Prezentare generală
- precizia și rechemarea sunt două subiecte cruciale, dar neînțelese, în învățarea automată
- vom discuta ce precizie și rechemare sunt, cum funcționează și rolul lor în evaluarea unui model de învățare automată
- vom înțelege, de asemenea, zona de sub curba (AUC) și Termenii de precizie
om de știință despre conceptele cele mai confuze în călătoria lor de învățare., Și invariabil, răspunsul se îndreaptă spre precizie și rechemare.
diferența dintre precizie și rechemare este de fapt ușor de reținut – dar numai după ce ați înțeles cu adevărat ce înseamnă fiecare termen. Dar destul de des, și pot atesta acest lucru, experții tind să ofere explicații pe jumătate coapte, care confundă și mai mult noii veniți.
deci, să stabilim înregistrarea direct în acest articol.

pentru orice model de învățare automată, știm că realizarea unei „potriviri bune” pe model este extrem de crucială., Acest lucru implică realizarea echilibrului între subfitting și overfitting, sau cu alte cuvinte, un compromis între părtinire și varianță.
cu toate acestea, atunci când vine vorba de clasificare – există un alt compromis care este adesea trecut cu vederea în favoarea compromisului de variație. Aceasta este tradeoff precizie-rechemare. Clasele dezechilibrate apar frecvent în seturile de date și atunci când vine vorba de cazuri specifice de utilizare, am dori, de fapt, să acordăm mai multă importanță măsurătorilor de precizie și rechemare și, de asemenea, cum să realizăm echilibrul dintre ele.
dar, cum se face acest lucru?, Vom explora valorile de evaluare a clasificării, concentrându-ne pe precizie și rechemare în acest articol. De asemenea, vom învăța cum să calculăm aceste valori în Python, luând un set de date și un algoritm simplu de clasificare. Deci, să începem!
puteți afla mai multe despre valorile de evaluare în profunzime aici-valori de evaluare pentru modelele de învățare automată.
cuprins
- înțelegerea enunțului problemei
- ce este precizia?
- ce este rechemarea?,
- Cel mai Simplu de Evaluare Metric Precizie
- Rolul F1-Scor
- Celebrul Precision-Recall Compromisul
- Înțelegerea ariei de Sub Curbă (ASC)
Înțelegerea Problemei Declarație
cred cu tărie în procesul de învățare prin practică. Deci, pe parcursul acestui articol, vom vorbi în termeni practici-folosind un set de date.
să preluăm setul popular de date privind bolile de inimă Disponibil în depozitul UCI. Aici, trebuie să prezicem dacă pacientul suferă de o boală de inimă sau nu utilizează setul dat de caracteristici., Puteți descărca setul de date curate de aici.deoarece acest articol se concentrează exclusiv pe valorile de evaluare a modelului, vom folosi cel mai simplu clasificator – modelul de clasificare kNN pentru a face predicții.
Ca de obicei, vom începe prin importul de bibliotecile necesare și pachete:
Apoi să ne ia o privire la datele și variabilele-țintă avem de-a face cu:
Sa ne verifice daca avem lipsa de valori:
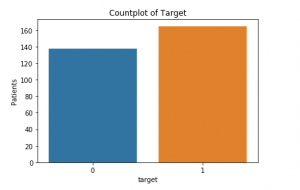
nu Există valori lipsă., Acum putem arunca o privire la câți pacienți suferă de boli de inimă (1) și câți nu sunt (0):
acesta este graficul de mai jos:
să procedăm prin împărțirea datelor noastre de instruire și testare și a variabilelor noastre de intrare și țintă. Deoarece folosim KNN, este obligatoriu să ne scalăm și seturile de date:
intuiția din spatele alegerii celei mai bune valori a lui k depășește domeniul de aplicare al acestui articol, dar ar trebui să știm că putem determina valoarea optimă a lui k atunci când obținem cel mai mare scor de test pentru acea valoare., Pentru asta, putem evalua instruire și testare scoruri de până la 20 de cel mai apropiat vecini:
Pentru a evalua max scor la test și cele k valori asociate cu aceasta, executați următoarea comandă:

Astfel, am obținut valoarea optimă a k să fie de 3, 11, sau 20, cu un scor de 83.5. Vom finaliza una dintre aceste valori și vom potrivi modelul în consecință:

acum, cum evaluăm dacă acest model este un model ” bun ” sau nu?, Pentru asta, am folosit ceva numit o Confuzie Matrix:
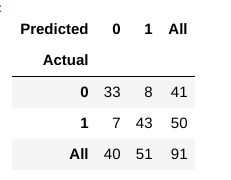
O confuzie matrix ne ajută pentru a obține o introspecție în modul corect previziunile noastre au fost și modul în care acestea rezista împotriva valori reale.din datele noastre de tren și de testare, știm deja că datele noastre de testare au constat din 91 de puncte de date. Acesta este al 3-lea rând și valoarea coloanei A 3-A la sfârșit. De asemenea, observăm că există unele valori reale și prezise. Valorile reale sunt numărul de puncte de date care au fost clasificate inițial în 0 sau 1., Valorile estimate sunt numărul de puncte de date pe care modelul nostru KNN le-a prezis ca 0 sau 1.
