Descrizione
- Precision e recall sono due cruciale ancora incompreso argomenti di apprendimento automatico
- vedremo quello precisione e recall sono, come funzionano, e il loro ruolo nella valutazione di una macchina modello di apprendimento
- Ci sarà anche acquisire una comprensione dell’Area Sotto la Curva (AUC) e la Precisione di termini
Introduzione
Chiedete a qualsiasi macchina di apprendimento professionale o dati scienziato su più confusi concetti nel loro percorso di apprendimento., E invariabilmente, la risposta vira verso la Precisione e il Richiamo.
La differenza tra precisione e Richiamo è in realtà facile da ricordare, ma solo una volta che hai veramente capito cosa significa ogni termine. Ma molto spesso, e posso attestarlo, gli esperti tendono ad offrire spiegazioni a metà forno che confondono ancora di più i nuovi arrivati.
Quindi cerchiamo di impostare le cose in chiaro in questo articolo.

Per qualsiasi modello di apprendimento automatico, sappiamo che ottenere una “buona vestibilità” sul modello è estremamente cruciale., Ciò comporta il raggiungimento dell’equilibrio tra underfitting e overfitting, o in altre parole, un compromesso tra bias e varianza.
Tuttavia, quando si tratta di classificazione, c’è un altro compromesso che viene spesso trascurato a favore del compromesso bias – variance. Questo è il compromesso di precisione-richiamo. Le classi squilibrate si verificano comunemente nei set di dati e quando si tratta di casi d’uso specifici, vorremmo infatti dare più importanza alle metriche di precisione e richiamo e anche a come raggiungere l’equilibrio tra loro.
Ma, come farlo?, Esploreremo le metriche di valutazione della classificazione concentrandosi sulla precisione e sul richiamo in questo articolo. Impareremo anche come calcolare queste metriche in Python prendendo un set di dati e un semplice algoritmo di classificazione. Quindi, iniziamo!
È possibile conoscere le metriche di valutazione in modo approfondito qui-Metriche di valutazione per i modelli di apprendimento automatico.
Sommario
- Comprendere l’istruzione del problema
- Che cos’è la precisione?
- Che cos’è il richiamo?,
- La valutazione più semplice Metrica – Precisione
- Il ruolo del F1-Score
- Il famoso Precision-Recall Compromesso
- Capire l’area sotto la curva (AUC)
Capire la dichiarazione problema
Credo fortemente nell’apprendimento facendo. Quindi, in questo articolo, parleremo in termini pratici-utilizzando un set di dati.
Prendiamo il popolare set di dati sulle malattie cardiache disponibile sul repository UCI. Qui, dobbiamo prevedere se il paziente soffre di un disturbo cardiaco o non utilizza il set di funzionalità specificato., È possibile scaricare il set di dati pulito da qui.
Poiché questo articolo si concentra esclusivamente sulle metriche di valutazione del modello, useremo il classificatore più semplice: il modello di classificazione kNN per fare previsioni.
Come sempre, partiamo da importare le librerie necessarie e pacchetti:
Quindi, cerchiamo di andare a guardare i dati e le variabili target abbiamo a che fare con:
Cerchiamo di verificare se abbiamo valori mancanti:
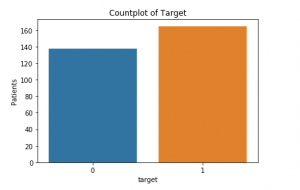
non Ci sono i valori mancanti., Ora possiamo dare un’occhiata a quanti pazienti sono effettivamente affetti da malattie cardiache (1) e quanti non lo sono (0):
Questo è il grafico di conteggio qui sotto:
Procediamo dividendo i nostri dati di allenamento e test e le nostre variabili di input e target. Dal momento che stiamo usando KNN, è obbligatorio scalare anche i nostri set di dati:
L’intuizione dietro la scelta del miglior valore di k è oltre lo scopo di questo articolo, ma dovremmo sapere che possiamo determinare il valore ottimale di k quando otteniamo il punteggio di test più alto per quel valore., Per questo, siamo in grado di valutare la formazione e test punteggi per un massimo di 20 vicini:
valutare il max punteggio di un test e la k valori ad essa associati, eseguire il seguente comando:

Così, abbiamo ottenuto il valore ottimale di k 3, 11, o 20 con un punteggio di 83.5. Finalizzeremo uno di questi valori e adatteremo il modello di conseguenza:

Ora, come valutiamo se questo modello è un modello “buono” o no?, Per questo, usiamo qualcosa chiamato Matrice di confusione:
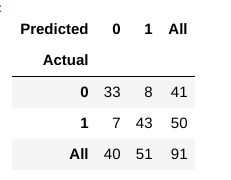
Una matrice di confusione ci aiuta a capire quanto siano corrette le nostre previsioni e come resistono ai valori reali.
