Overzicht
- Precisie en recall zijn twee cruciale maar verkeerd begrepen onderwerpen in machine learning
- We bespreken wat precisie en recall zijn, hoe ze werken, en hun rol in de evaluatie van een machine learning model
- We ook een beeld krijgen van het oppervlak Onder de Curve (AUC) en Juistheid voorwaarden
Inleiding
Vraag een willekeurige machine learning professional of gegevens wetenschapper over de meest verwarrende begrippen in hun leertraject., En steevast draait het antwoord op precisie en Terugroepactiviteit.
het verschil tussen precisie en Recall is eigenlijk gemakkelijk te onthouden – maar alleen als je echt hebt begrepen waar elke term voor staat. Maar heel vaak, en ik kan dit bevestigen, deskundigen hebben de neiging om halfbakken verklaringen die nieuwkomers nog meer verwarren.
dus laten we het recht zetten in dit artikel.

voor elk machine learning model, weten we dat het bereiken van een ‘goede pasvorm’ op het model uiterst cruciaal is., Dit houdt in dat er een evenwicht moet worden gevonden tussen onder-en overbevissing, of met andere woorden, een afweging tussen vooringenomenheid en variantie.
echter, als het gaat om classificatie – er is een andere afweging die vaak over het hoofd wordt gezien ten gunste van de afweging voor vooringenomenheid en variantie. Dit is de Precision-recall ruil. Onevenwichtige klassen komen vaak voor in datasets en als het gaat om specifieke use cases, zouden we in feite meer belang willen geven aan de precisie en recall metrics, en ook hoe de balans tussen hen te bereiken.
maar hoe doe je dat?, We zullen de classificatie evaluatie metrics verkennen door zich te concentreren op precisie en recall in dit artikel. We zullen ook leren hoe we deze metrics in Python kunnen berekenen door een dataset en een eenvoudig classificatiealgoritme te nemen. Dus, laten we beginnen!
u kunt hier meer te weten komen over de evaluatie metrics-evaluatie Metrics voor Machine Learning modellen.
inhoudsopgave
- inzicht in de probleemstelling
- Wat is precisie?
- Wat is terugroepen?,
- De gemakkelijkste evaluatie Metric-Accuracy
- de rol van de F1-Score
- de beroemde Precision-Recall Tradeoff
- inzicht in het gebied onder de Curve (AUC)
inzicht in de probleemstelling
ik geloof sterk in leren door te doen. Dus in dit artikel, zullen we praten in praktische termen – door het gebruik van een dataset.
laten we de populaire Dataset voor hartziekten die beschikbaar is in de UCI-repository gebruiken. Hier moeten we voorspellen of de patiënt lijdt aan een hartkwaal of niet met behulp van de gegeven set van functies., U kunt de schone dataset hier downloaden.
aangezien dit artikel zich uitsluitend richt op model evaluatie metrics, zullen we de eenvoudigste classifier gebruiken – het KNN Classificatiemodel om voorspellingen te doen.
Zoals altijd, zullen we beginnen met het importeren van de nodige bibliotheken en pakketten:
laat ons Dan eens een kijkje op de data en de doelvariabelen hebben we te maken met:
Laten we controleren of we de ontbrekende waarden:
Er zijn geen ontbrekende waarden., Nu kunnen we kijken hoeveel patiënten daadwerkelijk lijden aan hartziekte (1) en hoeveel Niet (0):
Dit is de telling hieronder:
laten we verder gaan door onze training-en testgegevens en onze input-en doelvariabelen te splitsen. Omdat we KNN gebruiken, is het ook verplicht om onze datasets te schalen:
de intuïtie achter het kiezen van de beste waarde van k valt buiten het bereik van dit artikel, maar we moeten weten dat we de optimale waarde van k kunnen bepalen wanneer we de hoogste testscore voor die waarde krijgen., Hiervoor kunnen we de trainings-en testscores evalueren voor maximaal 20 naaste buren:
om de max testscore en de k-waarden te evalueren, voer je het volgende commando uit:

daarom hebben we de optimale waarde van k verkregen van 3, 11 of 20 met een score van 83,5. We zullen een van deze waarden afronden en het model dienovereenkomstig aanpassen:

nu, hoe evalueren we of dit model een ‘goed’ model is of niet?, Hiervoor gebruiken we iets dat een Verwarmingsmatrix wordt genoemd:
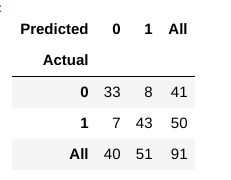
een verwarmingsmatrix helpt ons inzicht te krijgen in hoe juist onze voorspellingen waren en hoe ze tegen de werkelijke waarden staan.