valorile reale sunt:
- La pacienții care de fapt nu au o boală de inimă = 41
- La pacienții care de fapt nu au o boală de inimă = 50
valorile prezise sunt:
- Numărul de pacienți care au fost prezise ca nu avea o boală de inimă = 40
- Numărul de pacienți care au prezis ca având o boală de inimă = 51
Toate valorile pe care le obține de mai sus au un termen., Să trecem peste ele unul câte unul:
- cazurile în care pacienții nu au avut de fapt boli de inimă și modelul nostru a prezis, de asemenea, că nu o are se numește adevăratele negative. Pentru matricea noastră, adevăratele negative = 33.
- cazurile în care pacienții au de fapt boli de inimă și modelul nostru, de asemenea, a prezis ca având-o sunt numite pozitive reale. Pentru matricea noastră, adevărate pozitive = 43
- Cu toate acestea, există unele cazuri în care pacientul nu are de fapt nici o boală de inimă, dar modelul nostru a prezis că o fac., Acest tip de eroare este eroarea de tip I și numim valorile ca fals pozitive. Pentru matricea noastră, Alarme False = 8
- în mod Similar, există unele cazuri în care pacientul are, de fapt, boli de inima, dar modelul nostru a prezis că el/ea nu. Acest tip de eroare este o Eroare de Tipul II si numim valori Fals Negative. Pentru matricea noastră, fals negative = 7
ce este precizia?
dreapta-așa că acum ajungem la punctul crucial al acestui articol. Ceea ce în lume este de precizie? Și ce are de-a face cu toate învățarea de mai sus?,
în termeni simpli, precizia este raportul dintre adevăratele pozitive și toate pozitive. Pentru afirmația noastră despre probleme, aceasta ar fi măsura pacienților pe care îi identificăm corect având o boală de inimă dintre toți pacienții care o au de fapt. Matematic:

care este precizia pentru modelul nostru? Da, este 0, 843 sau, atunci când prezice că un pacient are boli de inimă, este corect în jur de 84% din timp.
precizia ne oferă, de asemenea, o măsură a punctelor de date relevante., Este important să nu începem să tratăm un pacient care de fapt nu are o boală de inimă, dar modelul nostru a prezis că o are.
ce este rechemarea?
rechemarea este măsura modelului nostru care identifică corect adevăratele pozitive. Astfel, pentru toți pacienții care au de fapt boli de inimă, rechemarea ne spune câți am identificat corect ca având o boală de inimă. Matematic:

pentru modelul nostru, rechemare = 0.86. Rechemarea oferă, de asemenea, o măsură a cât de precis modelul nostru este capabil să identifice datele relevante., Ne referim la aceasta ca sensibilitate sau rată pozitivă reală. Ce se întâmplă dacă un pacient are boli de inimă, dar nu i se administrează niciun tratament, deoarece modelul nostru a prezis acest lucru? Aceasta este o situație pe care am dori să o evităm!
cea mai ușoară metrică de înțeles – precizie
acum ajungem la una dintre cele mai simple valori ale tuturor, precizie. Precizia este raportul dintre numărul total de predicții corecte și numărul total de predicții. Puteți ghici care va fi formula de precizie?