Dal nostro treno e dai dati di test, sappiamo già che i nostri dati di test consistevano in 91 punti dati. Questo è il valore della 3a riga e della 3a colonna alla fine. Notiamo anche che ci sono alcuni valori effettivi e previsti. I valori effettivi sono il numero di punti dati che sono stati originariamente classificati in 0 o 1., I valori previsti sono il numero di punti dati che il nostro modello KNN prevede come 0 o 1.
I valori effettivi sono:
- I pazienti che in realtà non hanno una malattia cardiaca = 41
- I pazienti che in realtà hanno una malattia cardiaca = 50
I valori stimati sono:
- Numero di pazienti che erano previsti come non avere una malattia cardiaca = 40
- Numero di pazienti che erano previsti come avere una malattia cardiaca = 51
Tutti i valori otteniamo sopra hanno un termine., Andiamo su di loro uno per uno:
- I casi in cui i pazienti in realtà non hanno avuto malattie cardiache e il nostro modello anche previsto come non averlo è chiamato i veri Negativi. Per la nostra matrice, Veri negativi = 33.
- I casi in cui i pazienti hanno effettivamente malattie cardiache e il nostro modello ha anche predetto come averlo sono chiamati i veri positivi. Per la nostra matrice, True Positive = 43
- Tuttavia, ci sono alcuni casi in cui il paziente non ha effettivamente alcuna malattia cardiaca, ma il nostro modello ha previsto che lo facciano., Questo tipo di errore è l’errore di tipo I e chiamiamo i valori come Falsi positivi. Per la nostra matrice, Falsi positivi = 8
- Allo stesso modo, ci sono alcuni casi in cui il paziente ha effettivamente una malattia cardiaca, ma il nostro modello ha predetto che non lo fa. Questo tipo di errore è l’errore di tipo II e chiamiamo i valori come Falsi Negativi. Per la nostra matrice, Falsi negativi = 7
Che cos’è la precisione?
Destra – così ora veniamo al punto cruciale di questo articolo. Che cosa nel mondo è la precisione? E cosa c’entra tutto l’apprendimento di cui sopra?,
Nei termini più semplici, la precisione è il rapporto tra i Veri Positivi e tutti i Positivi. Per la nostra affermazione del problema, quella sarebbe la misura dei pazienti che identifichiamo correttamente avere una malattia cardiaca da tutti i pazienti che effettivamente ce l’hanno. Matematicamente:

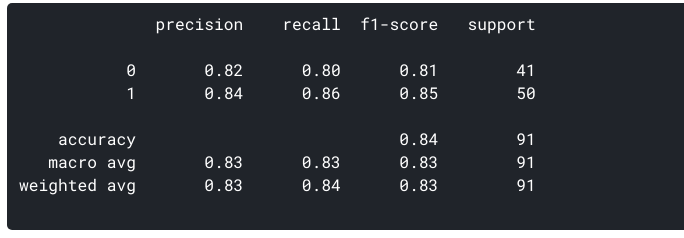
Qual è la precisione per il nostro modello? Sì, è 0,843 o, quando prevede che un paziente ha una malattia cardiaca, è corretto intorno all ‘ 84% delle volte.
La precisione ci fornisce anche una misura dei punti dati rilevanti., È importante che non iniziamo a trattare un paziente che in realtà non ha un disturbo cardiaco, ma il nostro modello prevede di averlo.
Che cos’è il richiamo?
Il richiamo è la misura del nostro modello che identifica correttamente i Veri Positivi. Pertanto, per tutti i pazienti che hanno effettivamente malattie cardiache, recall ci dice quanti abbiamo correttamente identificato come affetti da una malattia cardiaca. Matematicamente:

Per il nostro modello, Recall = 0.86. Recall fornisce anche una misura di quanto accuratamente il nostro modello è in grado di identificare i dati rilevanti., Ci riferiamo ad esso come Sensibilità o Vero tasso positivo. Che cosa succede se un paziente ha una malattia cardiaca, ma non c’è nessun trattamento dato a lui / lei perché il nostro modello previsto così? Questa è una situazione che vorremmo evitare!
