Descrição
- Precisão e recall são duas crucial ainda mal tópicos em aprendizagem de máquina
- vamos discutir o que precisão e recall são, como funcionam, e o seu papel na avaliação de uma máquina modelo de aprendizagem
- que também vai ganhar uma compreensão de que a Área Sob a Curva (AUC) e Precisão de termos
Introdução
Pergunte a qualquer máquina de aprendizagem profissional ou cientista de dados sobre os mais confuso conceitos em sua jornada de aprendizado., E invariavelmente, a resposta vai em direcção à precisão e à recolha.
a diferença entre precisão e memória é realmente fácil de lembrar – mas só quando você realmente entendeu o que cada termo representa. Mas muitas vezes, e posso atestá-lo, os especialistas tendem a oferecer explicações mal cozinhadas que confundem ainda mais os recém-chegados.vamos esclarecer as coisas neste artigo.

para qualquer modelo de aprendizagem por máquina, sabemos que alcançar um “bom ajuste” no modelo é extremamente crucial., Isto envolve alcançar o equilíbrio entre subfitting e overfitting, ou em outras palavras, um tradeoff entre viés e variância.
no entanto, quando se trata de classificação – há um outro tradeoff que é muitas vezes negligenciado em favor do tradeoff de bias-variância. Este é o Acordo de recolha de precisão. Classes desequilibradas ocorrem comumente em conjuntos de dados e quando se trata de casos específicos de uso, gostaríamos de dar mais importância à precisão e recolha métricas, e também como alcançar o equilíbrio entre eles.mas como fazê-lo?, Vamos explorar as métricas de avaliação da classificação, focando-se na precisão e recall neste artigo. Também aprenderemos a calcular estas métricas em Python, tomando um conjunto de dados e um algoritmo de classificação simples. Então, vamos começar!
Você pode aprender sobre métricas de avaliação em profundidade aqui-métricas de Avaliação para modelos de aprendizagem de máquinas.
Índice
- compreensão da declaração do problema
- O que é Precisão?o que é a chamada?,
- mais Fáceis de Avaliação Métrica – Precisão
- O Papel da F1-Score
- O Famoso Precision-Recall Troca
- a Compreensão da Área Sob a Curva (AUC)
a Compreensão do Problema Instrução
eu acredito fortemente que se aprende fazendo. Por isso, ao longo deste artigo, vamos falar em termos práticos-usando um conjunto de dados.
vamos pegar o popular Conjunto de dados sobre doenças cardíacas disponível no repositório UCI. Aqui, temos que prever se o paciente está sofrendo de uma doença cardíaca ou não usando o conjunto de características dadas., Você pode baixar o conjunto de dados limpos a partir daqui.
Uma vez que este artigo se concentra apenas em métricas de avaliação de modelos, vamos usar o classificador mais simples – o modelo de classificação kNN para fazer previsões.
Como sempre, vamos começar por importar as bibliotecas necessárias e pacotes:
em Seguida, vamos dar uma olhada nos dados e as variáveis de segmentação, estamos lidando com o:
Vamos verificar se temos valores em falta:
não Existem valores em falta., Agora podemos dar uma olhada em como muitas pacientes são, na verdade, sofrem de doença cardíaca (1) e quantas não são (0):
Esta é a contagem de lote abaixo:
Vamos continuar dividindo a nossa formação e dados de teste e a nossa entrada e variáveis de destino. Uma vez que estamos a usar o KNN, é obrigatório escalar também os nossos conjuntos de dados:
a intuição por trás da escolha do melhor valor de k está fora do âmbito deste artigo, mas devemos saber que podemos determinar o valor óptimo de k quando tivermos a pontuação de teste mais elevada para esse valor., Para isso, podemos avaliar a formação e testes de pontuação de até 20 vizinhos mais próximos:
Para avaliar o máximo de pontuação do teste e os valores de k associado a isso, execute o seguinte comando:

Assim, temos obtido o melhor valor de k a 3, 11, ou 20, com uma pontuação de 83.5. Vamos finalizar um destes valores e encaixar o modelo de acordo com:

Agora, como avaliamos se este modelo é um modelo ‘bom’ ou não?, Para isso, usamos algo chamado de matriz de confusão:
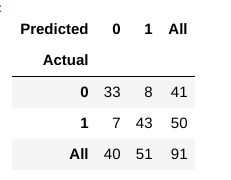
uma matriz de confusão ajuda-nos a obter uma visão de como eram corretas as nossas previsões e como elas se sustentam contra os valores reais.a partir dos dados do nosso comboio e do nosso teste, já sabemos que os nossos dados de teste consistiam em 91 pontos de dados. Este é o valor da terceira linha e da terceira coluna no final. Notamos também que existem alguns valores reais e previstos. Os valores reais são o número de pontos de dados que foram originalmente categorizados em 0 ou 1., Os valores previstos são o número de pontos de dados que o nosso modelo KNN previu como 0 ou 1.
