Yleistä
- Tarkkuutta ja muistaa kaksi tärkeää vielä väärin aiheita kone oppiminen
- Voimme keskustella siitä, mitä tarkkuutta ja muistaa, miten ne toimivat, ja niiden rooli arvioitaessa kone oppimisen malli
- Me myös saada käsitys siitä, Käyrän alapuolisen Alueen (AUC) ja Tarkkuuden kannalta
Johdanto
Kysy mitä tahansa koneoppimisen ammatti-tai data scientist kaikkein hämmentävää käsitteitä niiden oppimisen matka., Ja poikkeuksetta vastaus vie kohti tarkkuutta ja takaisinkutsua.
ero Tarkkuus ja Muistaa on todella helppo muistaa – mutta vain, kun olet todella ymmärtää, mitä kukin termi tarkoittaa. Mutta melko usein, ja voin todistaa tämän, asiantuntijat ovat taipuvaisia tarjoamaan puolivillaisia selityksiä, jotka hämmentävät tulokkaita vielä enemmän.
joten tehdään ennätys suoraan tässä artikkelissa.

mistään kone oppimisen malli, me tiedämme, että saavuttaa hyvä fit-malli on erittäin tärkeää., Tämä edellyttää saavuttaa tasapaino underfitting ja overfitting, tai toisin sanoen, kompromissi välillä harha ja varianssi.
kuitenkin luokittelun suhteen – on toinenkin tradeoff, joka usein unohdetaan suosia bias-varianssi tradeoff. Tämä on tarkkuusalkometri. Epätasapainoinen luokat esiintyy yleisesti aineistot ja kun se tulee erityisiä käyttää tapauksissa, olisimme itse asiassa, kuten antamaan enemmän huomiota tarkkuutta ja muistaa tietoja, ja myös miten saavuttaa tasapaino niiden välillä.
But, how to do so?, Tutkimme luokituksen arviointimittareita keskittymällä tarkkuuteen ja takaisinkutsuun tässä artikkelissa. Opettelemme myös laskemaan nämä mittarit Pythonissa ottamalla datasetin ja yksinkertaisen luokittelualgoritmin. Aloitetaan!
voit tutustua arviointimittareihin syvällisesti tässä-Koneoppimismallien Arviointimittareihin.
Sisällysluettelo
- Ymmärrystä Ongelman Selvitys
- Mikä on Tarkkuus?
- mikä on takaisinkutsu?,
- Helpoin Arviointi Metric – Tarkkuus
- Rooli F1-Pisteet
- Kuuluisa Tarkkuus-Muistaa Kompromissi
- Ymmärrystä Käyrän alapuolisen Alueen (AUC-arvo)
Ymmärtäminen-Ongelman Selvitys
uskon vahvasti tekemällä oppiminen. Joten koko tämän artikkelin, puhumme käytännössä-käyttämällä dataset.
otetaan suosittu sydänsairaus Aineisto saatavilla UCI-arkistoon. Täällä, meillä on ennustaa, jos potilas kärsii sydämen sairaus tai ei, käyttämällä annettuja ominaisuuksia., Voit ladata puhtaan datasetin täältä.
Koska tämä artikkeli on yksinomaan keskittyy malli arvioinnin mittareita, käytämme yksinkertaisin luokittelija – kNN luokittelu malli tehdä ennusteita.