![]()
pentru modelul nostru, Precizia va fi = 0.835.,
utilizarea preciziei ca metrică definitorie pentru modelul nostru are sens intuitiv, dar, de cele mai multe ori, este întotdeauna recomandabil să folosiți precizia și să vă amintiți. Pot exista și alte situații în care precizia noastră este foarte mare, dar precizia sau rechemarea noastră este scăzută. În mod ideal, pentru modelul nostru, am dori să evităm complet orice situație în care pacientul are boli de inimă, dar modelul nostru se clasifică drept el care nu o are, adică vizează o rechemare ridicată.,pe de altă parte, pentru cazurile în care pacientul nu suferă de boli de inimă și modelul nostru prezice contrariul, am dori, de asemenea, să evităm tratarea unui pacient fără boli de inimă(crucial atunci când parametrii de intrare ar putea indica o afecțiune diferită, dar ajungem să-l tratăm pentru o afecțiune cardiacă).
deși urmărim o precizie ridicată și o valoare ridicată de rechemare, realizarea ambelor în același timp nu este posibilă., De exemplu, dacă schimbăm modelul cu unul care ne dă o rechemare mare, am putea detecta toți pacienții care au de fapt boli de inimă, dar am putea ajunge să oferim tratamente multor pacienți care nu suferă de ea.în mod similar ,dacă ne propunem o precizie ridicată pentru a evita orice tratament greșit și neimplicat, ajungem să obținem o mulțime de pacienți care au de fapt o boală de inimă fără tratament.
rolul scorului F1
înțelegerea preciziei ne-a făcut să realizăm că avem nevoie de un compromis între precizie și rechemare., Mai întâi trebuie să decidem care este mai important pentru problema noastră de clasificare.de exemplu ,pentru setul nostru de date, putem considera că obținerea unui recall ridicat este mai importantă decât obținerea unei precizii înalte – am dori să detectăm cât mai mulți pacienți cu inimă posibil. Pentru alte modele, cum ar fi clasificarea dacă un client bancar este un debitor de împrumut sau nu, este de dorit să aibă o precizie ridicată, deoarece banca nu ar dori să piardă clienții cărora li s-a refuzat un împrumut pe baza predicției modelului că ar fi debitori.,există ,de asemenea, o mulțime de situații în care atât precizia, cât și rechemarea sunt la fel de importante. De exemplu, pentru modelul nostru, dacă medicul ne informează că pacienții care au fost clasificați incorect ca suferind de boli de inimă sunt la fel de importanți, deoarece ar putea indica o altă afecțiune, atunci am urmări nu numai o rechemare ridicată, ci și o precizie ridicată.în astfel de cazuri, folosim ceva numit scor F1., F1-scorul este medie Armonică a Preciziei și Amintiți-vă:

Acest lucru este mai ușor de a lucra cu, deoarece acum, în loc de echilibrare de precizie și de rechemare, putem doar să urmărească o bună F1-scor și că ar fi un indiciu de o Precizie bună și un bun Reamintim valoare la fel de bine.,
putem genera mai sus valorile pentru setul nostru de date, folosind sklearn prea:
Curba ROC
de-a Lungul cu termenii de mai sus, există mai multe valori putem calcula din matricea confuzie:
- Rata de Fals Pozitive (FPR): Acesta este raportul de Alarme False la numărul Real de Negative. În contextul modelului nostru, este o măsură pentru câte cazuri a prezis modelul că pacientul are o boală de inimă de la toți pacienții care de fapt nu au avut boala de inimă. Pentru datele noastre, FPR este = 0.,195
- True negative Rate (TNR) sau specificitatea: este raportul dintre adevăratele negative și numărul real de negative. Pentru modelul nostru, este măsura pentru câte cazuri a prezis corect modelul că pacientul nu are boli de inimă de la toți pacienții care de fapt nu au avut boli de inimă. TNR pentru datele de mai sus = 0,804. Din aceste 2 Definiții, putem concluziona, de asemenea, că specificitatea sau TNR = 1 – FPR
putem vizualiza, de asemenea, precizia și rechemarea folosind curbele ROC și curbele PRC.,
curbele ROC (curba caracteristică de operare a receptorului):
este graficul dintre TPR(axa y) și FPR(axa x). Deoarece modelul nostru clasifică pacientul ca având boli de inimă sau nu pe baza probabilităților generate pentru fiecare clasă, putem decide și pragul probabilităților.