Os valores reais são:
- Os pacientes que não tem uma doença cardíaca = 41
- Os pacientes que realmente têm uma doença cardíaca = 50
Os valores previstos são:
- o Número de pacientes que estavam previstas como não ter uma doença do coração = 40
- o Número de pacientes que foram previstos como tendo uma doença de coração = 51
Todos os valores obtemos acima tem um prazo., Vamos revê-los um por um:
- os casos em que os pacientes realmente não tinham doença cardíaca e nosso modelo também previu que não tê-lo é chamado de os verdadeiros negativos. Para a nossa matriz, verdadeiros negativos = 33.
- os casos em que os pacientes realmente têm doença cardíaca e nosso modelo também previu como tendo isso são chamados os verdadeiros positivos. Para nossa matriz, verdadeiros positivos = 43
- No entanto, há alguns casos em que o paciente realmente não tem doença cardíaca, mas nosso modelo previu que eles têm., Este tipo de erro é o tipo I erro e chamamos os valores de falsos positivos. Para nossa matriz, falsos positivos = 8
- similarmente, existem alguns casos em que o paciente realmente tem doença cardíaca, mas nosso modelo previu que ele/ela não tem. este tipo de erro é o erro de tipo II e chamamos os valores de falsos negativos. Para nossa matriz, falsos negativos = 7
O que é Precisão?
Right-so now we come to the crux of this article. O que é a precisão? E o que todo o aprendizado acima tem a ver com isso?,
em termos mais simples, precisão é a razão entre os positivos verdadeiros e todos os positivos. Para a nossa Declaração de problemas, essa seria a medida dos pacientes que identificamos corretamente ter uma doença cardíaca de todos os pacientes que realmente a têm. Matematicamente:

Qual é a precisão para o nosso modelo? Sim, é 0,843 ou, quando prediz que um paciente tem uma doença cardíaca, é correto em torno de 84% das vezes.a precisão também nos dá uma medida dos pontos de dados relevantes., É importante que não comecemos a tratar um paciente que na verdade não tem uma doença cardíaca, mas o nosso modelo previu que a tivesse.
What is Recall?
the recall is the measure of our model correctly identifying True Positives. Assim, para todos os pacientes que realmente têm doença cardíaca, recall nos diz quantos nós corretamente identificamos como tendo uma doença cardíaca. Matematicamente:

para o nosso modelo, Recall = 0,86. Recall também dá uma medida de como o nosso modelo é capaz de identificar com precisão os dados relevantes., Referimo-nos a ele como Sensibilidade ou verdadeira taxa positiva. E se um paciente tem uma doença cardíaca, mas não há tratamento dado a ele porque o nosso modelo previu isso? Esta é uma situação que gostaríamos de evitar!
a métrica mais fácil de entender – precisão
agora chegamos a uma das métricas mais simples de todas, a precisão. Precisão é a relação entre o número total de previsões corretas e o número total de previsões. Pode adivinhar qual será a fórmula para a precisão?