Kuten aina, aloitamme tuomalla tarvittavat kirjastot ja paketit:
Niin käykäämme katsomaan tiedot ja tavoitemuuttujien olemme tekemisissä:
Anna meille tarkistaa, jos meillä on puuttuvia arvoja:
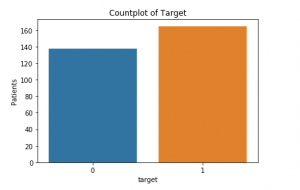
ei ole puuttuvia arvoja., Nyt voimme katsoa, kuinka monet potilaat ovat todella kärsivät sydänsairaus (1) ja kuinka monet eivät ole (0):
Tämä on laskea tontin alla:
olkaamme edetä jakamalla meidän koulutus ja testi tiedot ja meidän tulo-ja tavoitemuuttujien. Koska käytämme KNN, se on pakollista mittakaavassa meidän aineistot liian:
intuitio takana valitsemalla paras arvo k ei kuulu tämän artikkelin, mutta meidän pitäisi tietää, että voimme määrittää optimaalisen arvon k, kun me saada korkein testi pisteet, että arvo., Sillä, että voimme arvioida koulutuksen ja testauksen tulokset jopa 20 naapurit:
arvioida, max testi pisteet ja k-arvoihin liittyy se, suorita seuraava komento:

Näin ollen olemme saaneet optimaalinen arvo k on 3, 11, tai 20 pisteet vastaavan järjestelmän ansiosta 83,5. Me viimeistellä yksi näistä arvoista ja sovi mallin mukaisesti:

Nyt, miten voimme arvioida, onko tämä malli on ”hyvä” malli vai ei?, Sillä, että käytämme jotain kutsutaan Confusion Matrix:
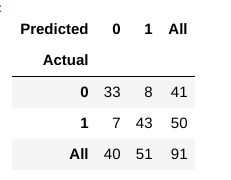
sekavuus matrix auttaa meitä saamaan käsityksen siitä, miten oikea ennustukset olivat ja kuinka he pidä vastaan todellisia arvoja.
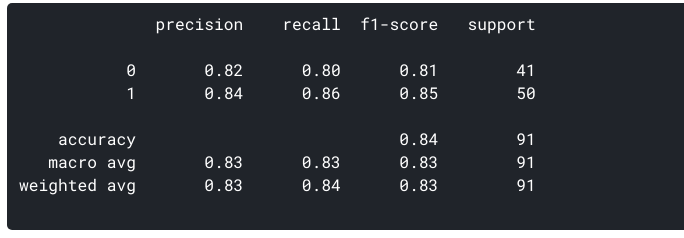
juna-ja testitietojemme perusteella tiedämme jo, että testitietomme koostuivat 91 datapisteestä. Tämä on 3. rivin ja 3. sarakkeen arvo lopussa. Huomaamme myös, että on olemassa joitakin todellisia ja ennustettuja arvoja. Todelliset arvot ovat datapisteiden lukumäärä, jotka alun perin luokiteltiin 0 tai 1., Ennustetut arvot ovat KNN-mallimme ennustamien datapisteiden määrä 0 tai 1.
todelliset arvot ovat:
- potilaat, jotka todella ei ole sydänsairaus = 41
- potilailla, joilla on sydän sairaus, = 50
ennustetut arvot ovat:
- Useita potilaita, jotka olivat ennustaneet, joilla ei ole sydänsairaus = 40
- Useita potilaita, jotka olivat ennustaa, joilla on sydänsairaus = 51
Kaikki arvot saadaan edellä on termi., Käydään ne yksitellen:
- tapauksissa joissa potilas itse ei on sydän sairaus, ja meidän malli ennusti myös, koska ei ole sitä kutsutaan Tosi Negatiivisia. Meidän matriisi, True Negatives = 33.
- tapauksia, joissa potilailla todella on sydänsairaus ja mallimme myös ennusti, että se on nimeltään todellinen positiivisia. Matriisillemme True Positives = 43
- on kuitenkin joitakin tapauksia, joissa potilaalla ei todellisuudessa ole sydänsairautta,mutta mallimme on ennustanut niin., Tällainen virhe on tyypin I virhe ja kutsumme arvoja vääriksi positiivisiksi. Meidän matriisi, Vääriä Positiivisia = 8
- Samoin, on olemassa joitakin tapauksia, joissa potilas itse on sydän sairaus, mutta meidän malli on ennustanut, että hän/hän ei ole. Tällainen virhe on Tyypin II Virhe ja me kutsumme arvot kuin Vääriä Negatiivisia. Matriisillemme väärät negatiivit = 7
mikä on tarkkuus?
