verwirrendsten Konzepte in Ihre Lern-Reise., Und ausnahmslos neigt sich die Antwort in Richtung Präzision und Rückruf.
Der Unterschied zwischen Präzision und Rückruf ist eigentlich leicht zu merken – aber nur, wenn Sie wirklich verstanden haben, wofür jeder Begriff steht. Aber oft, und das kann ich bezeugen, neigen Experten dazu, halbgebackene Erklärungen anzubieten, die Neuankömmlinge noch mehr verwirren.
Also lassen Sie uns den Rekord gerade in diesem Artikel.

Für jedes Modell des maschinellen Lernens wissen wir, dass es äußerst wichtig ist, eine „gute Passform“ für das Modell zu erreichen., Dies beinhaltet das Erreichen des Gleichgewichts zwischen Unter-und Überanpassung oder mit anderen Worten einen Kompromiss zwischen Bias und Varianz.
Wenn es jedoch um die Klassifizierung geht, gibt es einen weiteren Kompromiss, der oft zugunsten des Bias-Varianz-Kompromisses übersehen wird. Dies ist der Precision-Recall-Kompromiss. Unausgeglichene Klassen treten häufig in Datensätzen auf, und wenn es um bestimmte Anwendungsfälle geht, möchten wir der Genauigkeit und den Rückrufmetriken sowie der Frage, wie das Gleichgewicht zwischen ihnen erreicht werden kann, mehr Bedeutung beimessen.
Aber wie geht das?, Wir werden die Klassifizierungsbewertungsmetriken untersuchen, indem wir uns in diesem Artikel auf Präzision und Rückruf konzentrieren. Wir werden auch lernen, wie man diese Metriken in Python berechnet, indem man einen Datensatz und einen einfachen Klassifizierungsalgorithmus verwendet. Also, lass uns anfangen!
Hier erfahren Sie mehr über Bewertungsmetriken-Bewertungsmetriken für Modelle des maschinellen Lernens.
Inhaltsverzeichnis
- Verständnis der Problemanweisung
- Was ist Präzision?
- Was ist Erinnern?,
- Die Einfachste Auswertung Metrik – Genauigkeit
- Die Rolle der F1-Score
- Die Berühmten Precision-Recall-Abwägung
- Verständnis der Fläche Unter der Kurve (AUC)
das Verständnis der Aufgabenstellung
ich glaube fest an „learning by doing“. In diesem Artikel werden wir also praktisch sprechen – mit einem Datensatz.
Nehmen wir den beliebten Datensatz für Herzerkrankungen auf, der im UCI-Repository verfügbar ist. Hier müssen wir vorhersagen, ob der Patient an einer Herzerkrankung leidet oder die angegebenen Merkmale nicht verwendet., Sie können den sauberen Datensatz von hier herunterladen.
Da sich dieser Artikel ausschließlich auf Modellbewertungsmetriken konzentriert, verwenden wir den einfachsten Klassifikator – das kNN-Klassifizierungsmodell, um Vorhersagen zu treffen.
Wie immer beginnen wir mit dem Import der notwendigen Bibliotheken und Pakete:
Dann werfen wir einen Blick auf die Daten und die Zielvariablen, mit denen wir es zu tun haben:
Lassen Sie uns überprüfen, ob wir fehlende Werte haben:
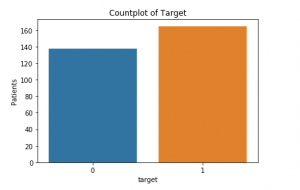
Es fehlen keine Werte., Jetzt können wir uns ansehen, wie viele Patienten tatsächlich an einer Herzerkrankung leiden (1) und wie viele nicht (0):
Dies ist das folgende Zähldiagramm:
Lassen Sie uns fortfahren, indem Sie unsere Trainings-und Testdaten sowie unsere Eingabe-und Zielvariablen aufteilen. Da wir KNN verwenden, müssen auch unsere Datensätze skaliert werden:
Die Intuition hinter der Auswahl des besten Werts von k geht über den Rahmen dieses Artikels hinaus, aber wir sollten wissen, dass wir den optimalen Wert von k bestimmen können, wenn wir den höchsten Testwert für diesen Wert erhalten., Dazu können wir die Trainings-und Testergebnisse für bis zu 20 nächste Nachbarn auswerten:
Um den maximalen Testwert und die damit verbundenen k Werte zu bewerten, führen Sie den folgenden Befehl aus:

Somit haben wir den optimalen Wert von k auf 3, 11 oder 20 mit einer Punktzahl von 83,5 erhalten. Wir werden einen dieser Werte abschließen und das Modell entsprechend anpassen:

Wie bewerten wir nun, ob dieses Modell ein „gutes“ Modell ist oder nicht?, Dazu verwenden wir etwas, das als Verwirrungsmatrix bezeichnet wird:
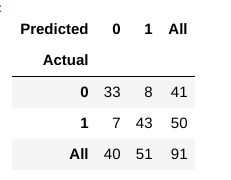
Eine Verwirrungsmatrix hilft uns, einen Einblick in die Richtigkeit unserer Vorhersagen zu erhalten und wie sie sich gegen die tatsächlichen Werte halten.