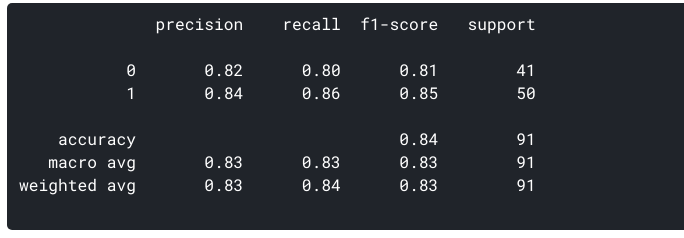
uit onze trein-en testgegevens weten we al dat onze testgegevens uit 91 datapunten bestonden. Dat is de waarde van de 3e rij en 3e kolom aan het einde. We merken ook dat er een aantal actuele en voorspelde waarden. De werkelijke waarden zijn het aantal datapunten dat oorspronkelijk werd gecategoriseerd in 0 of 1., De voorspelde waarden zijn het aantal datapunten dat ons KNN-model voorspelde als 0 of 1.
de werkelijke waarden zijn:
- de patiënten die daadwerkelijk geen hartziekte hebben = 41
- de patiënten die daadwerkelijk wel een hartziekte hebben = 50
de voorspelde waarden zijn:
- aantal patiënten waarvan werd voorspeld dat ze geen hartziekte hadden = 40
- aantal patiënten waarvan werd voorspeld dat ze een hartziekte hadden = 51
alle bovenstaande waarden hebben een term., Laten we ze één voor één doornemen:
- de gevallen waarin de patiënten geen hartziekte hadden en Ons model voorspelde ook dat ze geen hartziekte hadden, worden de echte negatieven genoemd. Voor onze matrix, ware negatieven = 33.
- de gevallen waarin de patiënten daadwerkelijk hartziekte hebben en Ons model voorspelde ook dat ze een hartziekte hadden, worden de echte positieven genoemd. Voor onze matrix, True positieven = 43
- Er zijn echter enkele gevallen waarin de patiënt eigenlijk geen hartziekte heeft, maar ons model heeft voorspeld dat ze dat wel doen., Dit soort fout is de Type I fout en we noemen de waarden False positieven. Voor onze matrix, False positieven = 8
- evenzo zijn er enkele gevallen waarin de patiënt daadwerkelijk hartziekte heeft, maar ons model heeft voorspeld dat hij/zij dat niet heeft. dit soort fout is de Type II fout en we noemen de waarden False negatieven. Voor onze matrix, False negatieven = 7
Wat is precisie?
rechts – dus nu komen we bij de kern van dit artikel. Wat in de wereld is precisie? En wat heeft al het bovenstaande leren ermee te maken?,
in de eenvoudigste termen is precisie de verhouding tussen de echte positieven en alle positieven. Voor onze probleemstelling zou dat de maat zijn van patiënten die we correct identificeren met een hartziekte van alle patiënten die het daadwerkelijk hebben. Wiskundig:

Wat is de precisie voor ons model? Ja, het is 0,843 of, wanneer het voorspelt dat een patiënt hart-en vaatziekten heeft, is het correct ongeveer 84% van de tijd.
precisie geeft ons ook een maat van de relevante gegevenspunten., Het is belangrijk dat we niet beginnen met het behandelen van een patiënt die eigenlijk geen hartkwaal heeft, maar ons model voorspelde dat het wel zo is.
Wat is terugroepen?
De recall is de maat van ons model dat correct waar-positieven identificeert. Dus, voor alle patiënten die daadwerkelijk hart-en vaatziekten, recall vertelt ons hoeveel we correct geïdentificeerd als het hebben van een hart-en vaatziekten. Mathematisch:

Voor Ons model, Recall = 0,86. Recall geeft ook een maat van hoe nauwkeurig Ons model in staat is om de relevante gegevens te identificeren., We noemen het Gevoeligheid of Ware positieve snelheid. Wat als een patiënt een hartziekte heeft, maar er geen behandeling wordt gegeven aan hem/haar omdat ons model dat voorspelde? Dat is een situatie die we willen vermijden!
de makkelijkste maatstaf om te begrijpen – nauwkeurigheid
nu komen we bij een van de eenvoudigste maatstaven van allemaal, nauwkeurigheid. Nauwkeurigheid is de verhouding tussen het totale aantal correcte voorspellingen en het totale aantal voorspellingen. Kun je raden wat de formule voor nauwkeurigheid zal zijn?