Right-so now we come to the crux of this article. Mitä ihmettä tarkkuus on? Ja mitä tekemistä kaikella edellä mainitulla oppimisella on sen kanssa?,
yksinkertaisimmillaan tarkkuus on todellisten positiivisten ja kaikkien positiivisten välinen suhde. Ongelmalausuntoamme varten se olisi niiden potilaiden mitta, jotka tunnistamme oikein sydänsairauden kaikista niistä potilaista, joilla sitä todella on. Matemaattisesti:

Mikä on Tarkka malli? Kyllä, se on 0.843 tai, kun se ennustaa, että potilaalla on sydänsairaus, se on oikein, noin 84% ajasta.
tarkkuus antaa myös mittauksen asiaan liittyvistä datapisteistä., On tärkeää, ettemme ala hoitaa potilasta, jolla ei oikeasti ole sydänsairautta,mutta mallimme ennusti sen olevan.
mikä on takaisinkutsu?
takaisinkutsu on mallimme mitta, joka tunnistaa oikein todelliset positiiviset. Näin ollen kaikille potilaille, joilla todella on sydänsairaus, recall kertoo meille, kuinka monta tunnistimme oikein sydänsairaudeksi. Matemaattisesti:

– meidän malli, Recall = 0.86. Takaisinkutsu antaa myös mittarin siitä, kuinka tarkasti mallimme pystyy tunnistamaan asiaankuuluvat tiedot., Kutsumme sitä herkkyydeksi tai todelliseksi Positiivisuudeksi. Entä jos potilaalla on sydänsairaus, mutta hänelle ei anneta hoitoa, koska mallimme ennusti niin? Tätä tilannetta haluaisimme välttää!
helpoin metriikka ymmärtää – tarkkuus
nyt tulee yksi kaikkein yksinkertaisimmista mittareista, tarkkuus. Tarkkuus on oikeiden ennusteiden kokonaismäärän ja ennusteiden kokonaismäärän suhde. Arvaatko, mikä on täsmällisyyden kaava?
![]()
– meidän malli, Tarkkuus on = 0.835.,
tarkkuuden käyttäminen mallimme määrittävänä mittarina on intuitiivisesti järkevää, mutta useimmiten on aina suositeltavaa käyttää myös tarkkuutta ja takaisinkutsua. Voi olla muitakin tilanteita, joissa tarkkuutemme on erittäin korkea, mutta tarkkuutemme tai takaisinkutsumme on alhainen. Ihannetapauksessa, meidän malli, haluaisimme täysin välttää kaikki tilanteet, joissa potilaalla on sydän sairaus, mutta meidän malli luokittelee hänet joilla ei ole sitä eli, tavoitteena korkea muistaakseni.,
toisaalta, varten tapauksissa, joissa potilas ei kärsi sydänsairauksien ja meidän malli ennustaa, päinvastoin, haluamme myös välttää potilaan hoitamiseksi, ei sydän-ja verisuonitaudit(ratkaiseva, kun input-parametrit voisi osoittaa eri sairaus, mutta päädymme kohtelevat häntä/hänen sydän-sairaus).
vaikka tavoittelemme suurta tarkkuutta ja suurta takaisinkutsuarvoa, molempien saavuttaminen samanaikaisesti ei ole mahdollista., Esimerkiksi, jos haluamme muuttaa malli, joka antaa meille korkea recall, emme voisi havaita kaikki potilaat, joilla on sydän sairaus, mutta saatamme antaa hoitoja on paljon potilaita, jotka eivät kärsi siitä.
Vastaavasti, jos tavoitteena on korkea tarkkuus välttää antamasta väärää ja valinnaisia hoito, me lopulta saada paljon potilaita, joilla on sydän sairaus menee ilman mitään hoitoa.