Aus unseren Zug – und Testdaten wissen wir bereits, dass unsere Testdaten aus 91 Datenpunkten bestanden. Das ist der Wert der 3.Zeile und 3. Spalte am Ende. Wir stellen auch fest, dass es einige tatsächliche und vorhergesagte Werte gibt. Die tatsächlichen Werte sind die Anzahl der Datenpunkte, die ursprünglich in 0 oder 1 kategorisiert wurden., Die vorhergesagten Werte sind die Anzahl der Datenpunkte, die unser KNN-Modell als 0 oder 1 vorhergesagt hat.
Die tatsächlichen Werte sind:
- Die Patienten, die tatsächlich keine Herzkrankheit haben = 41
- Die Patienten, die tatsächlich eine Herzkrankheit haben = 50
Die vorhergesagten Werte sind:
- Anzahl der Patienten, die vorhergesagt wurden, dass sie keine Herzkrankheit haben = 40
- Anzahl der Patienten, denen eine Herzkrankheit vorhergesagt wurde = 51
Alle Werte wir erhalten oben haben einen Begriff., Lassen Sie uns sie einzeln durchgehen:
- Die Fälle, in denen die Patienten tatsächlich keine Herzkrankheit hatten und unser Modell auch vorhergesagt hat, dass sie es nicht haben, werden als Wahre Negative bezeichnet. Für unsere Matrix sind Wahre Negative = 33.
- Die Fälle, in denen die Patienten tatsächlich eine Herzerkrankung haben, und unser Modell, das auch vorhergesagt wurde, werden als das wahre Positive bezeichnet. Für unsere Matrix True Positive = 43
- Es gibt jedoch einige Fälle, in denen der Patient tatsächlich keine Herzerkrankung hat, aber unser Modell hat vorausgesagt, dass dies der Fall ist., Diese Art von Fehler ist der Fehler vom Typ I und wir nennen die Werte als falsch positiv. Für unsere Matrix, False Positive = 8
- Ähnlich gibt es einige Fälle, in denen der Patient tatsächlich eine Herzerkrankung hat, aber unser Modell hat vorhergesagt, dass er/sie dies nicht tut. Diese Art von Fehler ist der Typ-II-Fehler und wir nennen die Werte als False Negative. Für unsere Matrix sind False Negative = 7
Was ist Präzision?
Richtig-jetzt kommen wir zum Kern dieses Artikels. Was in der Welt ist Präzision? Und was hat all das obige Lernen damit zu tun?,
Im einfachsten Sinne ist Präzision das Verhältnis zwischen den wahren Positiven und allen Positiven. Für unsere Problemaussage wäre das das Maß der Patienten, dass wir von allen Patienten, die es tatsächlich haben, eine Herzerkrankung richtig identifizieren. Mathematisch:

Was ist die Genauigkeit für unser Modell? Ja, es ist 0,843 oder, wenn es vorhersagt, dass ein Patient eine Herzerkrankung hat, ist es in etwa 84% der Fälle korrekt.