La metrica più semplice da capire – Precisione
Ora veniamo a una delle metriche più semplici di tutti, la precisione. La precisione è il rapporto tra il numero totale di previsioni corrette e il numero totale di previsioni. Riesci a indovinare quale sarà la formula per la precisione?
![]()
Per il nostro modello, la precisione sarà = 0.835.,
Usare la precisione come metrica di definizione per il nostro modello ha senso intuitivamente, ma il più delle volte, è sempre consigliabile usare anche la precisione e il Richiamo. Potrebbero esserci altre situazioni in cui la nostra precisione è molto alta, ma la nostra precisione o richiamo è bassa. Idealmente, per il nostro modello, vorremmo evitare completamente tutte le situazioni in cui il paziente ha malattie cardiache, ma il nostro modello classifica come lui non averlo cioè, mirare ad un richiamo elevato.,
D’altra parte, per i casi in cui il paziente non è affetto da malattie cardiache e il nostro modello predice il contrario, vorremmo anche evitare di trattare un paziente senza malattie cardiache(cruciale quando i parametri di input potrebbero indicare un disturbo diverso, ma finiamo per curarlo per un disturbo cardiaco).
Anche se puntiamo ad alta precisione e ad alto valore di richiamo, non è possibile ottenere entrambi allo stesso tempo., Ad esempio, se cambiamo il modello in uno che ci dà un richiamo elevato, potremmo rilevare tutti i pazienti che hanno effettivamente malattie cardiache, ma potremmo finire per dare trattamenti a molti pazienti che non ne soffrono.
Allo stesso modo, se miriamo ad alta precisione per evitare di dare qualsiasi trattamento sbagliato e non richiesto, finiamo per ottenere un sacco di pazienti che hanno effettivamente una malattia cardiaca senza alcun trattamento.
Il ruolo del F1-Score
Comprensione precisione ci ha fatto capire, abbiamo bisogno di un compromesso tra precisione e richiamo., Dobbiamo prima decidere quale è più importante per il nostro problema di classificazione.
Ad esempio, per il nostro set di dati, possiamo considerare che ottenere un richiamo elevato è più importante di ottenere un’alta precisione – vorremmo rilevare il maggior numero possibile di pazienti cardiaci. Per alcuni altri modelli, come la classificazione se un cliente bancario è un inadempiente di prestito o no, è auspicabile avere un’alta precisione poiché la banca non vorrebbe perdere i clienti a cui è stato negato un prestito in base alla previsione del modello che sarebbero inadempienti.,
Ci sono anche molte situazioni in cui sia la precisione che il richiamo sono ugualmente importanti. Ad esempio, per il nostro modello, se il medico ci informa che i pazienti che sono stati erroneamente classificati come affetti da malattie cardiache sono ugualmente importanti poiché potrebbero essere indicativi di qualche altro disturbo, allora mireremmo non solo a un richiamo elevato ma anche a un’alta precisione.
In questi casi, usiamo qualcosa chiamato F1-score., F1-score è la media armonica della Precisione e del Richiamo:

Questo è più facile da lavorare poiché ora, invece di bilanciare precisione e richiamo, possiamo solo mirare a un buon punteggio F1 e questo sarebbe indicativo di una buona Precisione e di un buon valore di richiamo.,
Possiamo generare le metriche di cui sopra per il nostro set di dati usando anche sklearn:
Curva ROC
Insieme ai termini di cui sopra, ci sono più valori che possiamo calcolare dalla matrice di confusione:
- False Positive Rate (FPR): È il rapporto Positivi al numero effettivo di negativi. Nel contesto del nostro modello, è una misura per quanti casi ha fatto il modello prevede che il paziente ha una malattia di cuore da tutti i pazienti che in realtà non hanno avuto la malattia di cuore. Per i nostri dati, l’FPR è = 0.,195
- True Negative Rate (TNR) o la specificità: è il rapporto tra i veri negativi e il numero effettivo di negativi. Per il nostro modello, è la misura per quanti casi il modello ha predetto correttamente che il paziente non ha malattie cardiache da tutti i pazienti che in realtà non hanno avuto malattie cardiache. Il TNR per i dati di cui sopra = 0.804. Da queste 2 definizioni, possiamo anche concludere che Specificity o TNR = 1-FPR
Possiamo anche visualizzare la precisione e Richiamare usando curve ROC e curve PRC.,
Curve ROC (curva caratteristica di funzionamento del ricevitore):
È la trama tra il TPR(asse y) e FPR(asse x). Poiché il nostro modello classifica il paziente come cardiopatico o meno in base alle probabilità generate per ogni classe, possiamo decidere anche la soglia delle probabilità.