Rooli F1-Pisteet
Ymmärtäminen Tarkkuus sai meidät ymmärtämään, tarvitaan kompromissi Tarkkuuden ja Muistaa., Meidän on ensin päätettävä, mikä on luokitusongelmamme kannalta tärkeämpää.
esimerkiksi, meidän aineisto, voimme harkita, että saavutetaan korkea recall on tärkeämpää kuin saada korkea tarkkuus – haluamme havaita, koska monet sydänpotilaiden kuin mahdollista. Jotkut muut mallit, kuten luokittelua, onko pankin asiakas on lainan laiminlyöjän tai ei, se on toivottavaa saada korkea tarkkuus, koska pankki ei halua menettää asiakkaita, jotka evättiin laina perustuva malli on ennuste, että he olisivat defaulters.,
on myös paljon tilanteita, joissa sekä tarkkuus että takaisinkutsu ovat yhtä tärkeitä. Esimerkiksi, meidän malli, jos lääkäri kertoo, että potilaat, jotka oli virheellisesti luokiteltu, jotka kärsivät sydän-tauti ovat yhtä tärkeitä, koska ne voisivat olla osoitus jokin muu sairaus, niin meidän tavoitteena olisi paitsi korkea muistuttaa, mutta korkean tarkkuuden kuin hyvin.
tällaisissa tapauksissa käytämme jotain kutsutaan F1-pisteet., F1-pisteet on Harmoninen keskiarvo Tarkkuus ja Muistaa:

Tämä on helpompi työskennellä, koska nyt, sen sijaan tasapainottaa tarkasti ja muistaa, voimme vain pyrkiä hyvä F1-pisteet ja tämä olisi osoitus hyvä Tarkkuus ja hyvä Muistaa, arvo samoin.,
Voimme tuottaa edellä mainitut mittarit meidän dataset käyttäen sklearn liian:
ROC-Käyrä
Yhdessä edellä mainitut ehdot, on enemmän arvot voidaan laskea sekaannusta matriisi:
- Vääriä Positiivisia (FPR): Se on suhde Väärien Positiivisten Todellinen määrä Negatiivit. Mallimme yhteydessä mitataan, kuinka monta tapausta malli ennusti, että potilaalla on sydänsairaus kaikilta potilailta, joilla ei oikeasti ollut sydänsairautta. Tietojemme mukaan FPR on = 0.,195
- True Negative Rate (TNR) tai Erityisyys: Se on suhde Todellinen Negatiivit ja Todellinen Määrä Negatiivit. Meidän malli, se on mitata, kuinka monta tapausta ei malli oikein ennustaa, että potilas ei ole sydän-potilaat, jotka todella ei ollut sydänsairauksia. Yllä olevien tietojen TNR = 0,804. Näistä 2 määritelmät, voimme myös päätellä, että Erityisyys tai TNR = 1 – FPR
Voimme myös visualisoida Tarkasti ja Muistaa käyttää ROC-käyrät ja KIINAN käyrät.,
ROC-käyrät(vastaanottimen ominaiskäyrä):
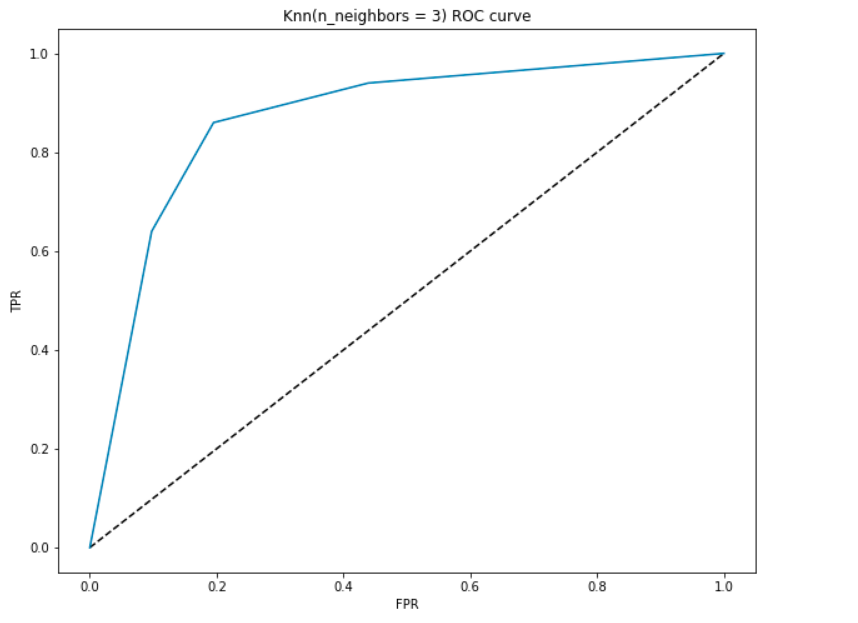
se on TPR: n(y-akselin) ja FPR: n(x-akselin) välinen käyrä. Koska mallimme luokittelee potilaan sydänsairaudeksi tai ei kullekin luokalle syntyneiden todennäköisyyksien perusteella, voimme myös päättää todennäköisyyksien kynnyksen.
