Codice a barre 101: Guida alle simbologie dei codici a barre
Un simbolo del codice a barre è un’immagine leggibile dalla macchina che trasmette i dati. I codici a barre possono essere suddivisi in tre tipi generali: lineari, lineari impilati e bidimensionali (o 2D): Codici a barre lineari
UPC-A
L’UPC-A (noto anche semplicemente come UPC) è il codice a barre “price code” standard negli Stati Uniti. UPC-A è strettamente numerico; le barre possono rappresentare solo le cifre da 0 a 9., Un codice a barre UPC-A contiene 12 cifre, insieme a una zona tranquilla (vuota) su entrambi i lati e i simboli start, middle e stop. Il simbolo centrale separa il lato sinistro e il lato destro, che sono codificati in modo diverso. Quando si utilizza una cifra sul lato sinistro, le barre sono nere e gli spazi sono bianchi, e quando viene utilizzato sul lato destro, i colori sono invertiti., La logica alla base di questo è un po ‘ complicata e coinvolge una proprietà matematica chiamata “parità”, ma l’effetto è invertire il bianco e nero e consentire allo scanner di dire se sta leggendo il codice da sinistra a destra o da destra a sinistra.
L’attuale sistema di numerazione dipende dal tipo di prodotto e dallo scopo del codice a barre; la prima cifra del codice a barre indica il sistema di numerazione., Le 10 cifre che seguono contengono informazioni sul prodotto e, in tutte le applicazioni descritte di seguito, la cifra all’estrema destra (non inclusa nella descrizione dell’applicazione) è un checksum, che può essere utilizzato per testare l’accuratezza della lettura dello scanner. Di seguito è riportato un elenco di applicazioni UPC-A comuni:




UPC-E
Il codice a barre UPC-E può essere utilizzato quando lo spazio disponibile è troppo piccolo per un codice a barre UPC-A. contiene le stesse informazioni di un’etichetta UPC-A, ma utilizza alcuni trucchi per ridurre il numero di cifre a sei.,

il trucco più semplice di UPC-E code consiste nel rimuovere gli zeri finali nel codice del produttore e gli zeri iniziali nel codice del prodotto. I dettagli della tecnica sono complicati e non funziona per tutto, ma copre tutti i codici con un totale di 5 zeri iniziali/finali, oltre a un numero significativo di codici con quattro zeri.
UPC-E utilizza un trucco molto più complesso per comprimere il checksum e il codice del sistema numerico. Un effetto collaterale di questa tecnica è che gli unici codici del sistema di numerazione consentiti sono 0 e 1.,
EAN-13
Il codice EAN-13 è fondamentalmente una versione internazionale di UPC-A. EAN-13 aggiunge una 13a cifra sul lato sinistro del codice UPC-A (in modo che diventi la prima cifra). Lo standard EAN-13 include i codici a barre UPC-A; l’aggiunta di uno 0 iniziale a un codice UPC-A lo trasforma nell’equivalente codice EAN-13.

Le principali differenze tra EAN-13 e UPC-A (oltre alla cifra iniziale extra) sono che con EAN-13, i codici produttore e prodotto possono variare in lunghezza e che le prime tre cifre costituiscono il prefisso GS1 o “codice paese.,”
Il prefisso GS1 è rilasciato da GS1, l’international barcode standards organization. Può identificare l’organizzazione nazionale GS1 membro o un uso speciale. Le organizzazioni membri emettono i codici del produttore e i produttori impostano i propri codici prodotto. Il codice a barre EAN-13 completo, costituito dal prefisso GS1, dal codice del produttore, dal codice del prodotto e dalla cifra di controllo, è noto anche come GTIN o Global Trade Item Number.,Oltre ai prefissi nazionali GS1, tipicamente utilizzati per articoli al dettaglio standard, ci sono prefissi per scopi specializzati, come coupon, rimborsi, pubblicazioni seriali (riviste e giornali), libri (ISBN) e spartiti (ISMN).

Negli Stati Uniti, i codici prezzo e i sistemi point-of-sale / inventory sono in genere in grado di leggere sia i codici a barre UPC-A che EAN-13.
EAN-8
EAN-8 è un codice a barre GS1 per l’uso su piccoli oggetti quando un’etichetta di codice a barre EAN-13 completa sarebbe troppo grande per adattarsi., Consiste di otto cifre: quattro sul lato sinistro e quattro sulla destra. Usano lo stesso tipo di codifica di UPC-A e EAN-13, con l’ultima cifra utilizzata come checksum.