![]()
Voor Ons model is de nauwkeurigheid = 0,835.,
het gebruik van nauwkeurigheid als definiërende maatstaf voor ons model is intuïtief zinvol, maar vaker wel dan niet, is het altijd raadzaam om ook precisie en herinnering te gebruiken. Er kunnen andere situaties zijn waarin onze nauwkeurigheid zeer hoog is, maar onze precisie of terugroepactiviteit is laag. Idealiter zouden we voor ons model situaties willen vermijden waarin de patiënt een hartziekte heeft, maar ons model classificeert als hij het niet heeft, dat wil zeggen, streven naar een hoge recall.,
aan de andere kant, voor de gevallen waarin de patiënt geen hartziekte heeft en Ons model het tegenovergestelde voorspelt, willen we ook vermijden een patiënt zonder hartziekten te behandelen(cruciaal wanneer de inputparameters een andere kwaal kunnen aangeven, maar we hem/haar uiteindelijk behandelen voor een hartkwaal).
hoewel we streven naar hoge precisie en hoge terugroepactiviteit, is het niet mogelijk beide tegelijkertijd te bereiken., Bijvoorbeeld, als we het model veranderen in een model dat ons een hoge recall geeft, kunnen we alle patiënten detecteren die hartziekte hebben, maar we kunnen uiteindelijk behandelingen geven aan veel patiënten die er geen last van hebben.
Evenzo, als we streven naar een hoge precisie om te voorkomen dat het geven van een verkeerde en niet-gewenste behandeling, we uiteindelijk krijgen een heleboel patiënten die daadwerkelijk hebben een hart-en vaatziekten gaan zonder enige behandeling.
de rol van de F1-Score
het begrijpen van nauwkeurigheid deed ons beseffen dat we een afweging nodig hebben tussen precisie en Recall., We moeten eerst beslissen wat belangrijker is voor ons classificatieprobleem.
voor onze dataset kunnen we bijvoorbeeld van mening zijn dat het bereiken van een hoge recall belangrijker is dan het verkrijgen van een hoge precisie – we willen graag zoveel mogelijk hartpatiënten detecteren. Voor sommige andere modellen, zoals het classificeren of een bank klant is een lening wanbetaler of niet, is het wenselijk om een hoge precisie te hebben, omdat de bank niet zou willen verliezen klanten die een lening werd geweigerd op basis van de voorspelling van het model dat ze zouden wanbetalers.,
Er zijn ook veel situaties waarin zowel precisie als recall even belangrijk zijn. Bijvoorbeeld, voor ons model, als de arts ons informeert dat de patiënten die ten onrechte werden geclassificeerd als lijden aan hart-en vaatziekten zijn even belangrijk omdat ze kunnen wijzen op een andere kwaal, dan zouden we streven naar niet alleen een hoge recall, maar een hoge precisie ook.
in dergelijke gevallen gebruiken we iets dat F1-score wordt genoemd., F1-score is het harmonische gemiddelde van de precisie en Recall:

Dit is gemakkelijker om mee te werken omdat we nu, in plaats van het balanceren van precisie en recall, gewoon kunnen streven naar een goede F1-score en dat zou een indicatie zijn van een goede precisie en een goede Recall waarde.,
We kunnen de bovenstaande statistieken voor onze dataset ook genereren met behulp van sklearn:
ROC Curve
samen met de bovenstaande termen zijn er meer waarden die we kunnen berekenen uit de verwarmingsmatrix:
- False Positive Rate (FPR): het is de verhouding van de False positieven tot het werkelijke aantal negatieven. In de context van ons model is het een maat voor hoeveel gevallen voorspelde het model dat de patiënt een hartziekte heeft van alle patiënten die de hartziekte niet hadden. Voor onze gegevens is de FPR = 0.,195
- True Negative Rate (TNR) of de specificiteit: het is de verhouding tussen de True negatieven en het werkelijke aantal negatieven. Voor ons model is het de maat voor hoeveel gevallen het model correct voorspelde dat de patiënt geen hartziekte heeft van alle patiënten die daadwerkelijk geen hartziekte hadden. De TNR voor bovenstaande gegevens = 0,804. Uit deze 2 Definities kunnen we ook concluderen dat specificiteit of TNR = 1 – FPR
We ook precisie kunnen visualiseren en herinneren met behulp van ROC-curves en PRC-curves.,
ROC Curves(Receiver Operating Characteristic Curve):
Het is de plot tussen de TPR(y-as) en FPR (x-as). Aangezien Ons model de patiënt classificeert als hartziekte of niet op basis van de kansen gegenereerd voor elke klasse, kunnen we ook de drempel van de waarschijnlijkheden bepalen.