esimerkiksi halutaan asettaa raja-arvo 0,4. Tämä tarkoittaa sitä, että malli tulee luokitella datapoint/potilas, joilla on sydän sairaus, jos todennäköisyys, että potilaalla on sydänsairaus, on suurempi kuin 0.4., Tämä luonnollisesti antaa korkean takaisinkutsuarvon ja vähentää vääriä positiivisia. Samoin voimme visualisoida, miten mallimme toimii eri raja-arvoille ROC-käyrän avulla.
let us generate a ROC curve for our model with k = 3.
AUC-Tulkinta-
- alimmassa kohdassa, eli pisteessä (0, 0)- kynnys on asetettu 1.0. Tämä tarkoittaa, että mallimme luokittelee kaikki potilaat, joilla ei ole sydänsairautta.
- korkeimmassa kohdassa eli kohdassa (1 ,1) kynnysarvo on 0,0., Tämä tarkoittaa, että mallimme luokittelee kaikki potilaat sydänsairaudeksi.
- muu käyrä on FPR: n ja TPR: n arvot 0-1: n raja-arvoille. Jollain kynnysarvolla havaitsemme, että FPR: n osalta lähes 0, saavutamme TPR: n, joka on lähes 1. Tällöin malli ennustaa sydäntautia sairastavia potilaita lähes täydellisesti.
- käyrän ja akselien aluetta, koska rajoja kutsutaan käyrän alle jääväksi alueeksi (AUC). Juuri tätä aluetta pidetään hyvän mallin mittarina., Tämän mittarin ollessa 0-1, meidän pitäisi pyrkiä suureen AUC-arvoon. Malleja, joiden AUC on korkea, kutsutaan malleiksi, joilla on hyvä taito. Olkaamme laskea AUC-pisteet meidän malli ja edellä juoni:

- Saamme arvon 0.868 kuin AUC joka on melko hyvät pisteet! Yksinkertaisimmillaan tämä tarkoittaa, että malli pystyy erottamaan sydänsairauksista kärsivät ja ne, jotka eivät 87 prosenttia ajasta. Voimme parantaa tätä pistemäärää ja kehotan kokeilemaan erilaisia hyperparametriarvoja.,
- diagonaaliviiva on satunnaismalli, jonka AUC on 0,5, malli, jolla ei ole taitoa, joka on aivan sama kuin satunnaisennustuksen tekeminen. Arvaatko miksi?
Tarkkuus-Recall-Käyrä (PRC)
Kuten nimestä voi päätellä, tämä käyrä on suora edustus tarkkuus(y-akseli) ja recall(x-akseli). Jos noudatat meidän määritelmät ja kaavat Tarkasti ja Muistaa edellä, huomaat, että ei ole missään vaiheessa käytämme Totta Negatiivit(todellinen määrä ihmisiä, joilla ei ole sydänsairaus).,
Tämä on erityisen hyödyllistä tilanteissa, joissa meillä on epätasapainoinen aineisto ja määrä negatiivit on paljon suurempi kuin positiivisten(tai kun potilaiden määrä, joilla ei ole sydänsairaus on paljon suurempi kuin potilailla, joilla se). Tällaisissa tapauksissa suurempi huolemme olisi havaita sydänsairautta sairastavat potilaat mahdollisimman oikein eikä tarvitsisi TNR: ää.