de exemplu, dorim să setăm o valoare de prag de 0,4. Aceasta înseamnă că modelul va clasifica punctul de date / pacientul ca având boli de inimă dacă probabilitatea ca pacientul să aibă o boală de inimă este mai mare de 0,4., Acest lucru va da în mod evident o valoare ridicată de rechemare și va reduce numărul de fals pozitive. În mod similar, putem vizualiza modul în care modelul nostru funcționează pentru diferite valori de prag folosind curba ROC.
să generăm o curbă ROC pentru modelul nostru cu k = 3.
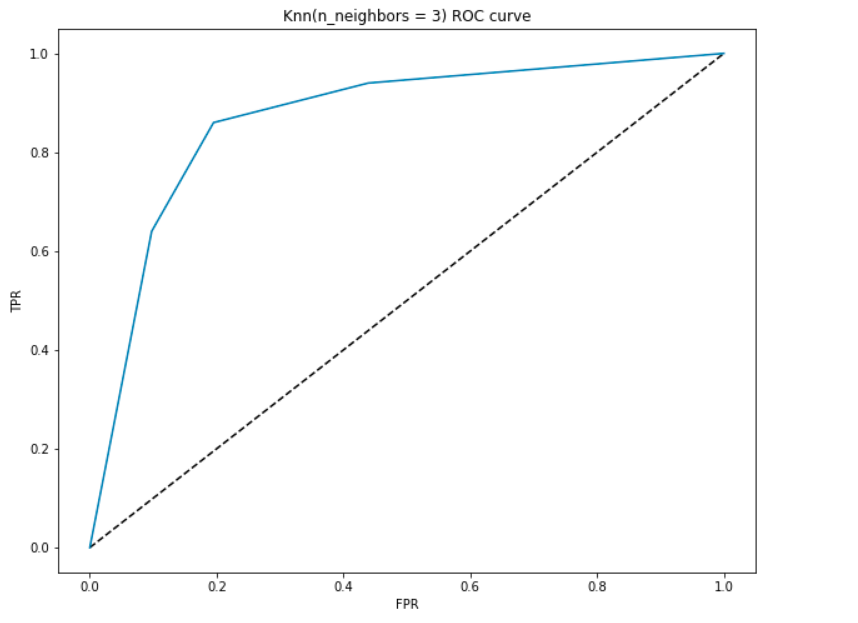
interpretarea ASC-
- la punctul cel mai de jos, adică la (0, 0)- pragul este stabilit la 1.0. Acest lucru înseamnă că modelul nostru clasifică toți pacienții ca nu au o boală de inimă.
- la cel mai înalt punct, adică la (1, 1), pragul este stabilit la 0, 0., Aceasta înseamnă că modelul nostru clasifică toți pacienții ca având o boală de inimă.
- restul curbei este valorile FPR și TPR pentru valorile de prag între 0 și 1. La o anumită valoare de prag, observăm că pentru FPR aproape de 0, obținem un TPR aproape de 1. Acest lucru este atunci când modelul va prezice pacienții care au boli de inima aproape perfect.
- zona cu curba și axele ca limitele se numește zona sub curba (ASC). Această zonă este considerată o metrică a unui model bun., Cu această valoare cuprinsă între 0 și 1, ar trebui să vizăm o valoare ridicată a ASC. Modelele cu o ASC ridicată sunt numite modele cu o bună abilitate. Să calculăm scorul AUC al modelului nostru și graficul de mai sus:

- obținem o valoare de 0.868 ca ASC, care este un scor destul de bun! În termeni simpli, acest lucru înseamnă că modelul va fi capabil să distingă pacienții cu boli de inimă și cei care nu 87% din timp. Putem îmbunătăți acest scor și vă îndemn să încercați diferite valori ale hiperparametrului.,
- linia diagonală este un model aleator cu o ASC de 0,5, un model fără abilitate, care la fel ca și a face o predicție aleatorie. Poți ghici de ce?după cum sugerează și numele, această curbă este o reprezentare directă a preciziei(axa y) și a rechemării(axa x). Dacă respectați definițiile și formulele noastre pentru precizia și reamintirea de mai sus, veți observa că în niciun moment nu folosim adevăratele negative(numărul real de persoane care nu au boli de inimă).,acest lucru este util în special pentru situațiile în care avem un set de date dezechilibrat și numărul de negative este mult mai mare decât pozitive(sau atunci când numărul de pacienți care nu au boli de inima este mult mai mare decât pacienții care au). În astfel de cazuri, preocuparea noastră mai mare ar fi detectarea pacienților cu boli de inimă cât mai corect posibil și nu ar avea nevoie de TNR.