Un codice a barre EAN-8 può essere utilizzato con i numeri di identificazione del prodotto GTIN-8 o RCN-8.
GTIN-8 è come una versione abbreviata del codice EAN-13, ma senza informazioni sull’origine del prodotto. Per poter utilizzare un numero GTIN-8, un produttore deve richiederlo all’organizzazione nazionale membro., Un codice a barre EAN-8 che codifica un numero di identificazione GTIN-8 è valido per l’uso globale, come un codice a barre EAN-13.
I numeri RCN-8, d’altra parte, sono per l’uso solo su prodotti house-brand o store-label e possono essere utilizzati solo all’interno dell’azienda che lo emette. Se viene scansionato da un altro rivenditore, darà una lettura errata.
Codice 128
I codici a barre “codice prezzo” UTF ed EAN descritti sopra codificano solo i numeri, ma il codice 128 è un codice a barre lineare che codifica sia le lettere dell’alfabeto che i numeri, rendendolo utile per una varietà di scopi oltre ai prezzi di base e all’inventario.,
Il codice 128 codifica il set ASCII di 128 caratteri, che include tutti i caratteri alfabetici, numerici, di punteggiatura e aritmetici presenti sulla tastiera di un computer in lingua inglese, oltre a diversi caratteri di controllo non visibili.,
al fine di includere tutti i caratteri ASCII, Code 128 utilizza tre diversi set di caratteri:



Un singolo codice a barre Code 128 può includere caratteri di tutti e tre i set di caratteri, passando da uno all’altro ripetutamente.
Il formato del codice a barre basic Code 128 è costituito da un codice di avvio (che imposta il carattere iniziale impostato su A, B o C), i dati del codice, una cifra di checksum e un codice di arresto, che segna la fine del codice a barre. Come con altri codici a barre lineari, ci sono zone silenziose vuote su entrambi i lati.
GS1-128 (noto anche come UCC-128 e EAN-128) è uno standard internazionale per l’utilizzo del codice 128 nelle etichette di codici a barre della supply chain., GS1-128 è costituito dal formato basic Code 128 con un identificatore di applicazione aggiunto ai dati del codice.

Gli identificatori delle applicazioni sono lunghi da 2 a 4 caratteri e identificano il tipo di dati che seguiranno, in genere le applicazioni standard della supply chain, come numero di serie, numero di contenitori, numero di lotto, peso, volume, ecc., compreso tracciando e informazioni di transazione. Ogni identificatore imposta la lunghezza e il formato dei dati che lo seguono.,
Poiché la maggior parte dei dati di codice dell’applicazione è di lunghezza fissa, è possibile includere diversi codici in un codice a barre GS1-128, semplicemente aggiungendo nuovi identificatori di applicazione e dati di codice.

Codice 39
La simbologia del codice 39 è anche alfanumerica e di lunghezza variabile. È stato sviluppato nel 1974 ed è ancora in uso relativamente ampio; la maggior parte dei lettori di codici a barre può leggere il codice 39. Nel codice 39, ogni carattere è composto da cinque barre e quattro spazi, con tre di quelle barre/spazi larghi e gli altri stretti., Di conseguenza, tutti i caratteri hanno la stessa larghezza e un codice a barre Code 39 occupa generalmente più spazio rispetto al codice a barre Code 128 equivalente.

Il sistema basic Code 39 è composto da 43 caratteri, tra cui lettere maiuscole, numeri e alcuni caratteri speciali / di punteggiatura. A seconda dell’applicazione e del sistema, potrebbe essere possibile utilizzare tutti i 128 caratteri ASCII.
Un codice a barre Code 39 è costituito da un carattere di inizio, i dati codificati, e un carattere di arresto., Entrambi i caratteri start e stop sono identici e sono generalmente rappresentati dal simbolo * asterisco. non esiste un carattere di checksum, ma alcune funzionalità di controllo degli errori sono integrate nel sistema di codifica.
Il codice 39 viene utilizzato per molti degli stessi tipi di applicazioni del codice 128 e esistono standard ufficiali del codice 39 (incluso uno standard ANSI). Non è, tuttavia, incluso nel sistema GS1.
Interleaved 2 of 5
Interleaved 2 of 5 (o ITF) è un codice a barre lineare a lunghezza variabile solo numeri., Codifica le cifre in coppie, con la prima cifra in ogni coppia rappresentata da barre e la seconda cifra rappresentata da spazi, in modo che siano interlacciati. Due delle cinque barre o spazi che rappresentano ogni cifra sono larghe e le altre sono strette.

