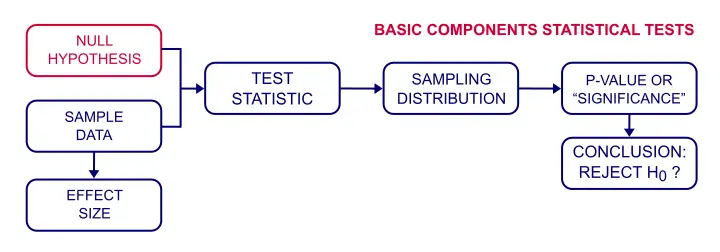
Un’ipotesi nulla è una dichiarazione precisa su una popolazione che cerchiamo di rifiutare con dati di esempio.Di solito non crediamo che la nostra ipotesi nulla (o H0) sia vera. Tuttavia, abbiamo bisogno di una dichiarazione esatta come punto di partenza per il test di significatività statistica.
Esempi di ipotesi nulla
Spesso-ma non sempre – l’ipotesi nulla afferma che non vi è alcuna associazione o differenza tra variabili o sottopopolazioni., Così, tipiche di alcune ipotesi nulla sono:
- la correlazione tra frustrazione e aggressività è zero (correlazione e analisi);
- il reddito medio per gli uomini è simile a quella per le donne (campioni indipendenti t-test);
- è di Nazionalità (perfettamente) estranei alla musica preferenza (chi-quadrato di indipendenza test);
- la popolazione media del reddito è stato pari nel 2012 al 2016 (misure ripetute ANOVA).
“Null” non significa “Zero”
Un malinteso comune è che “null” implica “zero”. Questo è spesso, ma non sempre il caso., Ad esempio, un’ipotesi nulla può anche affermarlola correlazione tra frustrazione e aggressività è 0.5.No zero coinvolto qui e – anche se un po ‘ insolito-perfettamente valido.
Il “null” in “ipotesi nulla” deriva da “nullify”5: l’ipotesi nulla è l’affermazione che stiamo cercando di confutare, indipendentemente dal fatto che non specifichi (non) un effetto zero.
Test di ipotesi nulla-Come funziona?
Voglio sapere se la felicità è legata alla ricchezza tra gli olandesi. Un approccio per scoprirlo è formulare un’ipotesi nulla., Poiché “related to” non è preciso, scegliamo l’affermazione opposta come nostra ipotesi nulla:la correlazione tra ricchezza e felicità è zero tra tutti gli olandesi.Cercheremo ora di confutare questa ipotesi per dimostrare che felicità e ricchezza sono legate bene.
Ora, non possiamo ragionevolmente chiedere a tutti i 17.142.066 olandesi quanto siano felici in genere.

Quindi chiederemo a un campione (diciamo, 100 persone) la loro ricchezza e la loro felicità. La correlazione tra felicità e ricchezza risulta essere 0,25 nel nostro campione., Ora abbiamo un problema: i risultati del campione tendono a differire in qualche modo dai risultati della popolazione. Quindi se la correlazione è davvero zero nella nostra popolazione, potremmo trovare una correlazione diversa da zero nel nostro campione. Per illustrare questo punto importante, date un’occhiata al grafico a dispersione qui sotto. Visualizza una correlazione zero tra felicità e ricchezza per un’intera popolazione di N = 200.

Ora disegniamo un campione casuale di N = 20 da questa popolazione (i punti rossi nel nostro precedente scatterplot). Anche se la nostra correlazione popolazione è pari a zero, abbiamo trovato un sconcertante 0.,82 correlazione nel nostro campione. La figura seguente illustra questo omettendo tutte le unità non campionate dal nostro scatterplot precedente.

Questo solleva la domanda su come possiamo mai dire qualcosa sulla nostra popolazione se ne abbiamo solo un piccolo campione. La risposta di base: raramente possiamo dire qualcosa con certezza al 100%. Tuttavia, possiamo dire molto con certezza 99%, 95% o 90%.
Probabilità
Quindi come funziona? Beh, in pratica, alcuni risultati del campione sono altamente improbabili data la nostra ipotesi nulla., In questo modo, la figura seguente mostra le probabilità per diverse correlazioni del campione (N = 100) se la correlazione della popolazione è davvero zero.