![]()
para o nosso modelo, a precisão será = 0,835.,
usar precisão como uma métrica definidora para o nosso modelo faz sentido intuitivamente, mas mais frequentemente do que não, é sempre aconselhável usar precisão e recordar também. Pode haver outras situações em que a nossa precisão é muito alta, mas a nossa precisão ou memória é baixa. Idealmente, para o nosso modelo, gostaríamos de evitar completamente quaisquer situações em que o paciente tem uma doença cardíaca, mas o nosso modelo classifica-o como não tendo-o, isto é, como um objectivo de alta recall.,por outro lado, para os casos em que o paciente não sofre de doença cardíaca e o nosso modelo prevê o contrário, também gostaríamos de evitar tratar um paciente sem doenças cardíacas(cruciais quando os parâmetros de entrada podem indicar uma doença diferente, mas acabamos por tratá-lo por uma doença cardíaca).
apesar de visarmos alta precisão e alto valor de recall, alcançar ambos ao mesmo tempo não é possível., Por exemplo, se mudarmos o modelo para um que nos dê um alto recall, podemos detectar todos os pacientes que realmente têm doença cardíaca, mas podemos acabar dando Tratamentos para muitos pacientes que não sofrem disso.
da mesma forma, se pretendemos alta precisão para evitar dar qualquer tratamento errado e não solicitado, acabamos recebendo um monte de pacientes que realmente têm uma doença cardíaca indo sem qualquer tratamento.
the Role of the F1-Score
Understanding Accuracy made us realize, we need a tradeoff between Precision and Recall., Em primeiro lugar, temos de decidir o que é mais importante para o nosso problema de classificação.
Por exemplo, para o nosso conjunto de dados, podemos considerar que alcançar uma recolha elevada é mais importante do que obter uma alta precisão – gostaríamos de detectar o maior número possível de doentes cardíacos. Para alguns outros modelos, como classificar se um cliente do banco é de um empréstimo inadimplente ou não, é desejável ter uma alta precisão, pois o banco não gostaria de perder os clientes a quem foi negado um empréstimo com base no modelo de previsão que eles estariam inadimplentes.,existem também muitas situações em que a precisão e a recolha são igualmente importantes. Por exemplo, para o nosso modelo, se o médico informa-nos que os pacientes que foram incorretamente classificadas como sofrendo da doença do coração, são igualmente importantes, pois eles podem ser indicativas de alguma outra doença, então nós teria como objetivo não somente um alto recall, mas uma alta precisão bem.em tais casos, usamos algo chamado pontuação F1., F1-resultado é a média Harmónica da Precisão e Lembre-se:

Este é mais fácil de trabalhar desde agora, em vez de balanceamento de precisão e recall, podemos apenas apontar para uma boa F1-score e o que seria indicativo de uma boa Precisão e uma boa Recordação valor do bem.,
o que pode gerar acima de métricas para o nosso conjunto de dados usando sklearn também:
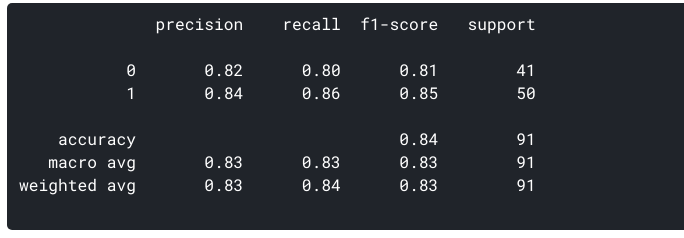
Curva ROC
Juntamente com os termos acima, existem mais valores podemos calcular a partir da matriz de confusão:
- Taxa de Falsos Positivos (FPR): Ele é a taxa de Falsos Positivos para o número Real de Negativos. No contexto do nosso modelo, é uma medida para quantos casos o modelo prevê que o paciente tem uma doença cardíaca de todos os pacientes que realmente não têm a doença cardíaca. Para os nossos dados, o FPR é = 0.,195
- taxa negativa verdadeira (TNR) ou especificidade: é a razão dos negativos verdadeiros e o número real de negativos. Para o nosso modelo, é a medida para quantos casos o modelo previu corretamente que o paciente não tem doença cardíaca de todos os pacientes que realmente não têm doença cardíaca. O TNR para os dados acima referidos = 0, 804. A partir destas 2 Definições, podemos também concluir que especificidade ou TNR = 1 – FPR
também podemos visualizar precisão e Recall usando curvas ROC e RPC.,
curvas ROC (curva característica de funcionamento do receptor):
é o gráfico entre o eixo TPR(eixo y) e FPR(eixo x). Uma vez que nosso modelo classifica o paciente como tendo doença cardíaca ou não com base nas probabilidades geradas para cada classe, podemos decidir o limiar das probabilidades também.