Interleaved 2 of 5 è incluso nel sistema GS1 come standard ITF-14, che ha una lunghezza impostata di 14 cifre.,
Un codice a barre ITF è costituito da un codice di avvio (due coppie di barre strette/spazi stretti), i dati codificati, una cifra di checksum (richiesta per ITF-14, opzionale altrove) e un codice di arresto (barra larga, spazio stretto, barra stretta), con zone tranquille su entrambi i lati.
All’interno dei dati codificati possono verificarsi pattern identici al codice di avvio e arresto, che possono risultare in una lettura errata se lo scanner non legge il codice fino in fondo. Per evitare ciò, lo standard ITF-14 richiede un bordo nero pesante chiamato barra portatore.,
ITF codici a barre sono in genere utilizzati in commercio all’ingrosso e spedizione per scatola o cartone lotti di un prodotto. Una versione specializzata del codice a barre ITF viene utilizzata anche su 135 contenitori di pellicola.
Codabar
Codabar è stato originariamente sviluppato da Pitney Bowes nel 1972. È un codice a barre di lunghezza variabile che utilizza un piccolo set di barre per codificare le cifre da 0 a 9 e, in alcune applicazioni, alcuni simboli come il dollaro e i segni più. include anche quattro simboli start / stop (generalmente rappresentati da A, B, C e D). Un codice Codabar è costituito da un simbolo di inizio, i dati codificati, e un simbolo di arresto., è autocontrollo, anche se alcune applicazioni specificano una cifra di controllo.

Codabar è stato tradizionalmente utilizzato dalle biblioteche, dalle banche del sangue, e per airbills da alcune aziende come Federal Express, ed è ancora in uso per alcune di queste applicazioni.
Pharmacode
Pharmacode è progettato per il controllo e la sicurezza degli imballaggi nell’industria farmaceutica.

Il codice a barre APharmacode è costituito da due larghezze di barre, con una lunghezza fino a 12 barre., I dati sono un singolo numero intero (nell’intervallo da 3 a 131070) codificato come numero binario. I codici a barre Pharmacode possono utilizzare più colori come controllo aggiuntivo per la precisione dell’imballaggio.

Le singole aziende farmaceutiche generano i propri codici a barre Pharmacode. Vengono utilizzati sulla linea di produzione, dove vengono scansionati automaticamente su inserti e altri articoli inseriti nella confezione, al fine di rilevare i disallineamenti.
Databar
Databar è una famiglia GS1 di standard di codici a barre generalmente destinati ad applicazioni di spazio ridotto., Codificano i dati GTIN-12 (UPC-A) e GTIN-13 (EAN-13) in un formato a 14 cifre (con zeri iniziali aggiunti). I codici a barre lineari della famiglia Databar includono i codici omnidirezionali e espansi, che possono essere scansionati omnidirezionalmente, e i codici troncati e limitati, che sono progettati per essere letti solo da scanner portatili.

I codici Databar omnidirezionali e espansi sono utilizzati nelle applicazioni point-of-sale, come UPC-A e EAN-13., I codici espansi possono includere informazioni aggiuntive come il peso e la data di scadenza, designate utilizzando gli identificatori dell’applicazione alla maniera dei codici a barre GS1-128.

I codici a barre Databar troncati e limitati sono generalmente utilizzati nel settore sanitario per l’identificazione di piccoli oggetti.

