översikt
- Precision och återkallelse är två avgörande men missförstådda ämnen i maskininlärning
- vi diskuterar vad precision och återkallelse är, hur de fungerar och deras roll vid utvärdering av en maskininlärningsmodell
- vi får också en förståelse för området under kurvan (AUC) och Noggrannhetstermer
introduktion
fråga alla maskininlärningsprofessionärer.eller Dataforskare om de mest förvirrande begreppen i sin inlärningsresa., Och alltid, svaret veers mot Precision och återkallelse.
skillnaden mellan Precision och återkallelse är faktiskt lätt att komma ihåg – men bara när du verkligen har förstått vad varje term står för. Men ganska ofta, och jag kan intyga detta, tenderar experter att erbjuda halvbakade förklaringar som förvirrar nykomlingar ännu mer.
så låt oss ställa in posten rakt i den här artikeln.

för alla maskininlärningsmodeller vet vi att det är oerhört viktigt att uppnå en ”bra passform” på modellen., Detta innebär att man uppnår balansen mellan underfitting och överfitting, eller med andra ord en avvägning mellan bias och varians.
men när det gäller klassificering – det finns en annan tradeoff som ofta förbises till förmån för bias-varians tradeoff. Det här är precisionsåterkallningstraden. Obalanserade klasser förekommer vanligen i datauppsättningar och när det gäller specifika användningsfall vill vi faktiskt ge mer betydelse för precisions-och återkallelsemätningarna och också hur man uppnår balansen mellan dem.
men hur gör man det?, Vi kommer att undersöka klassificeringsvärderingsmätvärden genom att fokusera på precision och återkallelse i den här artikeln. Vi kommer också att lära oss hur man beräknar dessa mätvärden i Python genom att ta en datauppsättning och en enkel klassificeringsalgoritm. Så, låt oss börja!
Du kan lära dig mer om utvärderingsmått ingående här-Utvärderingsmått för maskininlärningsmodeller.
Innehållsförteckning
- förstå problemet uttalande
- Vad är Precision?
- Vad är återkallelse?,
- Det enklaste mätvärdet – noggrannhet
- F1-Score Roll
- den berömda Precision-Recall Tradeoff
- förstå området under kurvan (AUC)
förstå problemet uttalande
Jag tror starkt på att lära genom att göra. Så i hela denna artikel kommer vi att prata i praktiska termer-genom att använda en datauppsättning.
låt oss ta upp den populära Hjärtsjukdomsdatauppsättningen som finns tillgänglig på UCI-arkivet. Här måste vi förutsäga om patienten lider av hjärtsjukdom eller inte använder den givna uppsättningen funktioner., Du kan ladda ner clean dataset härifrån.
eftersom den här artikeln enbart fokuserar på mätvärden för modellutvärdering kommer vi att använda den enklaste klassificeraren – kNN-klassificeringsmodellen för att göra förutsägelser.
som alltid ska vi börja med att importera nödvändiga bibliotek och paket:
låt oss sedan ta en titt på data och målvariabler vi har att göra med:
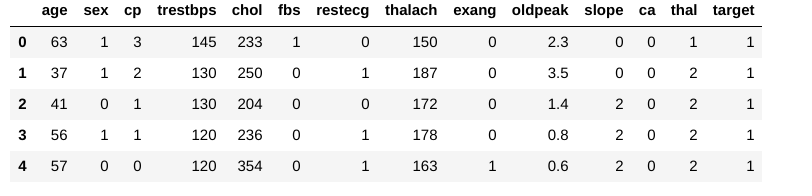
låt oss kontrollera om vi har saknade värden:
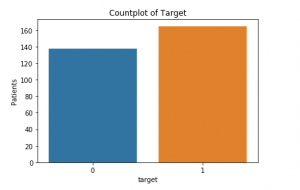
det saknas värden., Nu kan vi ta en titt på hur många patienter som faktiskt lider av hjärtsjukdom (1) och hur många som inte är (0):
detta är räkneplotten nedan:
låt oss fortsätta genom att dela upp våra utbildnings-och testdata och våra inmatnings-och målvariabler. Eftersom vi använder KNN är det obligatoriskt att skala våra datauppsättningar också:
intuitionen bakom att välja det bästa värdet av k ligger utanför tillämpningsområdet för den här artikeln, men vi borde veta att vi kan bestämma det optimala värdet av k när vi får det högsta testresultatet för det värdet., För det kan vi utvärdera tränings-och testresultatet för upp till 20 närmaste grannar:
för att utvärdera max testresultatet och k-värdena i samband med det, kör följande kommando:

Således har vi fått det optimala värdet av k att vara 3, 11 eller 20 med en poäng på 83.5. Vi kommer att slutföra ett av dessa värden och passa modellen i enlighet därmed:

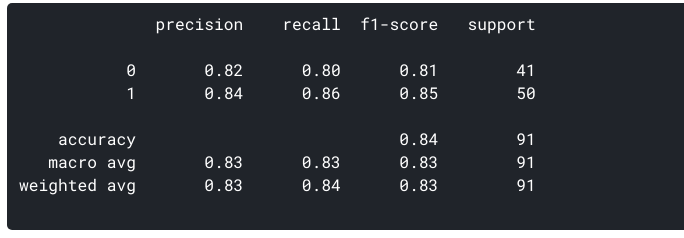
nu, hur utvärderar vi om den här modellen är en ” bra ” modell eller inte?, För det använder vi något som kallas en Förvirringsmatris:
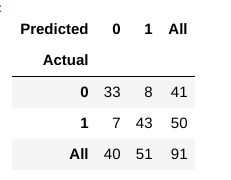
en förvirringsmatris hjälper oss att få en inblick i hur korrekta våra förutsägelser var och hur de håller upp mot de faktiska värdena.
från våra tåg-och testdata vet vi redan att våra testdata bestod av 91 datapunkter. Det är 3: e raden och 3: e kolumnvärdet i slutet. Vi märker också att det finns några faktiska och förutspådda värden. De faktiska värdena är antalet datapunkter som ursprungligen kategoriserades i 0 eller 1., De förväntade värdena är antalet datapunkter våra KNN modellen förutspådde som 0 eller 1.
de faktiska värdena är:
- de patienter som faktiskt inte har någon hjärtsjukdom = 41
- de patienter som faktiskt har en hjärtsjukdom = 50
de förväntade värdena är:
- antal patienter som förutspåddes inte ha någon hjärtsjukdom = 40
- antal patienter som förutspåddes ha en hjärtsjukdom = 51
alla värden är:
vi får ovan har en term., Låt oss gå över dem en efter en:
- de fall där patienterna faktiskt inte hade hjärtsjukdom och vår modell förutspådde också att de inte hade det kallas de sanna negativen. För vår matris, sanna negativ = 33.
- de fall där patienterna faktiskt har hjärtsjukdom och vår modell förutspådde också att ha det kallas de sanna positiva. För vår matris, sanna positiva = 43
- Det finns dock vissa fall där patienten faktiskt inte har någon hjärtsjukdom, men vår modell har förutspått att de gör det., Denna typ av fel är typ I-felet och vi kallar värdena som falska positiva. För vår matris, falska positiva = 8
- på samma sätt finns det några fall där patienten faktiskt har hjärtsjukdom, men vår modell har förutspått att han/hon inte gör det. denna typ av fel är typ II-felet och vi kallar värdena som falska negativ. För vår matris, False Negatives = 7
Vad är Precision?
höger – så nu kommer vi till kärnan i den här artikeln. Vad i hela världen är Precision? Och vad har allt ovanstående lärande att göra med det?,
i de enklaste termerna är Precision förhållandet mellan de sanna positiva och alla positiva. För vårt problem uttalande, det skulle vara mått på patienter som vi korrekt identifiera att ha en hjärtsjukdom av alla patienter som faktiskt har det. Matematiskt:

vad är precisionen för vår modell? Ja, det är 0,843 eller, när det förutspår att en patient har hjärtsjukdom, är det korrekt runt 84% av tiden.
Precision ger oss också ett mått på relevanta datapunkter., Det är viktigt att vi inte börjar behandla en patient som faktiskt inte har en hjärtsjukdom, men vår modell förutspådde att ha den.
Vad är Recall?