Präzision gibt uns auch ein Maß für die relevanten Datenpunkte., Es ist wichtig, dass wir nicht anfangen, einen Patienten zu behandeln, der tatsächlich keine Herzkrankheit hat, aber unser Modell sagt voraus, dass wir es haben.
Was ist Erinnern?
Der Rückruf ist das Maß für unser Modell, das wahre Positive korrekt identifiziert. Für alle Patienten, die tatsächlich an einer Herzerkrankung leiden, sagt uns Recall, wie viele wir korrekt als Herzkrankheit identifiziert haben. Mathematisch:

Für unser Modell, Recall = 0.86. Recall gibt auch ein Maß dafür, wie genau unser Modell die relevanten Daten identifizieren kann., Wir bezeichnen es als Empfindlichkeit oder wahre positive Rate. Was ist, wenn ein Patient eine Herzerkrankung hat, aber es wird ihm/ihr keine Behandlung gegeben, weil unser Modell dies vorhergesagt hat? Das ist eine situation, die wir vermeiden möchten!
Die am einfachsten zu verstehende Metrik – Genauigkeit
Jetzt kommen wir zu einer der einfachsten Metriken von allen, Genauigkeit. Genauigkeit ist das Verhältnis der Gesamtzahl der korrekten Vorhersagen und der Gesamtzahl der Vorhersagen. Können Sie erraten, was die Formel für die Genauigkeit sein wird?
![]()
Für unser Modell, Genauigkeit = 0.835.,
Die Verwendung von Genauigkeit als definierende Metrik für unser Modell ist intuitiv sinnvoll, aber meistens ist es immer ratsam, auch Präzision und Rückruf zu verwenden. Es könnte andere Situationen geben, in denen unsere Genauigkeit sehr hoch ist, aber unsere Präzision oder Rückruf ist gering. Idealerweise möchten wir für unser Modell Situationen, in denen der Patient an einer Herzerkrankung leidet, vollständig vermeiden, aber unser Modell klassifiziert, dass er es nicht hat, dh auf einen hohen Rückruf abzielen.,
Andererseits möchten wir für die Fälle, in denen der Patient nicht an Herzerkrankungen leidet und unser Modell das Gegenteil vorhersagt, auch vermeiden, einen Patienten ohne Herzerkrankungen zu behandeln(entscheidend, wenn die Eingabeparameter auf eine andere Krankheit hinweisen könnten, aber wir behandeln ihn/sie für eine Herzerkrankung).
Obwohl wir hohe Präzision und hohen Rückrufwert anstreben, ist beides gleichzeitig nicht möglich., Wenn wir beispielsweise das Modell in eines mit hohem Rückruf ändern, erkennen wir möglicherweise alle Patienten, die tatsächlich an einer Herzerkrankung leiden, aber am Ende können wir viele Patienten behandeln, die nicht darunter leiden.
Wenn wir eine hohe Präzision anstreben, um eine falsche und unerwiderte Behandlung zu vermeiden, bekommen wir am Ende viele Patienten, die tatsächlich an einer Herzerkrankung leiden, die ohne Behandlung auskommen.
Die Rolle des F1-Scores
Das Verständnis der Genauigkeit hat uns klar gemacht, dass wir einen Kompromiss zwischen Präzision und Rückruf benötigen., Wir müssen zuerst entscheiden, welches für unser Klassifizierungsproblem wichtiger ist.
Zum Beispiel können wir für unseren Datensatz berücksichtigen, dass das Erreichen eines hohen Rückrufs wichtiger ist als eine hohe Präzision – wir möchten so viele Herzpatienten wie möglich erkennen. Für einige andere Modelle, wie die Klassifizierung, ob ein Bankkunde ein Kreditausfall ist oder nicht, ist es wünschenswert, eine hohe Präzision zu haben, da die Bank keine Kunden verlieren möchte, denen ein Kredit verweigert wurde, basierend auf der Vorhersage des Modells, dass sie Säumige wären.,
Es gibt auch viele Situationen, in denen Präzision und Rückruf gleichermaßen wichtig sind. Wenn uns der Arzt beispielsweise für unser Modell mitteilt, dass die Patienten, die fälschlicherweise als Herzkrankheiten eingestuft wurden, gleichermaßen wichtig sind, da sie auf eine andere Erkrankung hinweisen könnten, möchten wir nicht nur einen hohen Rückruf, sondern auch eine hohe Präzision anstreben.