Postal (Postnet)
Postnet è il sistema di codici a barre che è stato utilizzato dal Servizio postale degli Stati Uniti per il routing della posta; viene gradualmente eliminato a favore del sistema di posta intelligente, descritto di seguito., I codici Postnet utilizzano barre ad altezza variabile per rappresentare le cifre.
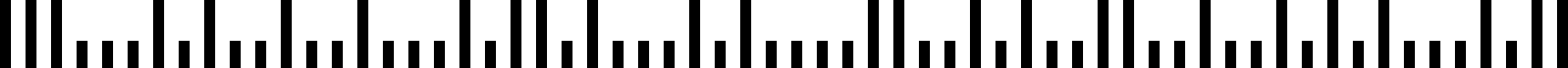
Un codice a barre Postnet è tipicamente costituito dai codici ZIP, ZIP+4 e del punto di consegna, con ogni cifra rappresentata da cinque barre, due delle quali sono a tutta altezza e il resto a mezza altezza.Postal (Intelligent Mail Barcode)
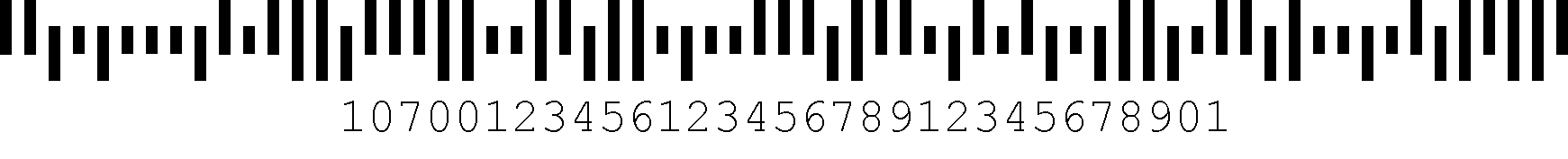
Il sistema Intelligent Mail Barcode sta sostituendo il sistema Postnet per il routing della posta da parte dell’USPS. È un codice a 65 barre di altezza variabile con quattro tipi di barre.,
E il codice a barre IM è costituito dai seguenti componenti:
Codici a barre in Pila
Pila dei codici a barre codici a barre lineari, che sono divisi in segmenti e posti uno sopra l’altro

Databar Stacked
La pila versioni del GS1 Databar codici di utilizzare la stessa codifica di base come la lineare Databar codici sopra descritti, e sono utilizzati in applicazioni simili. Sono particolarmente utili per articoli con spazio limitato con etichette che hanno dimensioni lineari molto strette.,
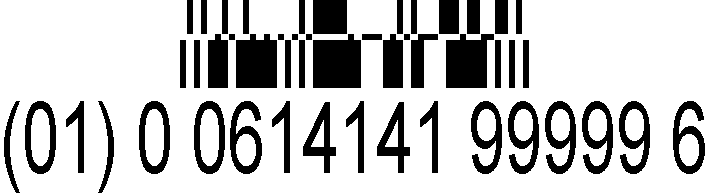
Il GS1 Expanded Stacked Databar può impilare una serie di codici a barre contenenti i dati del prodotto in aggiunta al codice di base del punto vendita EAN-13 prezzo.
PDF417
PDF417 è un codice a barre impilati di altezza variabile e larghezza variabile costituito da file di barre corte e spazi. Può avere fino a 3 righe o fino a 90. Tutte le righe devono contenere lo stesso numero di codewords di dati, ma tale numero può variare da 1 a 30.,

L’attuale metodo di codifica si basa su un sistema complesso che utilizza circa 900 codewords per rappresentare i dati in diversi formati. Ciò consente a PDF417 di codificare testo, dati digitali (in byte) e grandi numeri all’interno dello stesso codice a barre.
Ogni riga di un codice a barre PDF417 è costituita da un modello di inizio, il codice di sinistra-aveva (identificando la riga, tra le altre cose), i codici di dati, il codice di destra, e il modello di arresto. A differenza della maggior parte dei codici a barre 2D, PDF417 può essere letto con uno scanner laser.,
I codici a barre PDF417 possono essere collegati in modo che grandi quantità di dati possano essere scansionati in sequenza. Ciò rimuove efficacemente il limite nella quantità di dati che possono essere codificati, rendendo il formato PDF417 competitivo con veri codici a barre 2-D per rappresentare grandi quantità di dati.
Il PDF417 è in uso come formato di codici a barre ad alta densità in una serie di applicazioni, tra cui:
MicroPDF417
MicroPDF417 è un sottoinsieme limitato di PDF417 progettato per situazioni in cui un codice PDF417 completo sarebbe troppo grande. Pone limiti alle dimensioni delle barre e alla quantità e al formato dei dati che possono essere codificati (fino a 200 caratteri di testo maiuscolo, 150 byte binari o 366 cifre numeriche). pone anche alcune restrizioni sulle codewords di correzione degli errori.
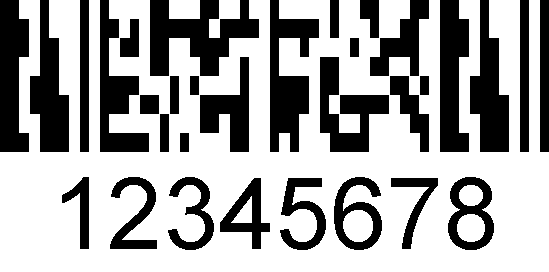
MicroPDF417 è utilizzato nei codici compositi GS1 Databar, dove è combinato con un codice a barre lineare.,
Matrice 2D
A differenza dei codici a barre impilati, i veri codici a matrice 2D rappresentano i dati in un array bidimensionale, come i quadrati su una scacchiera. Ciò consente loro di imballare una grande quantità di dati in uno spazio compatto e di rappresentare un set di caratteri molto più grande. Questi codici devono essere letti con uno scanner di imaging, piuttosto che uno scanner laser.
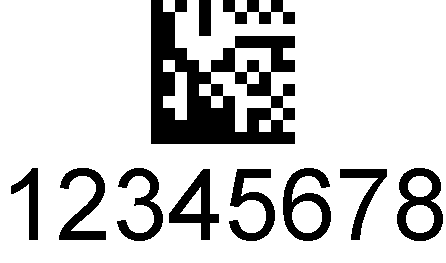
DataMatrix
I codici a barre DataMatrix sono matrici quadrate o rettangolari di quadrati o celle in bianco e nero., Ogni cella è un bit, che rappresenta uno o zero e, a seconda del tipo di codifica, un codice a barre DataMatrix può essere in grado di rappresentare fino a 2.355 caratteri alfanumerici.