återkallelsen är måttet på vår modell som korrekt identifierar sanna positiva. Således, för alla patienter som faktiskt har hjärtsjukdom, berättar recall oss hur många vi korrekt identifierade som har hjärtsjukdom. Matematiskt:

För vår modell, Recall = 0.86. Recall ger också ett mått på hur exakt vår modell kan identifiera relevanta data., Vi hänvisar till det som känslighet eller sann positiv takt. Vad händer om en patient har hjärtsjukdom, men det finns ingen behandling som ges till honom / henne eftersom vår modell förutspådde det? Det är en situation som vi skulle vilja undvika!
det enklaste mätvärdet att förstå – noggrannhet
nu kommer vi till en av de enklaste mätvärdena för alla, noggrannhet. Noggrannhet är förhållandet mellan det totala antalet korrekta förutsägelser och det totala antalet förutsägelser. Kan du gissa vad formeln för noggrannhet kommer att vara?
![]()
För vår modell kommer noggrannheten att vara = 0,835.,
att använda noggrannhet som ett definierande mått för vår modell är vettigt intuitivt, men oftare är det alltid lämpligt att använda Precision och återkallelse också. Det kan finnas andra situationer där vår noggrannhet är mycket hög, men vår precision eller återkallelse är låg. Helst, för vår modell, vill vi helt undvika situationer där patienten har hjärtsjukdom, men vår modell klassificerar som honom inte har det dvs sträva efter hög återkallelse.,
å andra sidan, för de fall där patienten inte lider av hjärtsjukdom och vår modell förutspår motsatsen, vill vi också undvika att behandla en patient utan hjärtsjukdomar (avgörande när ingångsparametrarna kan indikera en annan sjukdom, men vi slutar behandla honom/henne för hjärtsjukdom).
även om vi strävar efter hög precision och högt återkallningsvärde är det inte möjligt att uppnå båda samtidigt., Om vi till exempel ändrar modellen till en som ger oss en hög återkallelse, kanske vi upptäcker alla patienter som faktiskt har hjärtsjukdom, men vi kan sluta ge behandlingar till många patienter som inte lider av det.
På samma sätt, om vi strävar efter hög precision för att undvika att ge fel och obesvarad behandling, slutar vi få många patienter som faktiskt har hjärtsjukdom utan behandling.
F1-Score
förståelse noggrannhet fick oss att inse, vi behöver en avvägning mellan Precision och återkallelse., Vi måste först bestämma vilket som är viktigare för vårt klassificeringsproblem.
för vår dataset kan vi till exempel överväga att uppnå en hög återkallelse är viktigare än att få en hög precision – vi skulle vilja upptäcka så många hjärtpatienter som möjligt. För vissa andra modeller, som att klassificera om en bankkund är ett lån defaulter eller inte, är det önskvärt att ha en hög precision eftersom banken inte skulle vilja förlora kunder som nekades ett lån baserat på modellens förutsägelse att de skulle vara defaulters.,
det finns också många situationer där både precision och återkallelse är lika viktiga. Till exempel, för vår modell, om läkaren informerar oss om att de patienter som felaktigt klassificerats som lider av hjärtsjukdom är lika viktiga eftersom de kan vara vägledande för någon annan sjukdom, då skulle vi sträva efter inte bara en hög återkallelse utan också en hög precision.
i sådana fall använder vi något som heter F1-score., F1-score är det harmoniska medelvärdet av precisionen och återkallandet:

det här är lättare att arbeta med Sedan nu, istället för att balansera precision och återkallelse, kan vi bara sträva efter en bra F1-poäng och det skulle också vara ett tecken på en bra Precision och ett bra Återkallningsvärde.,
vi kan generera ovanstående mätvärden för vår datauppsättning med hjälp av sklearn too:
Roc Curve
tillsammans med ovanstående termer finns det fler värden som vi kan beräkna från förvirringsmatrisen:
- False Positive Rate( FPR): det är förhållandet mellan de falska positiva och det faktiska antalet negativ. I samband med vår modell är det ett mått på hur många fall förutspår modellen att patienten har en hjärtsjukdom från alla patienter som faktiskt inte hade hjärtsjukdom. För våra uppgifter är FPR = 0.,195
- True Negative Rate (TNR) eller specificiteten: det är förhållandet mellan de sanna negativen och det faktiska antalet negativ. För vår modell är det åtgärden för hur många fall förutspådde modellen korrekt att patienten inte har hjärtsjukdom från alla patienter som faktiskt inte hade hjärtsjukdom. TNR för ovanstående data = 0.804. Från dessa 2 Definitioner kan vi också dra slutsatsen att specificitet eller TNR = 1-FPR
Vi kan också visualisera Precision och återkallelse med ROC-kurvor och PRC-kurvor.,
Roc-kurvor(mottagarens operativa karaktäristiska kurva):
det är diagrammet mellan TPR(y-axeln) och FPR (x-axeln). Eftersom vår modell klassificerar patienten som att ha hjärtsjukdom eller inte baserat på de sannolikheter som genereras för varje klass, kan vi också bestämma tröskeln för sannolikheterna.