bijvoorbeeld, we willen een drempelwaarde instellen van 0.4. Dit betekent dat het model het datapoint/patiënt classificeert als hartziekte als de kans dat de patiënt een hartziekte heeft groter is dan 0,4., Dit zal uiteraard een hoge recall waarde geven en het aantal valse positieven verminderen. Op dezelfde manier kunnen we visualiseren hoe ons model presteert voor verschillende drempelwaarden met behulp van de ROC-curve.
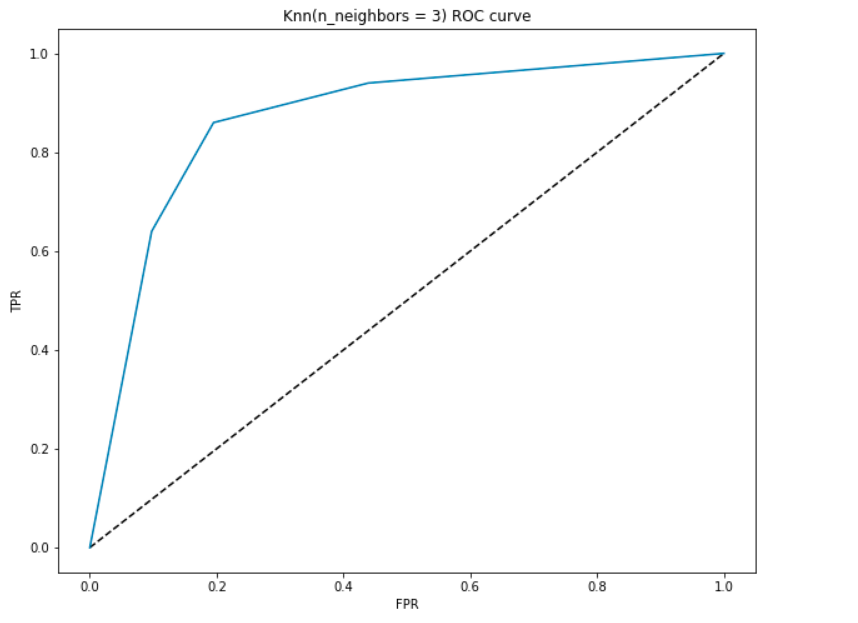
laten we een ROC-curve genereren voor ons model met k = 3.
AUC-interpretatie –
- op het laagste punt, d.w.z. op (0, 0) – de drempelwaarde is ingesteld op 1,0. Dit betekent dat ons model alle patiënten classificeert als patiënten die geen hartziekte hebben.
- op het hoogste punt, d.w.z. op (1, 1), wordt de drempelwaarde vastgesteld op 0,0., Dit betekent dat ons model alle patiënten classificeert als hart-en vaatziekten.
- de rest van de curve is de waarden van FPR en TPR voor de drempelwaarden tussen 0 en 1. Bij een bepaalde drempelwaarde zien we dat we voor FPR dicht bij 0 een TPR van dicht bij 1 bereiken. Dit is wanneer het model zal voorspellen de patiënten met hart-en vaatziekten bijna perfect.
- het gebied met de kromme en de assen als de grenzen wordt het gebied onder de Kromme(AUC) genoemd. Het is dit gebied dat wordt beschouwd als een metriek van een goed model., Met deze metriek variërend van 0 tot 1, moeten we streven naar een hoge waarde van AUC. Modellen met een hoge AUC worden genoemd als modellen met goede vaardigheid. Laten we de AUC score van ons model en de bovenstaande plot berekenen:

- We krijgen een waarde van 0,868 als de AUC die een vrij goede score is! In eenvoudige termen betekent dit dat het model in staat zal zijn om de patiënten met hart-en vaatziekten te onderscheiden en degenen die dat niet 87% van de tijd. We kunnen deze score verbeteren en ik dring er bij u proberen verschillende hyperparameter waarden.,
- de diagonale lijn is een willekeurig model met een AUC van 0,5, een model zonder vaardigheid, dat hetzelfde is als het maken van een willekeurige voorspelling. Kun je raden waarom?