Por exemplo, queremos definir um valor limiar de 0,4. Isto significa que o modelo classificará o datapoint/paciente como tendo doença cardíaca se a probabilidade do paciente ter uma doença cardíaca for superior a 0,4., Isto dará obviamente um alto valor de recall e reduzirá o número de falsos positivos. Da mesma forma, podemos visualizar como nosso modelo funciona para diferentes valores limiar usando a curva ROC.
vamos gerar uma curva ROC para o nosso modelo com k = 3.
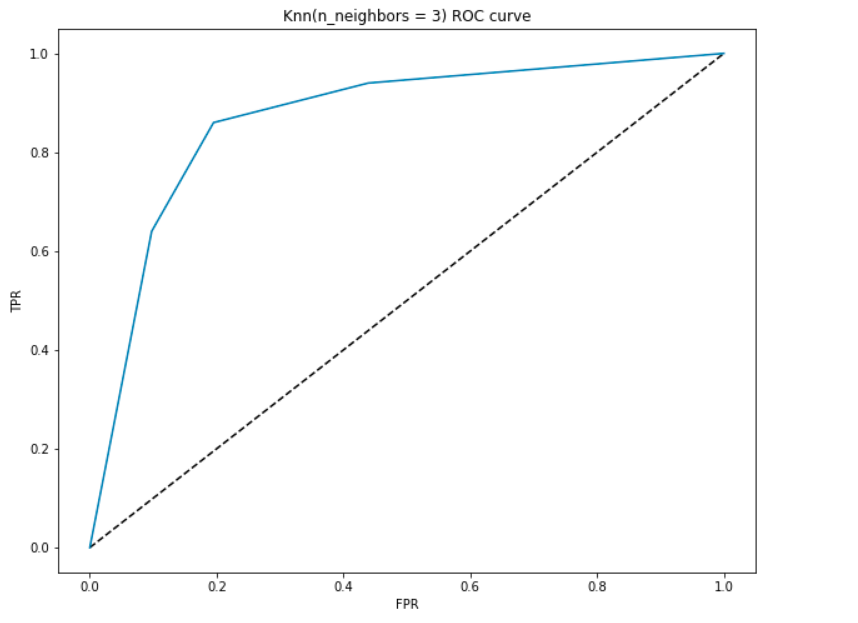
interpretação da AUC-
- no ponto mais baixo, ou seja, em (0, 0)- o limiar é fixado em 1, 0. Isso significa que nosso modelo classifica todos os pacientes como não tendo uma doença cardíaca.
- no ponto mais alto ou seja em (1, 1), o limiar é fixado em 0.0., Isto significa que o nosso modelo classifica todos os pacientes como tendo uma doença cardíaca.
- o resto da curva são os valores de FPR e TPR para os valores-limite entre 0 e 1. Em algum valor limiar, observamos que para FPR próximo de 0, estamos alcançando um TPR próximo de 1. Este é o momento em que o modelo irá prever os pacientes com doença cardíaca quase perfeitamente.
- a área com a curva e os eixos como os limites são chamados de área sob a curva(AUC). É esta área que é considerada uma métrica de um bom modelo., Com esta métrica variando de 0 a 1, devemos apontar para um alto valor de AUC. Modelos com uma alta AUC são chamados como modelos com boa habilidade. Vamos calcular a AUC pontuação de nosso modelo e acima enredo:

- Podemos obter um valor de 0.868 como a AUC que é uma boa pontuação! Em termos mais simples, isso significa que o modelo será capaz de distinguir os pacientes com doença cardíaca e aqueles que não têm 87% das vezes. Podemos melhorar esta pontuação e peço-lhe que Tente diferentes valores de hiperparametro.,
- A linha diagonal é um modelo aleatório com uma AUC de 0,5, um modelo sem habilidade, que é o mesmo que fazer uma previsão aleatória. Consegues adivinhar porquê?