till exempel vill vi ställa in ett tröskelvärde på 0,4. Detta innebär att modellen kommer att klassificera datapoint / patient som har hjärtsjukdom om sannolikheten för att patienten har hjärtsjukdom är större än 0,4., Detta kommer uppenbarligen att ge ett högt återkallningsvärde och minska antalet falska positiva. På samma sätt kan vi visualisera hur vår modell presterar för olika tröskelvärden med ROC-kurvan.
låt oss skapa en Roc-kurva för vår modell med k = 3.
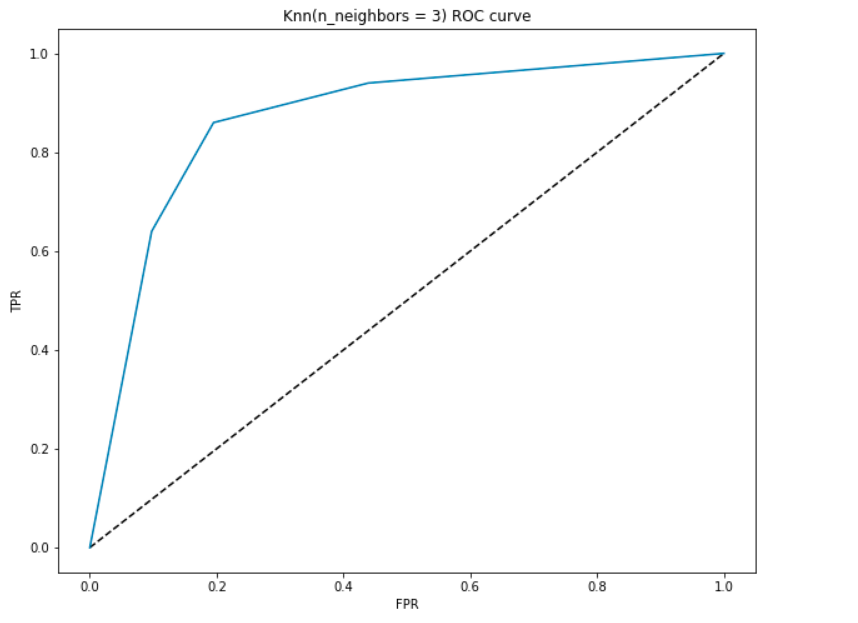
AUC-Tolkning –
- vid den lägsta punkten, dvs. vid (0, 0) – tröskeln är inställd på 1,0. Det betyder att vår modell klassificerar alla patienter som inte har hjärtsjukdom.
- vid den högsta punkten, dvs. vid (1, 1), är tröskeln inställd på 0.0., Det betyder att vår modell klassificerar alla patienter som har hjärtsjukdom.
- resten av kurvan är värdena för FPR och TPR för tröskelvärdena mellan 0 och 1. Vid något tröskelvärde observerar vi att för FPR nära 0 uppnår vi en TPR på nära 1. Detta är när modellen kommer att förutsäga patienter med hjärtsjukdom nästan perfekt.
- området med kurvan och axlarna som gränserna kallas området under kurvan(AUC). Det är detta område som anses vara ett mått på en bra modell., Med denna metriska som sträcker sig från 0 till 1, bör vi sträva efter ett högt värde av AUC. Modeller med hög AUC kallas som modeller med god skicklighet. Låt oss beräkna AUC-poängen för vår modell och ovanstående plot:

- vi får ett värde på 0,868 som AUC vilket är en ganska bra poäng! I enklaste termer betyder det att modellen kommer att kunna skilja patienterna med hjärtsjukdom och de som inte 87% av tiden. Vi kan förbättra denna poäng och jag uppmanar dig att prova olika hyperparameter värden.,
- den diagonala linjen är en slumpmässig modell med en AUC på 0,5, en modell utan skicklighet, vilket precis som att göra en slumpmässig förutsägelse. Kan du gissa varför?