Un codice DataMatrix ha due diversi tipi di bordo; su un insieme di lati adiacenti, il bordo è solido, e sugli altri due lati, alterna celle in bianco e nero, che gli dà l’aspetto di avere solo i due bordi solidi., I bordi solidi, o finder, consentono allo scanner di orientare l’immagine del codice, mentre i bordi a celle alternate, o timer, consentono di contare le righe e le colonne.
I codici DataMatrix possono essere estremamente piccoli e possono essere letti a basso contrasto. Ciò consente loro di essere stampati o anche incisi al laser su piccoli oggetti. Possono anche essere scalati fino a dimensioni molto grandi per l’uso su oggetti come macchinari pesanti, edifici o vagoni ferroviari.,
Il sistema di codifica effettivo è complesso e include la memorizzazione ridondante dei dati, quindi se parte di un codice DataMatrix viene persa o danneggiata, potrebbe essere ancora possibile leggere tutti i dati. DataMatrix può codificare numeri e caratteri alfanumerici ASCII utilizzando diversi sistemi di codifica e compressione.
DataMatrix è utilizzato per l’etichettatura di piccoli componenti nell’industria elettronica, sia con etichette stampate, o marcatura diretta; sono utilizzati anche nell’industria alimentare per il controllo della qualità.,La maggior parte degli smartphone può leggere i codici DataMatrix, consentendo loro di essere utilizzati per il marketing, la pubblicità e altre applicazioni in cui è auspicabile l’accesso allo smartphone.
Codice QR
Il formato QR (o Quick Response) è stato originariamente progettato per l’uso nell’industria automobilistica giapponese per tenere traccia delle parti e delle auto sulla catena di montaggio. A causa della sua versatilità, è diventato ampiamente utilizzato in una varietà di applicazioni industriali e consumer-oriented.,