In solchen Fällen verwenden wir etwas namens F1-Score., F1-Score ist das harmonische Mittel der Präzision und des Rückrufs:

Dies ist einfacher zu arbeiten, da wir jetzt, anstatt Präzision und Rückruf auszugleichen, nur einen guten F1-Score anstreben können und das wäre ein Hinweis auf eine gute Präzision und einen guten Rückrufwert.,
Wir können die obigen Metriken für unseren Datensatz auch mit sklearn generieren:
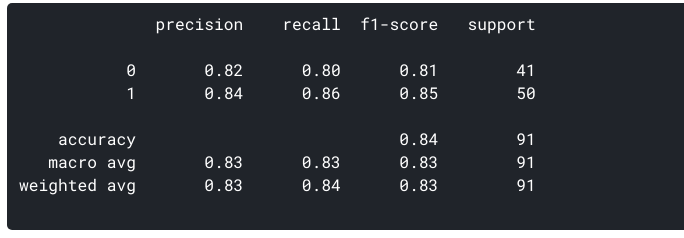
ROC Curve
Zusammen mit den obigen Begriffen gibt es weitere Werte, die wir aus der Verwirrungsmatrix berechnen können:
- False Positive Rate (FPR): Dies ist das Verhältnis der falsch positiven zur tatsächlichen Anzahl der Negativen. Im Rahmen unseres Modells ist es ein Maß dafür, wie viele Fälle das Modell vorhergesagt hat, dass der Patient eine Herzerkrankung von allen Patienten hat, die die Herzerkrankung tatsächlich nicht hatten. Für unsere Daten ist der FPR = 0.,195
- True Negative Rate (TNR) oder die Spezifität: Es ist das Verhältnis der wahren Negativen und der tatsächlichen Anzahl von Negativen. Für unser Modell ist es das Maß dafür, wie viele Fälle das Modell richtig vorhergesagt hat, dass der Patient keine Herzkrankheit von allen Patienten hat, die tatsächlich keine Herzkrankheit hatten. Der TNR für die obigen Daten = 0.804. Aus diesen 2 Definitionen können wir auch schließen, dass Spezifität oder TNR = 1-FPR
Wir können auch Präzision und Rückruf mithilfe von ROC-Kurven und PRC-Kurven visualisieren.,
ROC-Kurven (Receiver Operating Characteristic Curve):
Es ist der Plot zwischen TPR(y-Achse) und FPR(x-Achse). Da unser Modell den Patienten anhand der für jede Klasse generierten Wahrscheinlichkeiten als Herzkrankheit klassifiziert oder nicht, können wir auch den Schwellenwert der Wahrscheinlichkeiten festlegen.
Zum Beispiel möchten wir einen Schwellenwert von 0,4 festlegen. Dies bedeutet, dass das Modell den Datenpunkt/Patienten als Herzkrankheit klassifiziert, wenn die Wahrscheinlichkeit, dass der Patient eine Herzerkrankung hat, größer als 0,4 ist., Dies ergibt offensichtlich einen hohen Rückrufwert und reduziert die Anzahl der Fehlalarme. Ebenso können wir mithilfe der ROC-Kurve visualisieren, wie unser Modell für verschiedene Schwellenwerte abschneidet.
Lassen Sie uns eine ROC-Kurve für unser Modell mit k = 3 erzeugen.