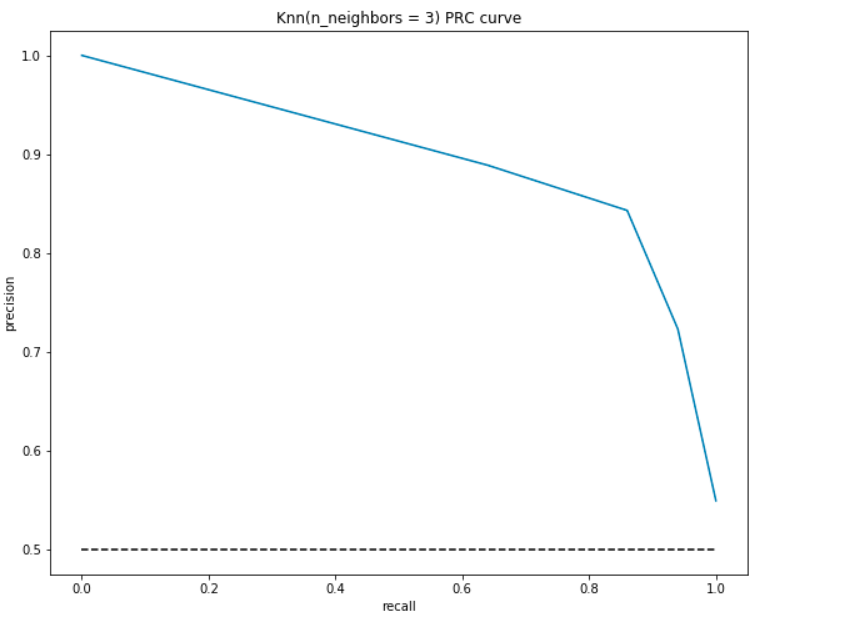
Kuten ROC, meidän tontti tarkkuus ja muistaa eri raja-arvot:
KIINAN Tulkinta:
- alimmassa kohdassa eli, at (0, 0)- kynnysarvo on 1,0. Tämä tarkoittaa, että malli ei tee eroa potilailla, joilla on sydänsairaus ja potilaille, jotka eivät.
- korkein kohta eli (1, 1), kynnys on asetettu 0.0. Tämä tarkoittaa sitä, että sekä tarkkuutemme että takaisinkutsumme ovat korkeita ja malli tekee erottelut täydellisesti.
- muu käyrä on 0-1: n raja-arvojen tarkkuus-ja Takaisinkutsuarvot. Tavoitteenamme on tehdä käyrästä mahdollisimman lähellä (1, 1) – eli hyvä tarkkuus ja takaisinkutsu.,
- samanlainen kuin ROC, alue, jolla on käyrä ja akselit, koska rajat ovat käyrän alla oleva alue (AUC). Pidä tätä aluetta hyvän mallin mittarina. AUC vaihtelee välillä 0-1. Siksi meidän pitäisi pyrkiä korkeaan AUC-arvoon. Olkaamme laskea AUC meidän malli ja edellä juoni:

Kuten ennenkin, saamme hyvän AUC-arvo oli noin 90%. Myös malli voi saavuttaa korkean tarkkuuden kanssa muista kuin 0 ja saavuttaa korkea recall tinkimättä tarkkuus 50%.,
End Huomautuksia
lopuksi tässä artikkelissa näimme, miten arvioida luokittelu malli, erityisesti keskittyen tarkkuutta ja muistaa, ja löytää tasapaino niiden välillä. Selitämme myös, miten mallimme suorituskykyä voidaan edustaa erilaisilla mittareilla ja sekamatriisilla.
Täällä on lisää artikkelissa, voit ymmärtää arvioinnin mittarit – 11 Tärkeää, Malli Arviointi, Mittarit koneoppimisen Kaikkien pitäisi tietää,