Ad esempio, vogliamo impostare un valore di soglia di 0.4. Ciò significa che il modello classificherà il datapoint/paziente come affetto da malattia cardiaca se la probabilità che il paziente abbia una malattia cardiaca è maggiore di 0,4., Ciò ovviamente darà un valore di richiamo elevato e ridurrà il numero di falsi positivi. Allo stesso modo, possiamo visualizzare come il nostro modello esegue per diversi valori di soglia utilizzando la curva ROC.
Generiamo una curva ROC per il nostro modello con k = 3.
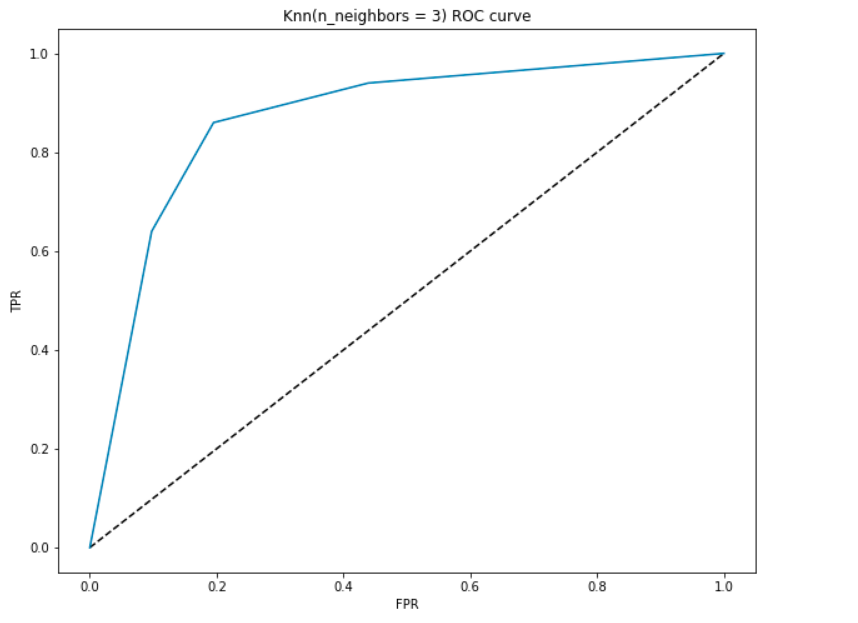
Interpretazione AUC-
- Nel punto più basso, cioè a (0, 0)- la soglia è impostata su 1.0. Questo significa che il nostro modello classifica tutti i pazienti come non avere una malattia cardiaca.
- Nel punto più alto, cioè a (1, 1), la soglia è impostata su 0.0., Ciò significa che il nostro modello classifica tutti i pazienti come affetti da una malattia cardiaca.
- Il resto della curva è costituito dai valori di FPR e TPR per i valori di soglia compresi tra 0 e 1. Ad un certo valore di soglia, osserviamo che per FPR vicino a 0, stiamo raggiungendo un TPR vicino a 1. Questo è quando il modello predirà i pazienti che hanno malattie cardiache quasi perfettamente.
- L’area con la curva e gli assi come confini è chiamata Area Sotto Curva(AUC). È questa area che è considerata come una metrica di un buon modello., Con questa metrica che va da 0 a 1, dovremmo puntare ad un alto valore di AUC. I modelli con un’alta AUC sono chiamati come modelli con buona abilità. Calcoliamo il punteggio AUC del nostro modello e la trama sopra:

- Otteniamo un valore di 0.868 come AUC che è un punteggio abbastanza buono! In termini più semplici, questo significa che il modello sarà in grado di distinguere i pazienti con malattie cardiache e quelli che non lo fanno l ‘ 87% delle volte. Possiamo migliorare questo punteggio e ti esorto a provare diversi valori di iperparametro.,
- La linea diagonale è un modello casuale con un’AUC di 0,5, un modello senza abilità, che equivale a fare una previsione casuale. Riesci a indovinare perché?