Un computer calcolerà prontamente queste probabilità. Tuttavia, ciò richiede una dimensione del campione (100 nel nostro caso) e una presunta correlazione di popolazione ρ (0 nel nostro caso). Ecco perché abbiamo bisogno di un’ipotesi nulla.
Se guardiamo attentamente questa distribuzione di campionamento, vediamo che le correlazioni del campione intorno a 0 sono più probabili: c’è una probabilità 0.68 di trovare una correlazione tra -0.1 e 0.1. Che significa?, Bene, ricorda che le probabilità possono essere viste come frequenze relative. Quindi immagina di disegnare 1.000 campioni invece di quello che abbiamo. Ciò comporterebbe 1.000 coefficienti di correlazione e alcuni 680 di questi-una frequenza relativa di 0,68-sarebbero nell’intervallo da -0,1 a 0,1. Allo stesso modo, c’è una probabilità di 0,95 (o 95%) di trovare una correlazione campione tra -0,2 e 0,2.
P-Values
Abbiamo trovato una correlazione campione di 0.25. Quanto è probabile che se la correlazione della popolazione è zero?, La risposta è nota come p-value (abbreviazione di probability value):Un p-value è la probabilità di trovare un risultato campione o uno più estremo se l’ipotesi nulla è vera.Data la nostra correlazione 0.25,” più estremo ” di solito significa più grande di 0.25 o più piccolo di -0.25. Non possiamo dire dal nostro grafico, ma la tabella sottostante ci dice che p ≈ 0.012. Se l’ipotesi nulla è vera, c’è una probabilità dell ‘ 1,2% di trovare la nostra correlazione campione.
Conclusione?
Se la nostra correlazione di popolazione è davvero zero, allora possiamo trovare una correlazione campione di 0,25 in un campione di N = 100., La probabilità che ciò accada è solo 0,012 quindi è molto improbabile. Una conclusione ragionevole è che la nostra correlazione di popolazione non era zero dopo tutto.
Conclusione: rifiutiamo l’ipotesi nulla. Dato il nostro risultato del campione, non crediamo più che la felicità e la ricchezza non siano correlate. Tuttavia, non possiamo ancora affermarlo con certezza.
Ipotesi nulla – Limitazioni
Finora, abbiamo solo concluso che la correlazione della popolazione non è probabilmente zero. Questa è l’unica conclusione del nostro approccio alle ipotesi nulle e non è poi così interessante.,
Quello che vogliamo veramente sapere è la correlazione della popolazione. La nostra correlazione campione di 0,25 sembra una stima ragionevole. Chiamiamo un numero così singolo una stima puntuale.
Ora, un nuovo campione può venire con una correlazione diversa. Una domanda interessante è quanto le nostre correlazioni di campioni fluttuerebbero sui campioni se ne disegnassimo molti. La figura seguente mostra esattamente questo, assumendo la nostra dimensione del campione di N = 100 e la nostra stima (punto) di 0.25 per la correlazione della popolazione.,

Intervalli di confidenza
Il nostro risultato del campione suggerisce che circa il 95% di molti campioni dovrebbe trovare una correlazione tra 0,06 e 0,43. Questo intervallo è noto come intervallo di confidenza. Anche se non è precisamente corretto, è più facilmente anche se la larghezza di banda che è probabile che racchiuda la correlazione della popolazione.
Una cosa da notare è che l’intervallo di concidenza è piuttosto ampio. Contiene quasi una correlazione zero, esattamente l’ipotesi nulla che abbiamo respinto in precedenza.,
Un’altra cosa da notare è che la nostra distribuzione di campionamento e l’intervallo di confidenza sono leggermente asimmetrici. Sono simmetrici per la maggior parte delle altre statistiche (come i coefficienti medi o beta) ma non le correlazioni.