curva de recolha de precisão (RPC)
como o nome sugere, esta curva é uma representação directa da precisão(eixo y) e da recolha(eixo x). Se você observar as nossas definições e fórmulas para a Precisão e o Recall acima, você vai notar que em nenhum momento estamos usando os Verdadeiros Negativos(o número real de pessoas que não têm doença cardíaca).,
isto é particularmente útil para as situações em que temos um conjunto de dados desequilibrado e o número de negativos é muito maior do que os positivos(ou quando o número de pacientes sem doença cardíaca é muito maior do que os pacientes que têm). Em tais casos, nossa maior preocupação seria detectar os pacientes com doença cardíaca tão corretamente quanto possível e não precisaria do TNR.
Como o ROC, marcamos a precisão e o recall para diferentes valores de limiar:
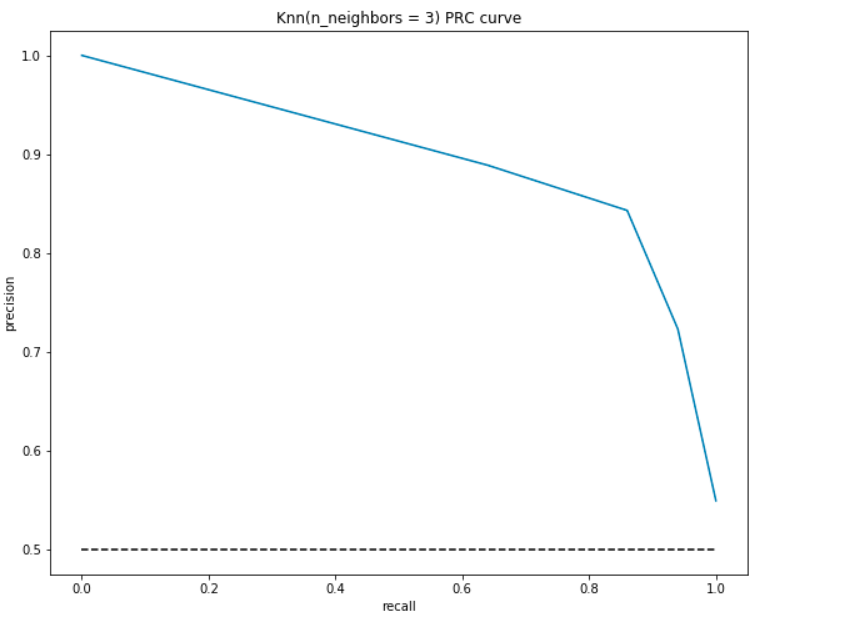
PRC Interpretação:
- No ponto mais baixo, i.e., at (0, 0)- o limiar é fixado em 1,0. Isto significa que o nosso modelo não faz distinções entre os pacientes que têm doença cardíaca e os pacientes que não têm.
- no ponto mais alto, ou seja, em (1, 1), o limiar é fixado em 0, 0. Isto significa que tanto a nossa precisão como a nossa recolha são elevadas e o modelo faz distinções perfeitamente.
- o resto da curva são os valores de precisão e de recolha para os valores-limite entre 0 e 1. Nosso objetivo é fazer a curva o mais próximo possível de (1, 1) – o que significa uma boa precisão e recolha.,
- semelhante à ROC, A área com a curva e os eixos como os limites é a área sob a curva(AUC). Considere esta área como uma métrica de um bom modelo. A AUC varia entre 0 e 1. Por conseguinte, devemos procurar obter um elevado valor da AUC. Vamos calcular a AUC para o nosso modelo, e acima enredo:

Como antes, obtemos um bom AUC em cerca de 90%. Além disso, o modelo pode alcançar alta precisão com a recolha como 0 e obteria uma recolha elevada comprometendo a precisão de 50%.,
notas finais
para concluir, neste artigo, vimos como avaliar um modelo de classificação, especialmente focando na precisão e na recolha, e encontrar um equilíbrio entre eles. Além disso, explicamos como representar nosso desempenho modelo usando métricas diferentes e uma matriz de confusão.
Aqui está um artigo adicional para você entender métricas de avaliação – 11 métricas de Avaliação de modelos importantes para a aprendizagem de máquinas Todos Devem Saber