Un codice QR assomiglia a un codice DataMatrix; è quadrato (circondato da una zona vuota) e consiste di celle quadrate in bianco e nero. Ma invece di bordi, utilizza un insieme di grandi quadrati di posizione e allineamento (e un insieme più piccolo di segni di temporizzazione) impostati nel corpo del codice.
Il codice QR può codificare quattro diversi tipi di dati: numeri, caratteri alfanumerici, binari/byte e kana/kanji giapponesi., La codifica alfanumerica è limitata a numeri, lettere maiuscole e qualche punteggiatura, ma la codifica binaria / byte include il set di caratteri ISO 8859-1 Latin-1, che copre completamente o parzialmente le lingue dell’Europa occidentale. La codifica Kana / kanji utilizza il set di caratteri JIS X 0208. Il codice QR può codificare gli URL del sito Web, consentendo agli utenti di telefonia mobile di piacere direttamente a un sito Web scansionando il suo URL codificato.
La dimensione e la densità di un codice QR possono variare, a seconda della quantità di dati da memorizzare., La capacità massima di archiviazione è di circa 7.000 caratteri numerici, 4.200 caratteri alfanumerici, 2.900 caratteri binari o 1.800 caratteri kana/kanji. Un codice QR può essere suddiviso in diversi codici più piccoli, consentendo loro di inserirsi in un’area in cui un codice più grande non si adatterebbe.
I codici QR hanno visto un rapido aumento del numero e della gamma di applicazioni per le quali sono utilizzati negli ultimi anni, in parte perché possono essere facilmente letti da smartphone, tablet e altri dispositivi mobili., Le attuali applicazioni di codice QQR includono:
La versatilità, la capacità e l’accessibilità del codice QR consente di utilizzarlo in una varietà di modi insoliti., I codici QR sono stati inclusi su opere d’arte, francobolli, denaro, lapidi, statue, mostre museali, sentieri escursionistici, copertine di fumetti, biglietti di auguri — praticamente ovunque che possano adattarsi e servire un qualche tipo di funzione.
I brevetti per il codice QR sono detenuti da Denso Wave (una controllata di Denso, che è a sua volta di proprietà di Toyota), che ha scelto di non esercitare i propri diritti di brevetto, e consente l’uso dei codici senza alcun requisito di licenza.
Oltre alle applicazioni di lettura del codice QR, software gratuito e servizi web-based per la generazione di codici QR sono facilmente disponibili.,
Aztec
Il codice a barre Aztec 2D assomiglia ai codici DataMatrix e QR. È costituito da un quadrato di celle in bianco e nero (o pixel) con un simbolo di localizzazione fatto di quadrati concentrici direttamente al centro. L’area centrale (intorno al quadrato occhio di bue) contiene informazioni sulle dimensioni del simbolo, insieme ad altri dati di codifica. Ciò significa che non richiede una zona vuota o un confine. Il codice contiene anche una griglia di riferimento interna di pixel bianco / nero alternati ad ogni 16a riga e colonna.,

I dati sono disposti a spirale dal centro verso l’esterno; ogni strato della spirale è costituito da due anelli di pixel, aggiungendo quattro pixel alla larghezza totale. Il quadrato centrale dell’occhio di bue più lo strato di dati di codifica e dimensione insieme formano il nucleo, che può essere compatto (11 X 11) o pieno (15 X 15). Un simbolo azteco con un nucleo compatto può avere fino a 4 strati. Un simbolo con un nucleo completo può avere 32 livelli e può codificare oltre 3.800 cifre, 3.000 caratteri di testo o 1.900 byte di dati binari., Il testo può essere codificato come ASCII e Latin-1; la modalità di codifica può essere modificata in più punti all’interno dei dati.
Il sistema di codice Azteco è di dominio pubblico, e le applicazioni sono disponibili per la generazione di codici e la loro lettura su dispositivi mobili. Data la somiglianza nel design, leggibilità e capacità, i codici aztechi potrebbero essere utilizzati in molte delle applicazioni per le quali i codici QR stanno diventando popolari, anche se in pratica il loro uso è più limitato.
Codici aztechi sono, tuttavia, abbastanza comuni nel settore dei trasporti., Sono utilizzati sulle carte d’imbarco elettroniche delle compagnie aeree e per i biglietti ferroviari online e mobili in molte parti d’Europa.
Inoltre, sono utilizzati nei sistemi di fatturazione di diverse società canadesi, e il governo polacco li utilizza nel suo sistema di registrazione auto.
Maxicode
MaxiCode è un codice a barre a matrice 2D che assomiglia un po ‘ al codice azteco, solo con un centro tondo invece di uno quadrato. Uno sguardo più attento mostra un’altra differenza — invece di pixel quadrati, i dati sono codificati in punti esagonali che sono disposti in un modello esagonale.,

MaxiCode è stato progettato per una funzione specializzata — routing e tracking pacchetti United Parcel Service — e che continua ad essere il suo uso principale.
A differenza degli altri codici a matrice 2D qui descritti, i simboli MaxiCode hanno una dimensione fissa (circa 1 pollice quadrato) e una quantità fissa di dati che possono essere codificati (circa 93 caratteri, a seconda della modalità dati). Come molti 8 simboli MaxiCode possono essere collegati o concatenati insieme.,
Ci sono cinque modalità di dati in uso corrente (così come due modalità obsolete):
Tutte queste modalità possono includere un messaggio secondario, che per la spedizione UPS di solito contiene informazioni di spedizione e tracciamento più dettagliate. Nelle modalità 4, 5 e 6, il messaggio secondario viene effettivamente unito al messaggio principale.
MaxiCode utilizza cinque set di codici; un singolo messaggio può passare da uno all’altro ripetutamente. I cinque set di codici insieme includono il set di caratteri ASCII standard più la maggior parte dei caratteri Latin-1.