Precision-Recall Curve (PRC)
Come suggerisce il nome, questa curva è una rappresentazione diretta della precisione(asse y) e del richiamo(asse x). Se osservi le nostre definizioni e formule per la Precisione e il Richiamo sopra, noterai che in nessun momento stiamo usando i veri Negativi(il numero effettivo di persone che non hanno malattie cardiache).,
Questo è particolarmente utile per le situazioni in cui abbiamo un set di dati squilibrato e il numero di negativi è molto più grande dei positivi(o quando il numero di pazienti che non hanno malattie cardiache è molto più grande dei pazienti che lo hanno). In questi casi, la nostra maggiore preoccupazione sarebbe rilevare i pazienti con malattie cardiache nel modo più corretto possibile e non avrebbe bisogno del TNR.
Come il ROC, tracciamo la precisione e richiamiamo per diversi valori di soglia:
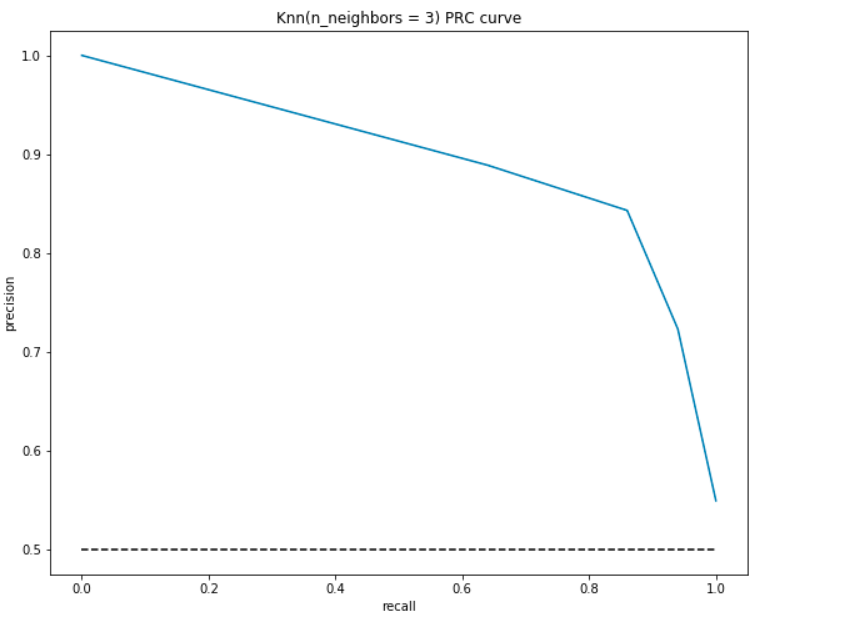
Interpretazione PRC:
- Nel punto più basso, cioè, at (0, 0) – la soglia è impostata su 1.0. Ciò significa che il nostro modello non fa distinzioni tra i pazienti che hanno malattie cardiache e i pazienti che non lo fanno.
- Nel punto più alto cioè a (1, 1), la soglia è impostata su 0.0. Ciò significa che sia la nostra precisione che il richiamo sono alti e il modello fa distinzioni perfettamente.
- Il resto della curva sono i valori di Precisione e Richiamo per i valori di soglia compresi tra 0 e 1. Il nostro obiettivo è quello di rendere la curva il più vicino possibile a (1, 1) – il che significa una buona precisione e richiamo.,
- Simile a ROC, l’area con la curva e gli assi come confini è l’Area sotto la curva(AUC). Considera questa area come una metrica di un buon modello. L ‘ AUC varia da 0 a 1. Pertanto, dovremmo mirare a un alto valore di AUC. Calcoliamo l’AUC per il nostro modello e la trama precedente:

Come prima, otteniamo una buona AUC di circa il 90%. Inoltre, il modello può ottenere un’elevata precisione con il richiamo come 0 e raggiungerebbe un richiamo elevato compromettendo la precisione del 50%.,
Note finali
Per concludere, in questo articolo, abbiamo visto come valutare un modello di classificazione, concentrandosi in particolare sulla precisione e il richiamo, e trovare un equilibrio tra loro. Inoltre, spieghiamo come rappresentare le prestazioni del nostro modello utilizzando metriche diverse e una matrice di confusione.
Ecco un articolo aggiuntivo per comprendere le metriche di valutazione – 11 Importanti metriche di valutazione del modello per l’apprendimento automatico Che tutti dovrebbero sapere