Precision-Recall Curve(PRC)
zoals de naam al doet vermoeden, is deze curve een directe weergave van de precisie(y-as) en de recall (x-as). Als u onze definities en formules voor de precisie en herinnering hierboven in acht neemt, zult u merken dat we op geen enkel moment de echte negatieven gebruiken(het werkelijke aantal mensen dat geen hart-en vaatziekten heeft).,
Dit is vooral nuttig voor situaties waarin we een onevenwichtige dataset hebben en het aantal negatieven veel groter is dan de positieven(of wanneer het aantal patiënten zonder hartziekte veel groter is dan de patiënten die het hebben). In dergelijke gevallen zou onze grootste zorg zijn om de patiënten met hartziekten zo correct mogelijk op te sporen en zou de TNR niet nodig hebben.
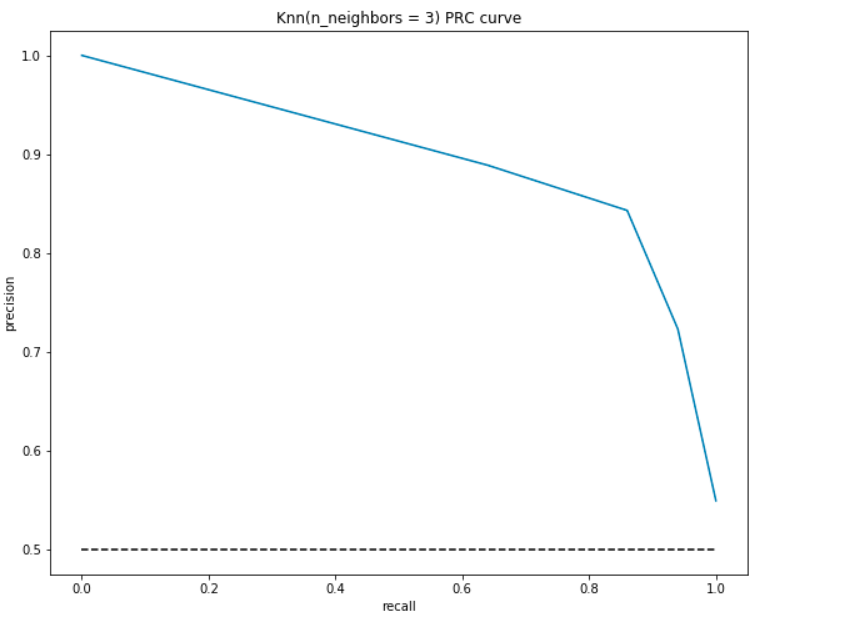
net als de ROC zetten we de precisie en terugroeping uit voor verschillende drempelwaarden:
interpretatie van de VRC:
- op het laagste punt, d.w.z., op (0, 0) – de drempelwaarde is ingesteld op 1.0. Dit betekent dat ons model geen onderscheid maakt tussen de patiënten die een hartaandoening hebben en de patiënten die dat niet hebben.
- op het hoogste punt, dat wil zeggen op (1, 1), wordt de drempelwaarde ingesteld op 0,0. Dit betekent dat zowel onze precisie als recall hoog zijn en dat het model perfect onderscheid maakt.
- de rest van de curve is de precisie-en Terugroepwaarden voor de drempelwaarden tussen 0 en 1. Ons doel is om de curve zo dicht mogelijk bij (1, 1) te maken – wat een goede precisie en terugroeping betekent.,
- net als ROC is het gebied met de kromme en de assen als grenzen het gebied onder de Kromme(AUC). Beschouw dit gebied als een metriek van een goed model. De AUC varieert van 0 tot 1. Daarom moeten we streven naar een hoge waarde van AUC. Laten we de AUC voor ons model en de bovenstaande plot berekenen:

zoals voorheen krijgen we een goede AUC van ongeveer 90%. Ook kan het model hoge precisie bereiken met recall als 0 en zou een hoge recall bereiken door de precisie van 50% in gevaar te brengen.,
End Notes
om te concluderen, in dit artikel, zagen we hoe een Classificatiemodel te evalueren, met name gericht op precisie en recall, en een balans tussen hen te vinden. Ook leggen we uit hoe we onze modelprestaties kunnen weergeven met behulp van verschillende metrics en een verwarmingsmatrix.
Hier is een aanvullend artikel voor u om evaluatie metrics te begrijpen – 11 belangrijke Model evaluatie Metrics voor Machine Learning iedereen zou moeten weten