Ca ROC, am complot precizia și recall pentru diferite valori prag:
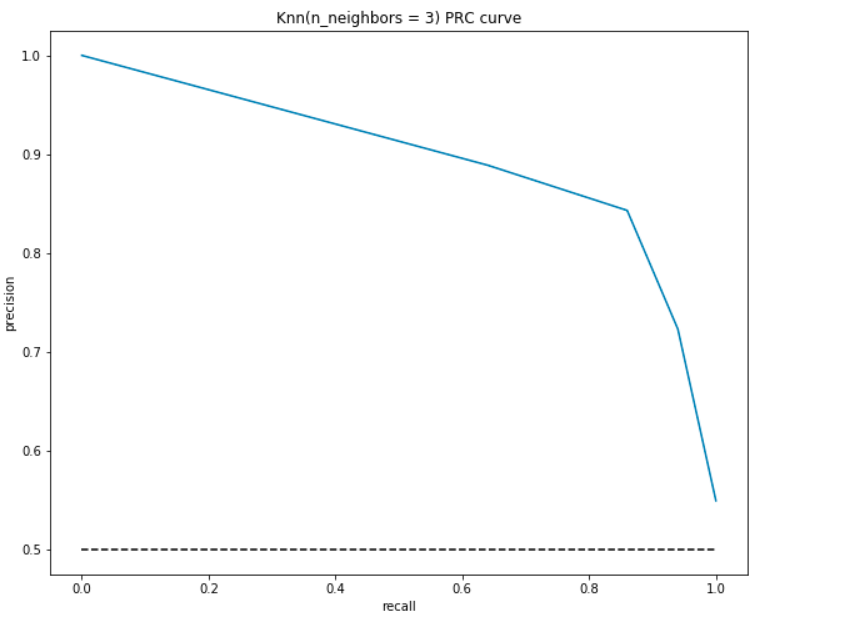
RPC Interpretare:- La punctul cel mai de jos, adică, la (0, 0)- pragul este stabilit la 1,0. Aceasta înseamnă că modelul nostru nu face distincții între pacienții care suferă de boli de inimă și pacienții care nu suferă.
- la cel mai înalt punct, adică la (1, 1), pragul este stabilit la 0,0. Acest lucru înseamnă că atât precizia noastră, cât și rechemarea sunt ridicate, iar modelul face distincții perfect.
- restul curbei este valorile de precizie și rechemare pentru valorile de prag între 0 și 1. Scopul nostru este de a face curba cât mai aproape de (1, 1) posibil – ceea ce înseamnă o precizie bună și rechemare.,
- Similar cu ROC, zona cu curba și axele ca limite este zona sub curbă (ASC). Luați în considerare această zonă ca o metrică a unui model bun. ASC variază de la 0 la 1. Prin urmare, ar trebui să vizăm o valoare ridicată a ASC. Să calculăm ASC pentru modelul nostru și graficul de mai sus:

ca și înainte, obținem o ASC bună de aproximativ 90%. De asemenea, modelul poate obține o precizie ridicată cu rechemare ca 0 și ar obține o rechemare ridicată prin compromiterea preciziei de 50%.,pentru a încheia, în acest articol, am văzut cum să evaluăm un model de clasificare, concentrându-ne în special pe precizie și rechemare și să găsim un echilibru între ele. De asemenea, vă explicăm cum să reprezentăm performanța modelului nostru folosind diferite valori și o matrice de confuzie.
Iată un articol suplimentar pentru a înțelege valorile de evaluare – 11 valori importante de evaluare a modelului pentru învățarea automată pe care toată lumea ar trebui să le cunoască