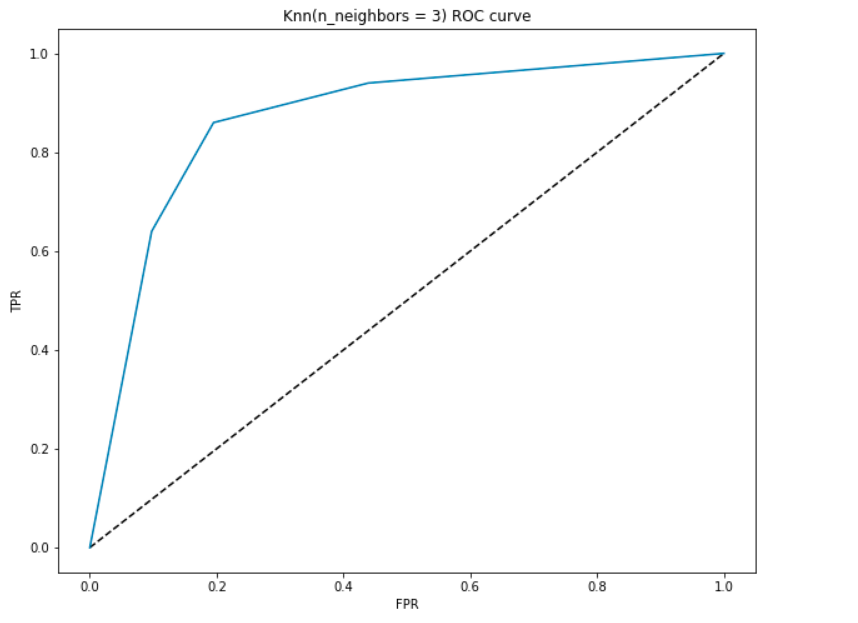
AUC Interpretation-
- Am tiefsten Punkt, d.h. bei (0, 0)- der Schwellenwert wird auf 1,0 gesetzt. Dies bedeutet, dass unser Modell alle Patienten als nicht mit einer Herzerkrankung klassifiziert.
- Am höchsten Punkt, d.h. bei (1, 1), wird der Schwellenwert auf 0,0 gesetzt., Dies bedeutet, dass unser Modell alle Patienten als Herzerkrankungen klassifiziert.
- Der Rest der Kurve sind die Werte von FPR und TPR für die Schwellenwerte zwischen 0 und 1. Bei einem bestimmten Schwellenwert beobachten wir, dass wir für FPR nahe 0 einen TPR von nahe 1 erreichen. Dies ist, wenn das Modell die Patienten mit Herzerkrankungen fast perfekt vorhersagen wird.
- Die Fläche mit der Kurve und den Achsen als Grenzen wird als Fläche unter Kurve(AUC) bezeichnet. Es ist dieser Bereich, der als Metrik eines guten Modells betrachtet wird., Mit dieser Metrik von 0 bis 1 sollten wir einen hohen AUC-Wert anstreben. Modelle mit einer hohen AUC werden als Modelle mit guten Fähigkeiten bezeichnet. Lassen Sie uns den AUC-Score unseres Modells und das obige Diagramm berechnen:

- Wir erhalten einen Wert von 0.868 als AUC, was eine ziemlich gute Punktzahl ist! Das bedeutet im Klartext, dass das Modell die Patienten mit Herzerkrankungen unterscheiden kann und diejenigen, die es nicht tun 87% der Zeit. Wir können diese Punktzahl verbessern und ich fordere Sie auf, verschiedene Hyperparameterwerte auszuprobieren.,
- Die diagonale Linie ist ein Zufallsmodell mit einer AUC von 0,5, ein Modell ohne Fertigkeit, was genauso ist wie eine zufällige Vorhersage. Können Sie erraten, warum?
Precision-Recall-Kurve (PRC)
Wie der name schon sagt, ist diese Kurve ist eine direkte Darstellung der Präzision(y-Achse) und recall(x-Achse). Wenn Sie unsere Definitionen und Formeln für die Präzision und den Rückruf oben beachten, werden Sie feststellen, dass wir zu keinem Zeitpunkt die wahren Negative verwenden(die tatsächliche Anzahl von Menschen, die keine Herzkrankheit haben).,
Dies ist besonders nützlich für Situationen, in denen wir einen unausgeglichenen Datensatz haben und die Anzahl der Negativen viel größer ist als die Positiven(oder wenn die Anzahl der Patienten, die keine Herzerkrankung haben, viel größer ist als die Patienten, die sie haben). In solchen Fällen wäre es unser größeres Anliegen, die Patienten mit Herzerkrankungen so korrekt wie möglich zu erkennen und die TNR nicht zu benötigen.