Precision-Recall Curve (PRC)
som namnet antyder är denna kurva en direkt representation av precisionen(y-axeln) och återkallelsen(x-axeln). Om du observerar våra definitioner och formler för precisionen och återkallelsen ovan kommer du att märka att vi inte använder de sanna negativen(det faktiska antalet personer som inte har hjärtsjukdom).,
detta är särskilt användbart för de situationer där vi har en obalanserad dataset och antalet negativ är mycket större än de positiva(eller när antalet patienter som inte har någon hjärtsjukdom är mycket större än de patienter som har det). I sådana fall skulle vår högre oro vara att upptäcka patienterna med hjärtsjukdom så korrekt som möjligt och skulle inte behöva TNR.
liksom ROC plottar vi precisionen och återkallelsen för olika tröskelvärden:
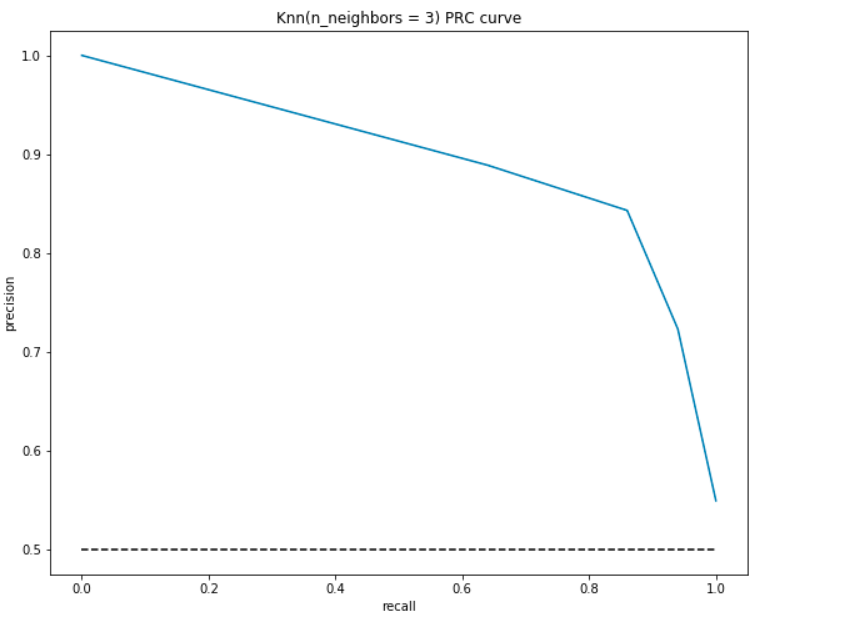
PRC-Tolkning:
- vid den lägsta punkten, dvs., at (0, 0) – tröskeln är inställd på 1,0. Det betyder att vår modell inte gör några skillnader mellan de patienter som har hjärtsjukdom och de patienter som inte gör det.
- vid högsta punkten dvs vid (1, 1) är tröskeln inställd på 0.0. Det betyder att både vår precision och återkallelse är höga och modellen gör distinktioner perfekt.
- resten av kurvan är värdena för Precision och återkallelse för tröskelvärdena mellan 0 och 1. Vårt mål är att göra kurvan så nära (1, 1) som möjligt – vilket innebär en bra precision och återkallelse.,
- liknar ROC, området med kurvan och axlarna som gränserna är området under kurvan(AUC). Betrakta detta område som ett mått på en bra modell. AUC varierar från 0 till 1. Därför bör vi sträva efter ett högt värde av AUC. Låt oss beräkna AUC för vår modell och ovanstående plot:

som tidigare får vi en bra AUC på cirka 90%. Modellen kan också uppnå hög precision med återkallelse som 0 och skulle uppnå en hög återkallelse genom att äventyra precisionen på 50%.,
slutnot
för att avsluta, i den här artikeln såg vi hur man utvärderar en klassificeringsmodell, särskilt fokus på precision och återkallelse, och hitta en balans mellan dem. Vi förklarar också hur vi representerar vår modellprestanda med olika mått och en förvirringsmatris.
här är en ytterligare artikel för dig att förstå utvärderingsmått-11 viktiga Modellutvärderingsmått för maskininlärning alla borde veta