Wie der ROC zeichnen wir die Genauigkeit und den Rückruf für verschiedene Schwellenwerte auf:
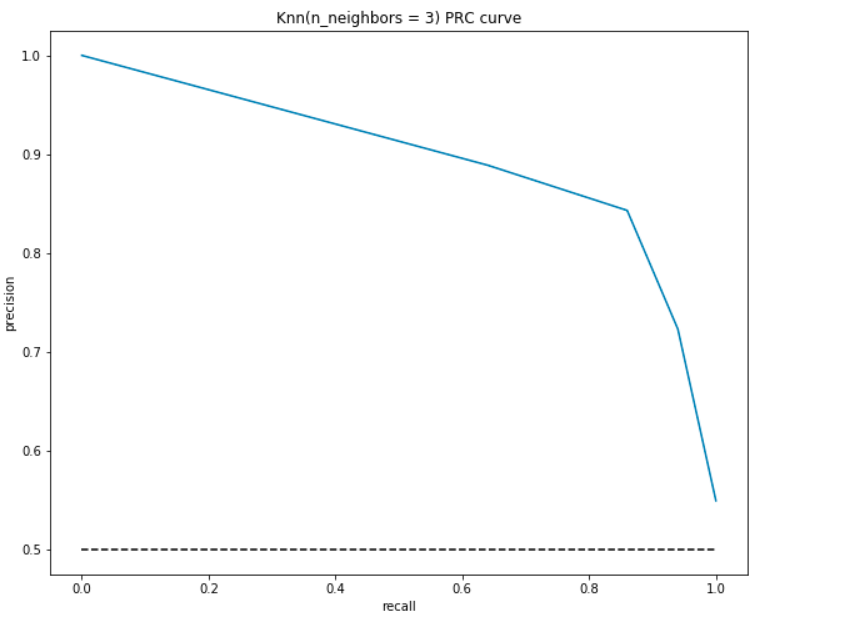
PRC Interpretation:
- Am tiefsten Punkt, d.h., at (0, 0)- Der Schwellenwert ist auf 1,0 eingestellt. Dies bedeutet, dass unser Modell keine Unterschiede zwischen den Patienten mit Herzerkrankungen und den Patienten ohne Herzerkrankungen macht.
- Am höchsten Punkt, dh bei (1, 1), ist der Schwellenwert auf 0.0 gesetzt. Dies bedeutet, dass sowohl unsere Präzision als auch der Rückruf hoch sind und das Modell perfekt unterscheidet.
- Der Rest der Kurve sind die Werte Genauigkeit und Genauigkeit für die Schwellenwerte zwischen 0 und 1. Unser Ziel ist es, die Kurve so nah wie möglich an (1, 1) zu machen – was eine gute Präzision und Rückruf bedeutet.,
- Ähnlich wie bei ROC ist die Fläche mit der Kurve und den Achsen als Grenzen die Fläche unter der Kurve(AUC). Betrachten Sie diesen Bereich als Metrik eines guten Modells. Die AUC reicht von 0 bis 1. Daher sollten wir einen hohen Wert der AUC anstreben. Berechnen wir die AUC für unser Modell und das obige Diagramm:

Nach wie vor erhalten wir eine gute AUC von rund 90%. Außerdem kann das Modell mit Rückruf als 0 eine hohe Präzision erreichen und würde einen hohen Rückruf erreichen, indem die Präzision von 50% beeinträchtigt wird.,
Endnoten
Abschließend haben wir in diesem Artikel gesehen, wie ein Klassifikationsmodell bewertet wird, das sich insbesondere auf Präzision und Rückruf konzentriert, und ein Gleichgewicht zwischen ihnen findet. Außerdem erklären wir, wie Sie unsere Modellleistung mithilfe verschiedener Metriken und einer Verwirrungsmatrix darstellen.
Hier ist ein zusätzlicher Artikel, in dem Sie Bewertungsmetriken verstehen können-11 Wichtige Modellbewertungsmetriken für maschinelles Lernen, die jeder kennen sollte